LIBRA: Enabling Workload-aware Multi-dimensional Network Topology Optimization for Distributed Training of Large AI Models

0
🌐
Sign in to get full access
Overview
- As machine learning models continue to grow in size, distributed training is necessary to accommodate the model weights and reduce training time.
- However, distributed training introduces increased communication overhead due to the exchange of gradients and activations, which can become a critical bottleneck.
- This work explores the design of multi-dimensional networks as a cost-efficient mechanism to enhance overall network bandwidth and enable efficient resource utilization.
Plain English Explanation
As machine learning models become larger, they require more computing power and memory to train. To handle these massive models, researchers often use distributed training, which splits the model across multiple devices. This allows the model to be trained more quickly, but it also means the devices have to constantly communicate with each other to share information, like the gradients (the changes needed to update the model) and activations (the outputs from each layer).
All this communication can become a bottleneck, slowing down the overall training process. The researchers in this work propose using multi-dimensional networks as a way to increase the available bandwidth and improve the efficiency of this communication. Essentially, they're trying to create a more efficient "highway system" for the data flowing between the training devices.
Additionally, the researchers highlight that optimizing the allocation of this increased bandwidth is crucial for ensuring the multi-dimensional networks are used effectively. They introduce a framework called LIBRA to help with this optimization process.
Technical Explanation
The researchers identify that as model sizes in machine learning continue to scale, distributed training is necessary to accommodate model weights within each device and to reduce training time. However, this comes with the expense of increased communication overhead due to the exchange of gradients and activations, which become the critical bottleneck of the end-to-end training process.
To address this, the researchers motivate the design of multi-dimensional networks within machine learning systems as a cost-efficient mechanism to enhance overall network bandwidth. They also identify that optimal bandwidth allocation is pivotal for multi-dimensional networks to ensure efficient resource utilization.
The researchers introduce LIBRA, a framework specifically focused on optimizing multi-dimensional fabric architectures. Through case studies, they demonstrate the value of LIBRA, both in architecting optimized fabrics under diverse constraints and in enabling co-optimization opportunities.
Critical Analysis
The paper introduces an interesting approach to addressing the communication bottleneck in distributed training by leveraging multi-dimensional network architectures. However, the authors do not provide a comprehensive evaluation of the limitations or potential drawbacks of their LIBRA framework.
For example, the paper does not discuss the computational overhead or additional complexity introduced by the optimization process within LIBRA. There may be tradeoffs between the benefits of improved communication efficiency and the costs of the optimization itself that should be further explored.
Additionally, the paper focuses on the architectural and bandwidth allocation aspects, but does not delve into the potential implications of this approach on other important factors, such as energy efficiency or the ability to balance workloads across the distributed system. These are important considerations that could influence the real-world applicability and adoption of the proposed techniques.
Overall, the research presents a promising direction, but further investigation into the practical limitations and holistic system-level impacts would help provide a more well-rounded understanding of the proposed approach.
Conclusion
This work highlights the importance of addressing the communication bottleneck in distributed machine learning training by introducing a framework called LIBRA that optimizes multi-dimensional network architectures. The key idea is to leverage the increased bandwidth and efficient resource utilization of these multi-dimensional fabrics to improve the overall training process.
While the research demonstrates the potential value of this approach through case studies, further exploration of the limitations, tradeoffs, and system-level implications would be beneficial to fully assess the merits and applicability of the LIBRA framework. Nonetheless, the work contributes to the ongoing efforts to enable the scalable and efficient training of increasingly complex machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
LIBRA: Enabling Workload-aware Multi-dimensional Network Topology Optimization for Distributed Training of Large AI Models
William Won, Saeed Rashidi, Sudarshan Srinivasan, Tushar Krishna
As model sizes in machine learning continue to scale, distributed training is necessary to accommodate model weights within each device and to reduce training time. However, this comes with the expense of increased communication overhead due to the exchange of gradients and activations, which become the critical bottleneck of the end-to-end training process. In this work, we motivate the design of multi-dimensional networks within machine learning systems as a cost-efficient mechanism to enhance overall network bandwidth. We also identify that optimal bandwidth allocation is pivotal for multi-dimensional networks to ensure efficient resource utilization. We introduce LIBRA, a framework specifically focused on optimizing multi-dimensional fabric architectures. Through case studies, we demonstrate the value of LIBRA, both in architecting optimized fabrics under diverse constraints and in enabling co-optimization opportunities.
Read more5/7/2024

0
Performance Modeling and Workload Analysis of Distributed Large Language Model Training and Inference
Joyjit Kundu, Wenzhe Guo, Ali BanaGozar, Udari De Alwis, Sourav Sengupta, Puneet Gupta, Arindam Mallik
Aligning future system design with the ever-increasing compute needs of large language models (LLMs) is undoubtedly an important problem in today's world. Here, we propose a general performance modeling methodology and workload analysis of distributed LLM training and inference through an analytical framework that accurately considers compute, memory sub-system, network, and various parallelization strategies (model parallel, data parallel, pipeline parallel, and sequence parallel). We validate our performance predictions with published data from literature and relevant industry vendors (e.g., NVIDIA). For distributed training, we investigate the memory footprint of LLMs for different activation re-computation methods, dissect the key factors behind the massive performance gain from A100 to B200 ($sim$ 35x speed-up closely following NVIDIA's scaling trend), and further run a design space exploration at different technology nodes (12 nm to 1 nm) to study the impact of logic, memory, and network scaling on the performance. For inference, we analyze the compute versus memory boundedness of different operations at a matrix-multiply level for different GPU systems and further explore the impact of DRAM memory technology scaling on inference latency. Utilizing our modeling framework, we reveal the evolution of performance bottlenecks for both LLM training and inference with technology scaling, thus, providing insights to design future systems for LLM training and inference.
Read more7/23/2024
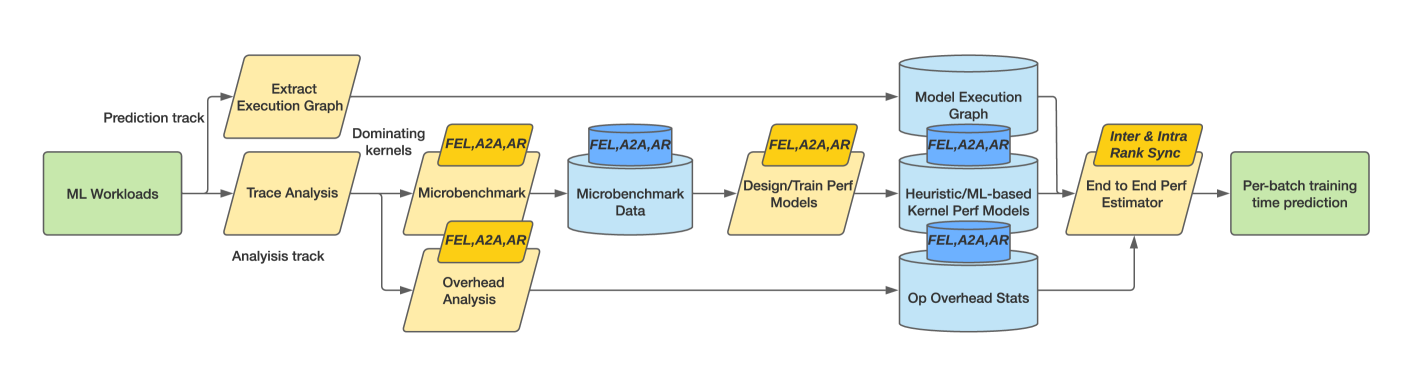
0
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Read more4/30/2024

0
Communication Optimization for Distributed Training: Architecture, Advances, and Opportunities
Yunze Wei, Tianshuo Hu, Cong Liang, Yong Cui
The past few years have witnessed the flourishing of large-scale deep neural network models with ever-growing parameter numbers. Training such large-scale models typically requires massive memory and computing resources, necessitating distributed training. As GPU performance has rapidly evolved in recent years, computation time has shrunk, making communication a larger portion of the overall training time. Consequently, optimizing communication for distributed training has become crucial. In this article, we briefly introduce the general architecture of distributed deep neural network training and analyze relationships among Parallelization Strategy, Collective Communication Library, and Network from the perspective of communication optimization, which forms a three-layer paradigm. We then review current representative research advances within this three-layer paradigm. We find that layers in the current three-layer paradigm are relatively independent and there is a rich design space for cross-layer collaborative optimization in distributed training scenarios. Therefore, we advocate Vertical and Horizontal co-designs which extend the three-layer paradigm to a five-layer paradigm. We also advocate Intra-Inter and Host-Net co-designs to further utilize the potential of heterogeneous resources. We hope this article can shed some light on future research on communication optimization for distributed training.
Read more8/30/2024