Efficient generative adversarial networks using linear additive-attention Transformers

0
Sign in to get full access
Overview
- Introduces an efficient Generative Adversarial Network (GAN) architecture that uses linear additive-attention Transformers
- Claims this approach leads to more efficient and stable GAN training compared to existing methods
- Evaluates the proposed architecture on various image generation benchmarks
Plain English Explanation
Generative Adversarial Networks (GANs) are a type of machine learning model that can generate realistic-looking images. However, training GANs can be challenging and computationally intensive.
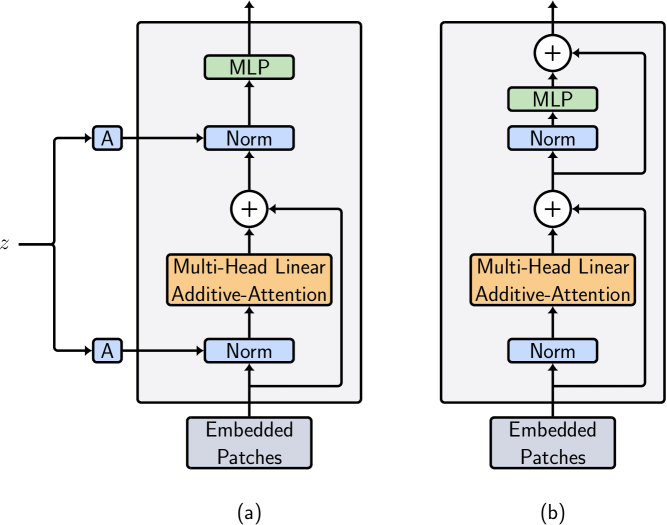
The researchers in this paper propose a new GAN architecture that uses a type of neural network called a Transformer, which is particularly good at capturing long-range dependencies in data. Specifically, they use a variant of the Transformer called a "linear additive-attention" Transformer, which is more computationally efficient than the standard Transformer.
The key idea is that this efficient Transformer architecture allows the GAN to be trained more effectively and stably compared to other GAN models. The authors evaluate their approach on several standard image generation benchmarks and show that it outperforms previous state-of-the-art GAN models in terms of image quality and training stability.
Technical Explanation
The paper introduces a novel GAN architecture that leverages linear additive-attention Transformers to achieve more efficient and stable training. Transformers have shown great success in natural language processing tasks, and the authors hypothesize that their ability to capture long-range dependencies can also benefit image generation.
The proposed architecture consists of a generator and a discriminator, both of which use linear additive-attention Transformer layers. This attention mechanism is more computationally efficient than the standard attention used in Transformers, as it avoids the quadratic complexity of the original formulation.
The authors extensively evaluate their model on several image generation benchmarks, including CIFAR-10, CelebA, and LSUN. They compare their approach to state-of-the-art GAN models and show that it achieves superior performance in terms of image quality (as measured by Inception Score and FID) and training stability.
Critical Analysis
The paper makes a compelling case for the use of linear additive-attention Transformers in GAN architectures. The authors demonstrate the benefits of this approach through rigorous experimentation and comparison to existing methods.
However, the paper does not address potential limitations or caveats of the proposed architecture. For example, it would be interesting to understand how the model performs on more complex or high-resolution image generation tasks, or how it compares to other efficient GAN variants, such as those using gated linear units or other specialized components.
Additionally, the paper does not provide much insight into the inner workings of the model or the reasons behind its improved performance. A deeper analysis of the attention mechanism and its impact on GAN training would be valuable for understanding the underlying principles and potentially guiding further research in this direction.
Conclusion
This paper presents an efficient GAN architecture that leverages linear additive-attention Transformers to achieve improved image generation performance and training stability. The results demonstrate the potential of this approach and suggest that further research into the integration of Transformer-based models with GANs could lead to significant advancements in the field of generative modeling.
The proposed model offers a promising direction for developing more computationally efficient and effective GAN systems, which could have important applications in areas such as computer vision, image synthesis, and generative art. As the authors note, the findings of this work could also potentially extend to other types of generative models beyond GANs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient generative adversarial networks using linear additive-attention Transformers
Emilio Morales-Juarez, Gibran Fuentes-Pineda
Although the capacity of deep generative models for image generation, such as Diffusion Models (DMs) and Generative Adversarial Networks (GANs), has dramatically improved in recent years, much of their success can be attributed to computationally expensive architectures. This has limited their adoption and use to research laboratories and companies with large resources, while significantly raising the carbon footprint for training, fine-tuning, and inference. In this work, we present LadaGAN, an efficient generative adversarial network that is built upon a novel Transformer block named Ladaformer. The main component of this block is a linear additive-attention mechanism that computes a single attention vector per head instead of the quadratic dot-product attention. We employ Ladaformer in both the generator and discriminator, which reduces the computational complexity and overcomes the training instabilities often associated with Transformer GANs. LadaGAN consistently outperforms existing convolutional and Transformer GANs on benchmark datasets at different resolutions while being significantly more efficient. Moreover, LadaGAN shows competitive performance compared to state-of-the-art multi-step generative models (e.g. DMs) using orders of magnitude less computational resources.
Read more8/22/2024
1
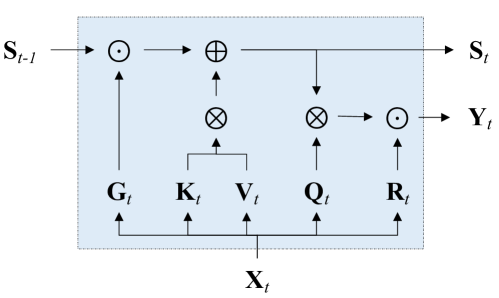
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
Read more6/6/2024

0
LinFusion: 1 GPU, 1 Minute, 16K Image
Songhua Liu, Weihao Yu, Zhenxiong Tan, Xinchao Wang
Modern diffusion models, particularly those utilizing a Transformer-based UNet for denoising, rely heavily on self-attention operations to manage complex spatial relationships, thus achieving impressive generation performance. However, this existing paradigm faces significant challenges in generating high-resolution visual content due to its quadratic time and memory complexity with respect to the number of spatial tokens. To address this limitation, we aim at a novel linear attention mechanism as an alternative in this paper. Specifically, we begin our exploration from recently introduced models with linear complexity, e.g., Mamba2, RWKV6, Gated Linear Attention, etc, and identify two key features-attention normalization and non-causal inference-that enhance high-resolution visual generation performance. Building on these insights, we introduce a generalized linear attention paradigm, which serves as a low-rank approximation of a wide spectrum of popular linear token mixers. To save the training cost and better leverage pre-trained models, we initialize our models and distill the knowledge from pre-trained StableDiffusion (SD). We find that the distilled model, termed LinFusion, achieves performance on par with or superior to the original SD after only modest training, while significantly reducing time and memory complexity. Extensive experiments on SD-v1.5, SD-v2.1, and SD-XL demonstrate that LinFusion delivers satisfactory zero-shot cross-resolution generation performance, generating high-resolution images like 16K resolution. Moreover, it is highly compatible with pre-trained SD components, such as ControlNet and IP-Adapter, requiring no adaptation efforts. Codes are available at https://github.com/Huage001/LinFusion.
Read more9/6/2024
0
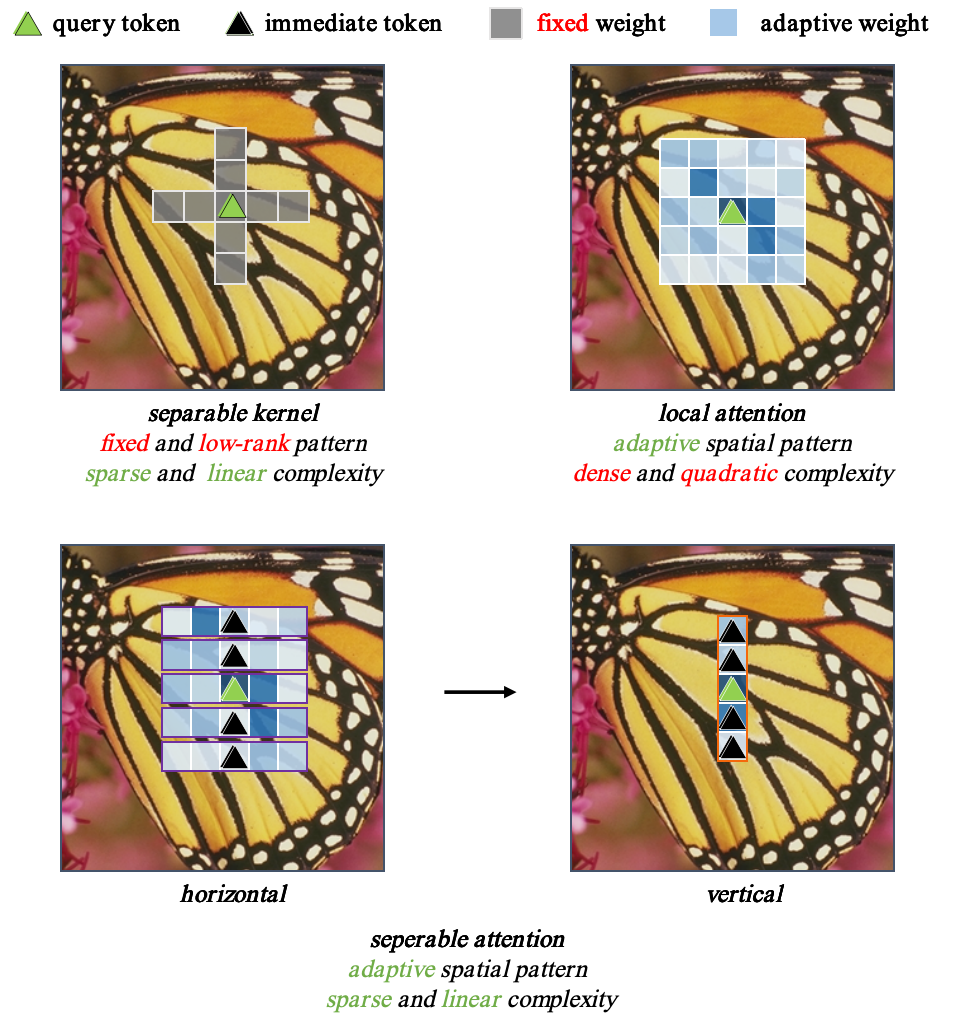
Unifying Dimensions: A Linear Adaptive Approach to Lightweight Image Super-Resolution
Zhenyu Hu, Wanjie Sun
Window-based transformers have demonstrated outstanding performance in super-resolution tasks due to their adaptive modeling capabilities through local self-attention (SA). However, they exhibit higher computational complexity and inference latency than convolutional neural networks. In this paper, we first identify that the adaptability of the Transformers is derived from their adaptive spatial aggregation and advanced structural design, while their high latency results from the computational costs and memory layout transformations associated with the local SA. To simulate this aggregation approach, we propose an effective convolution-based linear focal separable attention (FSA), allowing for long-range dynamic modeling with linear complexity. Additionally, we introduce an effective dual-branch structure combined with an ultra-lightweight information exchange module (IEM) to enhance the aggregation of information by the Token Mixer. Finally, with respect to the structure, we modify the existing spatial-gate-based feedforward neural networks by incorporating a self-gate mechanism to preserve high-dimensional channel information, enabling the modeling of more complex relationships. With these advancements, we construct a convolution-based Transformer framework named the linear adaptive mixer network (LAMNet). Extensive experiments demonstrate that LAMNet achieves better performance than existing SA-based Transformer methods while maintaining the computational efficiency of convolutional neural networks, which can achieve a (3times) speedup of inference time. The code will be publicly available at: https://github.com/zononhzy/LAMNet.
Read more9/27/2024