TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Devices
2404.03574
0
0
Abstract
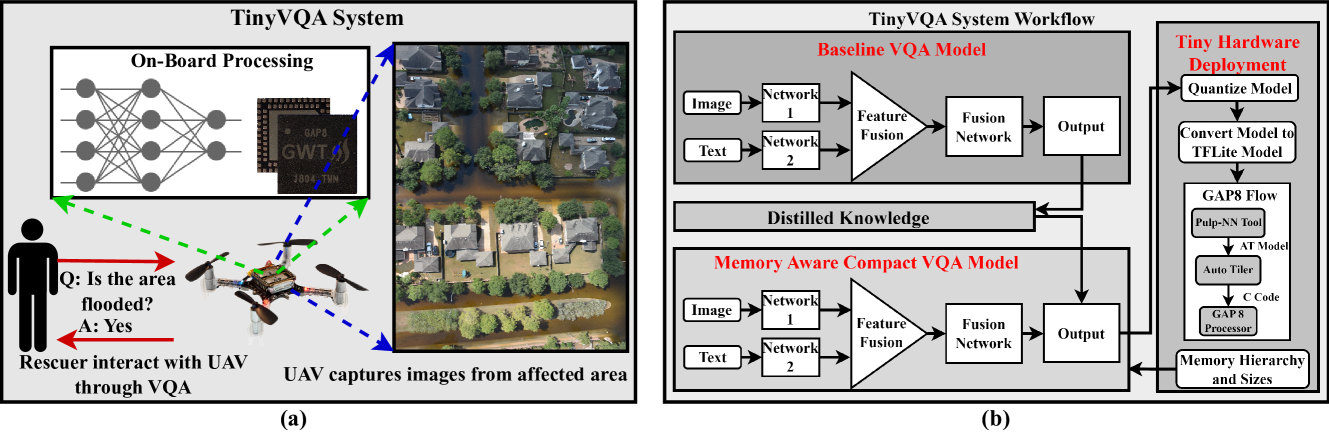
Traditional machine learning models often require powerful hardware, making them unsuitable for deployment on resource-limited devices. Tiny Machine Learning (tinyML) has emerged as a promising approach for running machine learning models on these devices, but integrating multiple data modalities into tinyML models still remains a challenge due to increased complexity, latency, and power consumption. This paper proposes TinyVQA, a novel multimodal deep neural network for visual question answering tasks that can be deployed on resource-constrained tinyML hardware. TinyVQA leverages a supervised attention-based model to learn how to answer questions about images using both vision and language modalities. Distilled knowledge from the supervised attention-based VQA model trains the memory aware compact TinyVQA model and low bit-width quantization technique is employed to further compress the model for deployment on tinyML devices. The TinyVQA model was evaluated on the FloodNet dataset, which is used for post-disaster damage assessment. The compact model achieved an accuracy of 79.5%, demonstrating the effectiveness of TinyVQA for real-world applications. Additionally, the model was deployed on a Crazyflie 2.0 drone, equipped with an AI deck and GAP8 microprocessor. The TinyVQA model achieved low latencies of 56 ms and consumes 693 mW power while deployed on the tiny drone, showcasing its suitability for resource-constrained embedded systems.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes a compact multimodal deep neural network called TinyVQA for visual question answering on resource-constrained hardware
- Focuses on developing a lightweight model that can run efficiently on devices with limited memory and computational power
- Demonstrates the model's performance on the VQAv2 dataset and its ability to run on the Gap8 low-power processor
Plain English Explanation
TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Hardware is a research paper that presents a new deep learning model for answering questions about images. The key innovation is that the model is designed to be very compact and efficient, so it can run on devices with limited memory and processing power, like low-cost smartphones or embedded systems.
The researchers recognized that many existing visual question answering (VQA) models are too large and complex to be used on resource-constrained hardware. So they set out to create a more lightweight model, called TinyVQA, that could still perform well on VQA tasks. The model uses a combination of techniques, like quantizing the model parameters and minimizing the network architecture, to reduce the overall size and computational requirements.
The researchers tested TinyVQA on the popular VQAv2 dataset and found that it achieves competitive performance compared to larger, more complex models. They also demonstrated that the model can run efficiently on the Gap8 low-power processor, which has very limited memory and processing capabilities.
Technical Explanation
TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Hardware presents a novel deep learning architecture for visual question answering (VQA) that is designed to be highly compact and efficient, allowing it to run on resource-constrained hardware.
The key components of the TinyVQA model include:
- Multimodal Encoding: The model takes in both an image and a question as input and uses a series of convolutional and recurrent layers to encode the visual and textual information, respectively.
- Multimodal Fusion: The encoded visual and textual features are then fused using a compact multimodal fusion module, which combines the information from both modalities.
- Lightweight Classification Head: The fused features are passed through a lightweight classification head to predict the answer to the question.
To achieve the desired level of compactness and efficiency, the researchers employed several optimization techniques, including:
- Quantization of model parameters to reduce the overall model size
- Architectural design choices to minimize the number of parameters and computations
- [Training the model on a device with limited memory to ensure it can run on resource-constrained hardware
The researchers evaluated the performance of TinyVQA on the VQAv2 dataset and demonstrated that it achieves competitive results compared to larger, more complex VQA models. They also showed that the model can be efficiently deployed on the Gap8 low-power processor, which has very limited memory and computational resources.
Critical Analysis
The researchers have made a significant contribution by developing a compact and efficient multimodal deep neural network for visual question answering. The focus on resource-constrained hardware is particularly important, as it opens up the possibility of deploying VQA systems on a wider range of devices, including low-cost smartphones and embedded systems.
However, the paper does not address some potential limitations of the TinyVQA model. For example, it would be interesting to see how the model's performance compares to larger, more complex VQA models on more challenging datasets or in real-world applications. Additionally, the paper does not discuss the model's robustness to noisy or adversarial inputs, which is an important consideration for real-world deployments.
Furthermore, the researchers could have provided more details on the specific architectural choices and optimization techniques used to achieve the desired level of compactness and efficiency. This information would be valuable for researchers and engineers looking to develop similar lightweight models for other multimodal tasks.
Overall, the TinyVQA model represents an exciting step forward in the development of efficient and deployable multimodal deep learning systems. However, there is still room for further research and development to address the potential limitations and expand the capabilities of these types of models.
Conclusion
TinyVQA: Compact Multimodal Deep Neural Network for Visual Question Answering on Resource-Constrained Hardware presents a novel deep learning architecture for visual question answering that is designed to be highly compact and efficient, enabling it to run on resource-constrained hardware. The key innovations include the use of multimodal encoding and fusion techniques, along with various optimization methods such as quantization and architectural design choices.
The researchers have demonstrated that the TinyVQA model can achieve competitive performance on the VQAv2 dataset while running efficiently on the Gap8 low-power processor, which has very limited memory and computational resources. This work has significant implications for the deployment of VQA systems on a wide range of devices, from low-cost smartphones to embedded systems, opening up new possibilities for real-world applications of multimodal deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Zhengqing Yuan, Zhaoxu Li, Weiran Huang, Yanfang Ye, Lichao Sun
0
0
In recent years, multimodal large language models (MLLMs) such as GPT-4V have demonstrated remarkable advancements, excelling in a variety of vision-language tasks. Despite their prowess, the closed-source nature and computational demands of such models limit their accessibility and applicability. This study introduces TinyGPT-V, a novel open-source MLLM, designed for efficient training and inference across various vision-language tasks, including image captioning (IC) and visual question answering (VQA). Leveraging a compact yet powerful architecture, TinyGPT-V integrates the Phi-2 language model with pre-trained vision encoders, utilizing a unique mapping module for visual and linguistic information fusion. With a training regimen optimized for small backbones and employing a diverse dataset amalgam, TinyGPT-V requires significantly lower computational resources 24GB for training and as little as 8GB for inference without compromising on performance. Our experiments demonstrate that TinyGPT-V, with its language model 2.8 billion parameters, achieves comparable results in VQA and image inference tasks to its larger counterparts while being uniquely suited for deployment on resource-constrained devices through innovative quantization techniques. This work not only paves the way for more accessible and efficient MLLMs but also underscores the potential of smaller, optimized models in bridging the gap between high performance and computational efficiency in real-world applications. Additionally, this paper introduces a new approach to multimodal large language models using smaller backbones. Our code and training weights are available in url{https://github.com/DLYuanGod/TinyGPT-V}.
4/8/2024
Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
Tongkun Su, Jun Li, Xi Zhang, Haibo Jin, Hao Chen, Qiong Wang, Faqin Lv, Baoliang Zhao, Yin Hu
0
0
Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.
4/9/2024
Lightweight Deep Learning for Resource-Constrained Environments: A Survey
Hou-I Liu, Marco Galindo, Hongxia Xie, Lai-Kuan Wong, Hong-Han Shuai, Yung-Hui Li, Wen-Huang Cheng
0
0
Over the past decade, the dominance of deep learning has prevailed across various domains of artificial intelligence, including natural language processing, computer vision, and biomedical signal processing. While there have been remarkable improvements in model accuracy, deploying these models on lightweight devices, such as mobile phones and microcontrollers, is constrained by limited resources. In this survey, we provide comprehensive design guidance tailored for these devices, detailing the meticulous design of lightweight models, compression methods, and hardware acceleration strategies. The principal goal of this work is to explore methods and concepts for getting around hardware constraints without compromising the model's accuracy. Additionally, we explore two notable paths for lightweight deep learning in the future: deployment techniques for TinyML and Large Language Models. Although these paths undoubtedly have potential, they also present significant challenges, encouraging research into unexplored areas.
4/15/2024
Exploring Diverse Methods in Visual Question Answering
Panfeng Li, Qikai Yang, Xieming Geng, Wenjing Zhou, Zhicheng Ding, Yi Nian
0
0
This study explores innovative methods for improving Visual Question Answering (VQA) using Generative Adversarial Networks (GANs), autoencoders, and attention mechanisms. Leveraging a balanced VQA dataset, we investigate three distinct strategies. Firstly, GAN-based approaches aim to generate answer embeddings conditioned on image and question inputs, showing potential but struggling with more complex tasks. Secondly, autoencoder-based techniques focus on learning optimal embeddings for questions and images, achieving comparable results with GAN due to better ability on complex questions. Lastly, attention mechanisms, incorporating Multimodal Compact Bilinear pooling (MCB), address language priors and attention modeling, albeit with a complexity-performance trade-off. This study underscores the challenges and opportunities in VQA and suggests avenues for future research, including alternative GAN formulations and attentional mechanisms.
4/23/2024