FG-MDM: Towards Zero-Shot Human Motion Generation via Fine-Grained Descriptions
2312.02772
0
0

Abstract
Recently, significant progress has been made in text-based motion generation, enabling the generation of diverse and high-quality human motions that conform to textual descriptions. However, generating motions beyond the distribution of original datasets remains challenging, i.e., zero-shot generation. By adopting a divide-and-conquer strategy, we propose a new framework named Fine-Grained Human Motion Diffusion Model (FG-MDM) for zero-shot human motion generation. Specifically, we first parse previous vague textual annotations into fine-grained descriptions of different body parts by leveraging a large language model. We then use these fine-grained descriptions to guide a transformer-based diffusion model, which further adopts a design of part tokens. FG-MDM can generate human motions beyond the scope of original datasets owing to descriptions that are closer to motion essence. Our experimental results demonstrate the superiority of FG-MDM over previous methods in zero-shot settings. We will release our fine-grained textual annotations for HumanML3D and KIT.
Create account to get full access
Overview
- This paper proposes a method for generating fine-grained human motions using descriptions refined by the ChatGPT language model.
- The approach aims to bridge the gap between high-level language descriptions and detailed animation of human movements.
- The method involves using a pretrained language model to convert text descriptions into more specific, actionable instructions that can then be used to drive a motion generation model.
Plain English Explanation
This research explores a way to create detailed animations of people moving and acting based on textual descriptions. The challenge is that language descriptions are often high-level and lack the specific details needed to drive a realistic animation. To address this, the researchers use a powerful language model called ChatGPT to take the initial text description and refine it into more precise instructions that can be better translated into human motions.
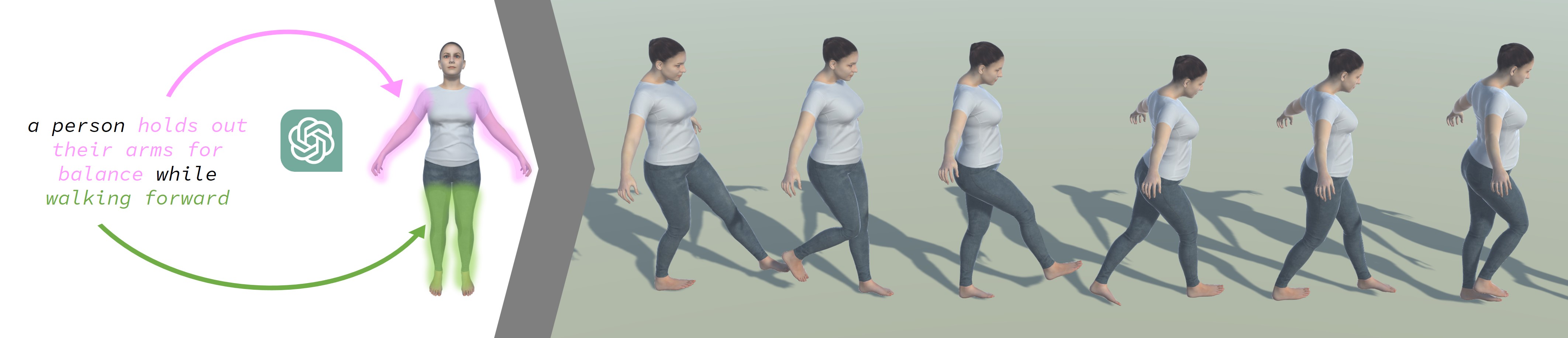
For example, if you started with a description like "The person walked across the room," ChatGPT might expand that into something more detailed like "The person took 10 steps forward, rotating their torso 30 degrees to the right, and swinging their arms in a natural gait as they moved." This refined text can then be more effectively used to generate an animation of the person walking in a realistic, fine-grained way.
The key insight is that leveraging advanced language models like ChatGPT can help bridge the gap between human-centric text and the technical requirements of animation. This opens up new possibilities for creating vivid, customized human motion sequences from simple textual prompts.
Technical Explanation
The paper proposes a method for generating fine-grained human motions using ChatGPT-refined descriptions. The approach involves using a pretrained language model, specifically ChatGPT, to convert high-level textual descriptions of human actions into more detailed, actionable instructions. These refined descriptions are then used to drive a motion generation model, which can produce realistic animations of the described movements.
The researchers first collect a dataset of human motion capture data and corresponding natural language descriptions. They then fine-tune ChatGPT on this dataset, enabling the model to transform coarse text prompts into more granular motion specifications. The refined descriptions are used as input to a motion generation model, which learns to map the detailed instructions to the corresponding animation sequences.
Experiments demonstrate that this approach can produce higher-quality human motion sequences compared to prior methods that rely solely on language-to-animation mappings. The ChatGPT refinement step helps bridge the gap between the abstraction of language and the technical requirements of animation, resulting in more faithful and nuanced motion generation.
Critical Analysis
The paper presents a promising approach for improving the realism and fidelity of human motion generation from textual descriptions. By incorporating a powerful language model like ChatGPT, the method is able to transform high-level prompts into more specific, actionable instructions that can better drive the motion synthesis process.
However, the research also acknowledges several limitations and areas for future work. For example, the current model is trained on a relatively small dataset of motion capture data, which may limit its generalization capabilities. Additionally, the motion generation component is still constrained by the inherent challenges of translating language into complex physical movements.
Further research could explore ways to expand the language understanding and motion generation capabilities of the system, such as by leveraging individual information to generate more personalized human motions or by developing more robust reconstruction techniques for human motion. Integrating the system with co-speech gesture generation or zero-shot grounding of medical phrases could also expand its capabilities and applications.
Overall, this research demonstrates the potential of leveraging advanced language models to enhance the quality and expressiveness of human motion generation from text. As the field continues to evolve, such techniques may unlock new possibilities for seamless human-computer interaction and more natural, human-like animation.
Conclusion
This paper presents a novel approach for generating fine-grained human motions using descriptions refined by the ChatGPT language model. By bridging the gap between high-level language and the technical requirements of animation, the method can produce more realistic and nuanced human motion sequences from textual prompts.
The key innovation is the use of ChatGPT to transform coarse descriptions into detailed, actionable instructions that can be effectively mapped to animation. This enables the system to generate human movements that are more faithful to the original language, opening up new possibilities for applications in areas like virtual environments, interactive characters, and human-computer interaction.
While the current research has some limitations, the findings suggest that continued advancements in language understanding and motion generation could lead to even more sophisticated and expressive human animation driven by natural language. As the field progresses, we may see increasingly seamless integration of human-centric text and highly realistic virtual movements.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
Haowen Sun, Ruikun Zheng, Haibin Huang, Chongyang Ma, Hui Huang, Ruizhen Hu
0
0
In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM
5/7/2024
⚙️
Generating Human Motion in 3D Scenes from Text Descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, Xiaowei Zhou
0
0
Generating human motions from textual descriptions has gained growing research interest due to its wide range of applications. However, only a few works consider human-scene interactions together with text conditions, which is crucial for visual and physical realism. This paper focuses on the task of generating human motions in 3D indoor scenes given text descriptions of the human-scene interactions. This task presents challenges due to the multi-modality nature of text, scene, and motion, as well as the need for spatial reasoning. To address these challenges, we propose a new approach that decomposes the complex problem into two more manageable sub-problems: (1) language grounding of the target object and (2) object-centric motion generation. For language grounding of the target object, we leverage the power of large language models. For motion generation, we design an object-centric scene representation for the generative model to focus on the target object, thereby reducing the scene complexity and facilitating the modeling of the relationship between human motions and the object. Experiments demonstrate the better motion quality of our approach compared to baselines and validate our design choices.
5/14/2024
Towards Open Domain Text-Driven Synthesis of Multi-Person Motions
Mengyi Shan, Lu Dong, Yutao Han, Yuan Yao, Tao Liu, Ifeoma Nwogu, Guo-Jun Qi, Mitch Hill
0
0
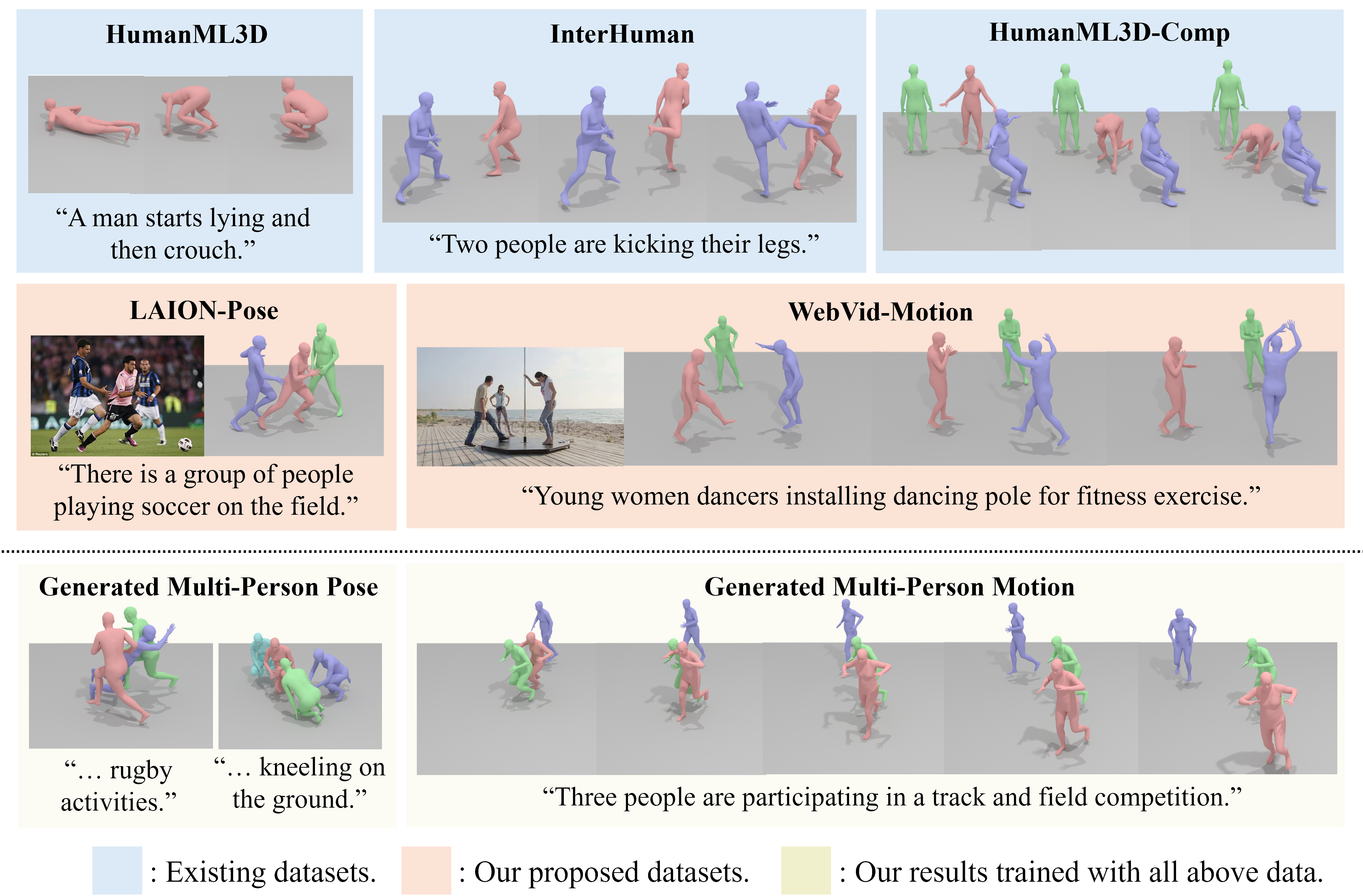
This work aims to generate natural and diverse group motions of multiple humans from textual descriptions. While single-person text-to-motion generation is extensively studied, it remains challenging to synthesize motions for more than one or two subjects from in-the-wild prompts, mainly due to the lack of available datasets. In this work, we curate human pose and motion datasets by estimating pose information from large-scale image and video datasets. Our models use a transformer-based diffusion framework that accommodates multiple datasets with any number of subjects or frames. Experiments explore both generation of multi-person static poses and generation of multi-person motion sequences. To our knowledge, our method is the first to generate multi-subject motion sequences with high diversity and fidelity from a large variety of textual prompts.
5/30/2024

Text-guided 3D Human Motion Generation with Keyframe-based Parallel Skip Transformer
Zichen Geng, Caren Han, Zeeshan Hayder, Jian Liu, Mubarak Shah, Ajmal Mian
0
0
Text-driven human motion generation is an emerging task in animation and humanoid robot design. Existing algorithms directly generate the full sequence which is computationally expensive and prone to errors as it does not pay special attention to key poses, a process that has been the cornerstone of animation for decades. We propose KeyMotion, that generates plausible human motion sequences corresponding to input text by first generating keyframes followed by in-filling. We use a Variational Autoencoder (VAE) with Kullback-Leibler regularization to project the keyframes into a latent space to reduce dimensionality and further accelerate the subsequent diffusion process. For the reverse diffusion, we propose a novel Parallel Skip Transformer that performs cross-modal attention between the keyframe latents and text condition. To complete the motion sequence, we propose a text-guided Transformer designed to perform motion-in-filling, ensuring the preservation of both fidelity and adherence to the physical constraints of human motion. Experiments show that our method achieves state-of-theart results on the HumanML3D dataset outperforming others on all R-precision metrics and MultiModal Distance. KeyMotion also achieves competitive performance on the KIT dataset, achieving the best results on Top3 R-precision, FID, and Diversity metrics.
5/27/2024