Low-Resource Vision Challenges for Foundation Models
2401.04716
0
0
👀
Abstract
Low-resource settings are well-established in natural language processing, where many languages lack sufficient data for deep learning at scale. However, low-resource problems are under-explored in computer vision. In this paper, we address this gap and explore the challenges of low-resource image tasks with vision foundation models. We first collect a benchmark of genuinely low-resource image data, covering historic maps, circuit diagrams, and mechanical drawings. These low-resource settings all share three challenges: data scarcity, fine-grained differences, and the distribution shift from natural images to the specialized domain of interest. While existing foundation models have shown impressive generalizability, we find they cannot transfer well to our low-resource tasks. To begin to tackle the challenges of low-resource vision, we introduce one simple baseline per challenge. Specifically, we i) enlarge the data space by generative models, ii) adopt the best sub-kernels to encode local regions for fine-grained difference discovery and iii) learn attention for specialized domains. Experiments on our three low-resource tasks demonstrate our proposals already provide a better baseline than transfer learning, data augmentation, and fine-grained methods. This highlights the unique characteristics and challenges of low-resource vision for foundation models that warrant further investigation. Project page: https://xiaobai1217.github.io/Low-Resource-Vision/.
Create account to get full access
Overview
- The paper addresses the challenge of low-resource computer vision tasks, where there is limited data available for training deep learning models.
- It collects a benchmark of genuinely low-resource image data, including historical maps, circuit diagrams, and mechanical drawings.
- The paper identifies three key challenges in low-resource vision: data scarcity, fine-grained differences, and distribution shift from natural images.
- Existing foundation models struggle to transfer well to these low-resource tasks, so the paper introduces simple baselines to tackle each of the identified challenges.
Plain English Explanation
While low-resource settings are well-established in natural language processing, the same is not true for computer vision. This paper explores the challenges of low-resource image tasks, where there is not enough data to train deep learning models effectively.
The researchers first gathered a collection of genuinely low-resource image data, including historical maps, circuit diagrams, and mechanical drawings. These types of specialized images pose three key problems for computer vision:
- Data Scarcity: There is not enough data available to train powerful deep learning models.
- Fine-Grained Differences: The images contain subtle, detailed differences that are important to detect, but can be difficult for models to learn.
- Distribution Shift: The images are very different from the natural photographs that most vision models are trained on, so the models struggle to generalize.
The paper shows that even the latest foundation models - powerful AI models trained on vast amounts of data - have trouble performing well on these low-resource vision tasks.
To begin addressing these challenges, the researchers propose some simple baseline approaches:
- Enlarge the Data Space: Use generative models to create more diverse training data.
- Encode Local Regions: Adopt specialized kernels that can better capture the fine-grained differences in the images.
- Learn Attention for Specialized Domains: Teach the models to focus on the most important parts of the images, which may differ from natural photographs.
These basic techniques already outperform simply using transfer learning or data augmentation, highlighting the unique challenges of low-resource vision that require further research.
Technical Explanation
The paper starts by collecting a benchmark of genuinely low-resource image data, covering three specialized domains: historical maps, circuit diagrams, and mechanical drawings. These datasets share three key challenges for computer vision models:
- Data Scarcity: There is simply not enough labeled data available to train powerful deep learning models from scratch.
- Fine-Grained Differences: The images contain subtle, detailed differences that are important to detect, but can be difficult for models to learn.
- Distribution Shift: The images are very different from the natural photographs that most vision models are trained on, so the models struggle to generalize.
To assess the performance of existing approaches, the researchers evaluate transfer learning and data augmentation on these low-resource tasks. They find that even the latest foundation models struggle to transfer effectively.
To begin addressing these challenges, the paper introduces one simple baseline per challenge:
- Enlarging the Data Space: The researchers use generative models to create more diverse synthetic training data.
- Encoding Local Regions: They adopt specialized convolutional kernels that can better capture the fine-grained differences in the images.
- Learning Attention for Specialized Domains: The models are trained to focus on the most important parts of the images, which may differ from natural photographs.
Experiments on the three low-resource tasks show that these basic techniques already outperform standard transfer learning and data augmentation approaches. This highlights the unique characteristics and challenges of low-resource vision for foundation models that warrant further investigation.
Critical Analysis
The paper identifies an important gap in the field of computer vision, where the challenges of low-resource settings have been largely overlooked compared to natural language processing. By collecting a benchmark of genuinely low-resource image data, the researchers have provided a valuable resource for the community to further explore this area.
The three key challenges outlined in the paper - data scarcity, fine-grained differences, and distribution shift - are well-justified and seem to capture the core issues faced in these low-resource vision tasks. The simple baselines introduced, while not comprehensive solutions, demonstrate the unique nature of these problems and the need for more specialized approaches beyond standard transfer learning and data augmentation.
However, the paper does not delve into the limitations of the proposed baselines or discuss potential drawbacks. For example, the use of generative models to enlarge the data space may introduce artifacts or biases that could negatively impact model performance. Additionally, the attention-based approach to focusing on specialized domains could be prone to overfitting or may require careful regularization.
Further research is needed to build upon these initial findings and develop more robust, scalable solutions for low-resource computer vision tasks. Exploring the synergies between vision and language models, as well as investigating more advanced techniques like meta-learning or few-shot learning, could yield promising avenues for future work in this area.
Overall, this paper serves as an important call to action for the computer vision community to devote more attention to the unique challenges of low-resource settings, which are likely to become increasingly relevant as AI systems are deployed in a wider range of real-world scenarios with limited data.
Conclusion
This paper highlights the underexplored challenge of low-resource computer vision tasks, where the limited availability of training data poses significant challenges for deep learning models. By collecting a benchmark of genuinely low-resource image data, the researchers have identified three key problems: data scarcity, fine-grained differences, and distribution shift from natural images.
The paper shows that even state-of-the-art foundation models struggle to transfer effectively to these low-resource vision tasks. To begin addressing this gap, the researchers introduce simple baselines targeting each of the identified challenges: using generative models to enlarge the data space, adopting specialized convolutional kernels to better encode fine-grained details, and learning attention mechanisms for specialized domains.
While these initial techniques already outperform standard transfer learning and data augmentation approaches, the paper highlights the unique characteristics and substantial challenges of low-resource vision that warrant further investigation. Continued research in this area could lead to significant advancements in making computer vision more accessible and applicable in a wider range of real-world scenarios with limited data resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
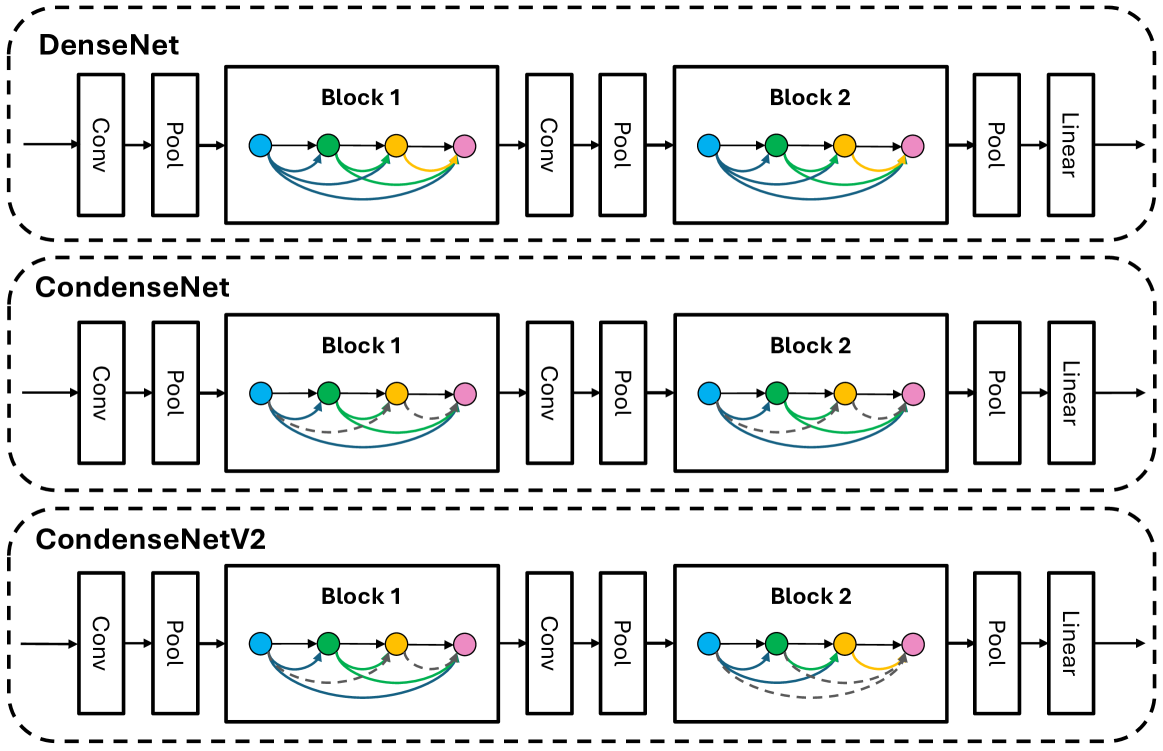
Lightweight Deep Learning for Resource-Constrained Environments: A Survey
Hou-I Liu, Marco Galindo, Hongxia Xie, Lai-Kuan Wong, Hong-Han Shuai, Yung-Hui Li, Wen-Huang Cheng
0
0
Over the past decade, the dominance of deep learning has prevailed across various domains of artificial intelligence, including natural language processing, computer vision, and biomedical signal processing. While there have been remarkable improvements in model accuracy, deploying these models on lightweight devices, such as mobile phones and microcontrollers, is constrained by limited resources. In this survey, we provide comprehensive design guidance tailored for these devices, detailing the meticulous design of lightweight models, compression methods, and hardware acceleration strategies. The principal goal of this work is to explore methods and concepts for getting around hardware constraints without compromising the model's accuracy. Additionally, we explore two notable paths for lightweight deep learning in the future: deployment techniques for TinyML and Large Language Models. Although these paths undoubtedly have potential, they also present significant challenges, encouraging research into unexplored areas.
4/15/2024
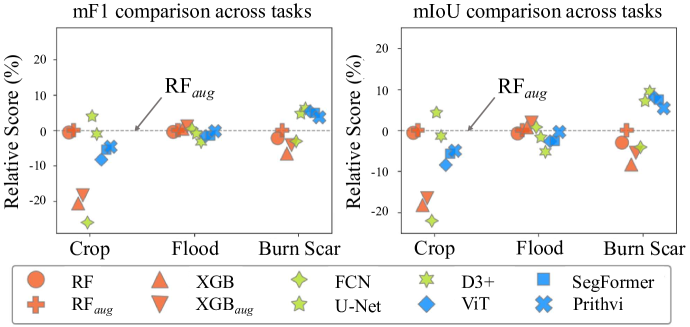
When are Foundation Models Effective? Understanding the Suitability for Pixel-Level Classification Using Multispectral Imagery
Yiqun Xie, Zhihao Wang, Weiye Chen, Zhili Li, Xiaowei Jia, Yanhua Li, Ruichen Wang, Kangyang Chai, Ruohan Li, Sergii Skakun
0
0
Foundation models, i.e., very large deep learning models, have demonstrated impressive performances in various language and vision tasks that are otherwise difficult to reach using smaller-size models. The major success of GPT-type of language models is particularly exciting and raises expectations on the potential of foundation models in other domains including satellite remote sensing. In this context, great efforts have been made to build foundation models to test their capabilities in broader applications, and examples include Prithvi by NASA-IBM, Segment-Anything-Model, ViT, etc. This leads to an important question: Are foundation models always a suitable choice for different remote sensing tasks, and when or when not? This work aims to enhance the understanding of the status and suitability of foundation models for pixel-level classification using multispectral imagery at moderate resolution, through comparisons with traditional machine learning (ML) and regular-size deep learning models. Interestingly, the results reveal that in many scenarios traditional ML models still have similar or better performance compared to foundation models, especially for tasks where texture is less useful for classification. On the other hand, deep learning models did show more promising results for tasks where labels partially depend on texture (e.g., burn scar), while the difference in performance between foundation models and deep learning models is not obvious. The results conform with our analysis: The suitability of foundation models depend on the alignment between the self-supervised learning tasks and the real downstream tasks, and the typical masked autoencoder paradigm is not necessarily suitable for many remote sensing problems.
4/19/2024
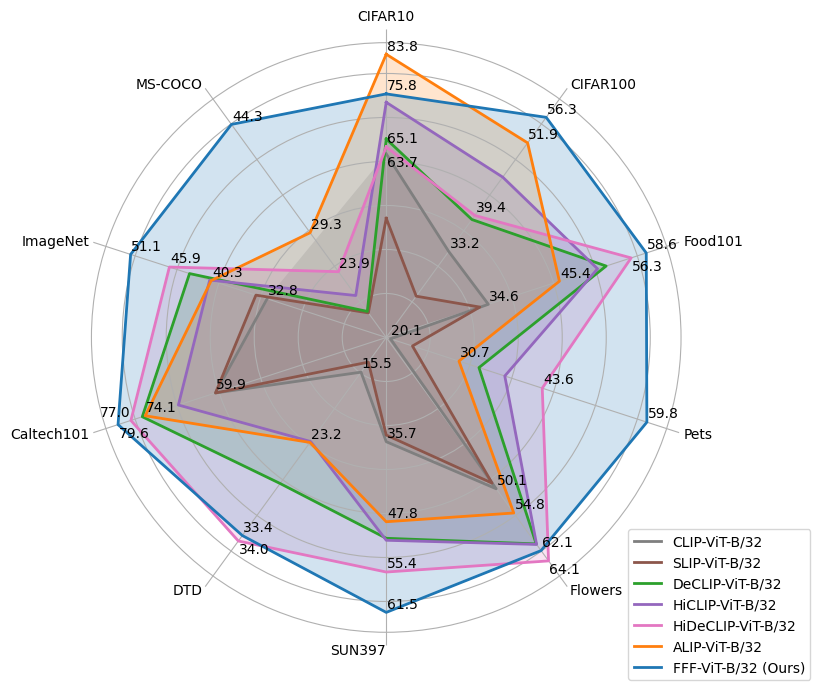
FFF: Fixing Flawed Foundations in contrastive pre-training results in very strong Vision-Language models
Adrian Bulat, Yassine Ouali, Georgios Tzimiropoulos
0
0
Despite noise and caption quality having been acknowledged as important factors impacting vision-language contrastive pre-training, in this paper, we show that the full potential of improving the training process by addressing such issues is yet to be realized. Specifically, we firstly study and analyze two issues affecting training: incorrect assignment of negative pairs, and low caption quality and diversity. Then, we devise effective solutions for addressing both problems, which essentially require training with multiple true positive pairs. Finally, we propose training with sigmoid loss to address such a requirement. We show very large gains over the current state-of-the-art for both image recognition ($sim +6%$ on average over 11 datasets) and image retrieval ($sim +19%$ on Flickr30k and $sim +15%$ on MSCOCO).
5/17/2024
⛏️
Overcoming Generic Knowledge Loss with Selective Parameter Update
Wenxuan Zhang, Paul Janson, Rahaf Aljundi, Mohamed Elhoseiny
0
0
Foundation models encompass an extensive knowledge base and offer remarkable transferability. However, this knowledge becomes outdated or insufficient over time. The challenge lies in continuously updating foundation models to accommodate novel information while retaining their original capabilities. Leveraging the fact that foundation models have initial knowledge on various tasks and domains, we propose a novel approach that, instead of updating all parameters equally, localizes the updates to a sparse set of parameters relevant to the task being learned. We strike a balance between efficiency and new task performance, while maintaining the transferability and generalizability of foundation models. We extensively evaluate our method on foundational vision-language models with a diverse spectrum of continual learning tasks. Our method achieves improvements on the accuracy of the newly learned tasks up to 7% while preserving the pretraining knowledge with a negligible decrease of 0.9% on a representative control set accuracy.
4/22/2024