MegaFusion: Extend Diffusion Models towards Higher-resolution Image Generation without Further Tuning

0
Sign in to get full access
Overview
- MegaFusion is a method to extend diffusion models towards higher-resolution image generation without further training.
- It leverages a hierarchical architecture and a novel fusion mechanism to generate high-quality, high-resolution images.
- The approach can be used as a plug-and-play module with existing diffusion models.
Plain English Explanation
MegaFusion is a technique that allows diffusion models, which are powerful machine learning models for generating images, to create much higher-resolution images without needing to be retrained.
Diffusion models work by gradually adding noise to an image until it's completely scrambled, and then learning to reverse that process to generate new images. However, these models are typically limited in the resolution of the images they can produce.
MegaFusion solves this by using a special architecture that breaks the image generation process into multiple stages. It starts with a low-resolution version of the image and progressively refines it to create a high-resolution final output. This "hierarchical" approach allows the model to efficiently generate detailed, high-quality images.
Additionally, MegaFusion introduces a novel "fusion" mechanism that helps the different stages of the model work together seamlessly. This fusion process allows the low-resolution and high-resolution parts of the model to share information and produce better results.
The key advantage of MegaFusion is that it can be used as a plug-and-play module with existing diffusion models, without requiring any further training of the original model. This makes it a flexible and efficient way to extend the capabilities of diffusion models to generate higher-resolution images.
Technical Explanation
MegaFusion is a hierarchical architecture that extends the capabilities of diffusion models to generate higher-resolution images without further training. The approach consists of a coarse-to-fine generation process, where a low-resolution image is first generated and then progressively refined to produce the final high-resolution output.
The core components of MegaFusion include:
-
Hierarchical Architecture: The model is composed of multiple stages, each responsible for generating a progressively higher-resolution version of the image. This allows the model to efficiently focus on different levels of detail.
-
Fusion Mechanism: MegaFusion introduces a novel fusion mechanism that enables the different stages of the model to share information and collaborate effectively. This fusion process helps the model to generate coherent and high-quality high-resolution images.
-
Plug-and-Play Capability: The MegaFusion module can be easily integrated with existing diffusion models without the need for further training. This makes it a flexible and efficient way to extend the capabilities of these models.
The authors evaluate MegaFusion on several benchmark datasets and demonstrate its ability to generate high-resolution images with improved visual quality compared to previous methods. The experiments also show that MegaFusion can be applied to various diffusion models, highlighting its versatility and broad applicability.
Critical Analysis
The MegaFusion paper presents a promising approach for extending the capabilities of diffusion models to generate higher-resolution images without further training. The hierarchical architecture and fusion mechanism seem to be effective in producing detailed, high-quality outputs.
One potential limitation of the approach is that it may still require a significant amount of computational resources, especially for generating very high-resolution images. The authors do not provide extensive information on the model's inference time or memory requirements, which could be important considerations for real-world applications.
Additionally, the paper does not explore the limitations of MegaFusion in terms of the types of images it can generate or the level of control over the output that it provides. It would be valuable to see how the method performs on more diverse datasets and task-specific requirements.
Furthermore, the authors could have delved deeper into the inner workings of the fusion mechanism and its role in enabling the effective collaboration between the different stages of the model. A more thorough analysis of this key component could provide valuable insights for future research in this area.
Overall, the MegaFusion paper presents an interesting and potentially impactful approach for enhancing the capabilities of diffusion models. However, further research and analysis would be beneficial to fully understand the method's strengths, limitations, and potential applications.
Conclusion
MegaFusion is a novel technique that extends the capabilities of diffusion models to generate higher-resolution images without the need for further training. By leveraging a hierarchical architecture and a novel fusion mechanism, MegaFusion can produce detailed, high-quality outputs while maintaining the flexibility and efficiency of a plug-and-play module.
This approach has the potential to significantly expand the practical applications of diffusion models, enabling them to tackle tasks that require higher-resolution image generation. The research presented in this paper represents an important step forward in the field of generative modeling, and the insights gained from MegaFusion could inspire further advancements in this area.
As the field of machine learning continues to evolve, methods like MegaFusion that can enhance the capabilities of existing models without extensive retraining will become increasingly valuable. The ability to efficiently generate high-resolution images has numerous applications, from creative endeavors to scientific visualizations, and the MegaFusion technique could be a valuable tool in unlocking new possibilities in these domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MegaFusion: Extend Diffusion Models towards Higher-resolution Image Generation without Further Tuning
Haoning Wu, Shaocheng Shen, Qiang Hu, Xiaoyun Zhang, Ya Zhang, Yanfeng Wang
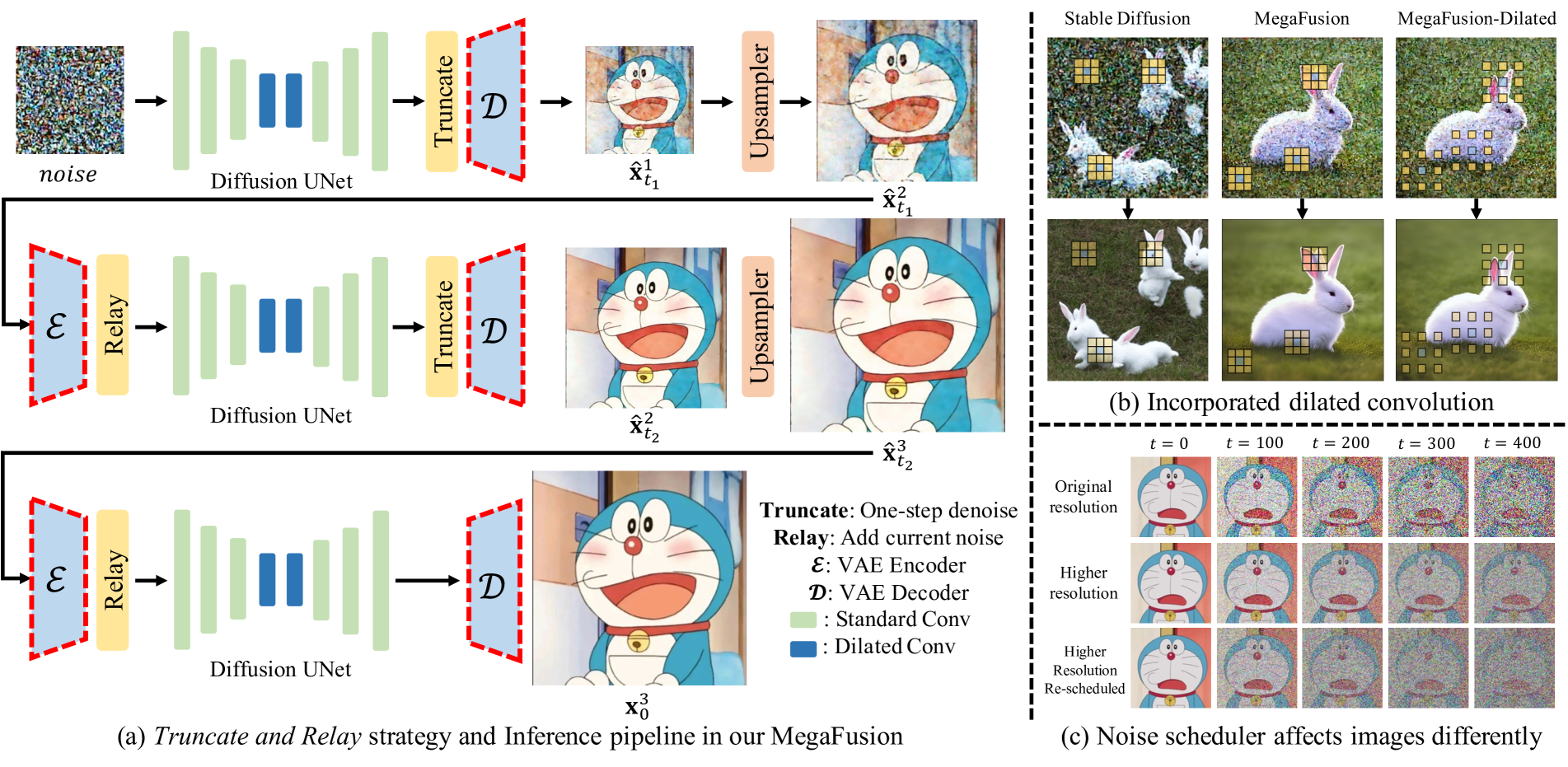
Diffusion models have emerged as frontrunners in text-to-image generation, however, their fixed image resolution during training often leads to challenges in high-resolution image generation, such as semantic deviations and object replication. This paper introduces MegaFusion, a novel approach that extends existing diffusion-based text-to-image generation models towards efficient higher-resolution generation without additional fine-tuning or extra adaptation. Specifically, we employ an innovative truncate and relay strategy to bridge the denoising processes across different resolutions, allowing for high-resolution image generation in a coarse-to-fine manner. Moreover, by integrating dilated convolutions and noise re-scheduling, we further adapt the model's priors for higher resolution. The versatility and efficacy of MegaFusion make it universally applicable to both latent-space and pixel-space diffusion models, along with other derivative models. Extensive experiments confirm that MegaFusion significantly boosts the capability of existing models to produce images of megapixels and various aspect ratios, while only requiring about 40% of the original computational cost.
Read more9/10/2024

0
DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Junyu Zhang, Eunbyung Park
Large-scale generative models, such as text-to-image diffusion models, have garnered widespread attention across diverse domains due to their creative and high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generating images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher-resolution datasets. However, this poses a formidable challenge due to the difficulty in collecting large-scale high-resolution images and substantial computational resources. While several preceding works have proposed alternatives to bypass the cumbersome training process, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond their original capability and propose a novel progressive approach that fully utilizes generated low-resolution images to guide the generation of higher-resolution images. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method. Project page: https://yhyun225.github.io/DiffuseHigh/
Read more8/28/2024
↗️
0
HiDiffusion: Unlocking Higher-Resolution Creativity and Efficiency in Pretrained Diffusion Models
Shen Zhang, Zhaowei Chen, Zhenyu Zhao, Yuhao Chen, Yao Tang, Jiajun Liang
Diffusion models have become a mainstream approach for high-resolution image synthesis. However, directly generating higher-resolution images from pretrained diffusion models will encounter unreasonable object duplication and exponentially increase the generation time. In this paper, we discover that object duplication arises from feature duplication in the deep blocks of the U-Net. Concurrently, We pinpoint the extended generation times to self-attention redundancy in U-Net's top blocks. To address these issues, we propose a tuning-free higher-resolution framework named HiDiffusion. Specifically, HiDiffusion contains Resolution-Aware U-Net (RAU-Net) that dynamically adjusts the feature map size to resolve object duplication and engages Modified Shifted Window Multi-head Self-Attention (MSW-MSA) that utilizes optimized window attention to reduce computations. we can integrate HiDiffusion into various pretrained diffusion models to scale image generation resolutions even to 4096x4096 at 1.5-6x the inference speed of previous methods. Extensive experiments demonstrate that our approach can address object duplication and heavy computation issues, achieving state-of-the-art performance on higher-resolution image synthesis tasks.
Read more4/30/2024

0
MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
Nithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, Vishal M Patel
Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-toend with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess.
Read more4/16/2024