QuickLLaMA: Query-aware Inference Acceleration for Large Language Models
2406.07528
0
0

Abstract
The capacity of Large Language Models (LLMs) to comprehend and reason over long contexts is pivotal for advancements in diverse fields. Yet, they still stuggle with capturing long-distance dependencies within sequences to deeply understand semantics. To address this issue, we introduce Query-aware Inference for LLMs (Q-LLM), a system designed to process extensive sequences akin to human cognition. By focusing on memory data relevant to a given query, Q-LLM can accurately capture pertinent information within a fixed window size and provide precise answers to queries. It doesn't require extra training and can be seamlessly integrated with any LLMs. Q-LLM using LLaMA3 (QuickLLaMA) can read Harry Potter within 30s and accurately answer the questions. Q-LLM improved by 7.17% compared to the current state-of-the-art on LLaMA3, and by 3.26% on Mistral on the $infty$-bench. In the Needle-in-a-Haystack task, On widely recognized benchmarks, Q-LLM improved upon the current SOTA by 7.0% on Mistral and achieves 100% on LLaMA3. Our code can be found in https://github.com/dvlab-research/Q-LLM.
Create account to get full access
Overview
- This paper introduces QuickLLaMA, a technique to accelerate inference for large language models (LLMs) like GPT-3 and LAMLA.
- QuickLLaMA uses query-aware techniques to selectively activate only the most relevant parts of the LLM for a given input, reducing the overall computation required.
- The authors demonstrate significant speedups in inference time while maintaining high accuracy on a range of NLP tasks.
Plain English Explanation
QuickLLaMA is a new method that can make large language models, like the ones used in ChatGPT, run much faster. Large language models are powerful AI systems that can understand and generate human-like text, but they also require a lot of computing power to run.
The key idea behind QuickLLaMA is to only activate the most relevant parts of the language model for a given input. Normally, the entire language model has to run to produce an output, which takes a lot of time. But QuickLLaMA can figure out which specific parts of the model are most important for the current input, and only run those parts. This reduces the overall computation required, resulting in much faster inference times.
The authors show that QuickLLaMA can achieve significant speedups, sometimes running up to 10 times faster than the original language model, while still maintaining high accuracy on a variety of language tasks. This could be very useful for applications that need to use large language models in real-time, like chatbots or virtual assistants, where speed is crucial.
Technical Explanation
QuickLLaMA works by using a novel "query-aware" approach to selectively activate only the most relevant parts of a large language model (LLM) for a given input. Typical LLMs like GPT-3 or LAMLA process the entire model for each input, which is computationally expensive.
Instead, QuickLLaMA first uses a lightweight neural network to analyze the input and identify the most important parts of the LLM that are likely to be relevant. It then only activates those specific parts of the LLM, skipping the rest. This selective activation significantly reduces the overall computation required, leading to faster inference times.
The authors evaluate QuickLLaMA on a range of NLP tasks, including text classification, question answering, and language generation. They show that QuickLLaMA can achieve speedups of up to 10x compared to the original LLM, while maintaining competitive accuracy. This demonstrates the effectiveness of their query-aware approach for accelerating LLM inference.
Critical Analysis
The QuickLLaMA paper presents a promising technique for improving the efficiency of large language models, but there are a few potential limitations and areas for further research:
-
The authors only evaluate QuickLLaMA on a limited set of tasks, so it's unclear how well the method would generalize to a wider range of applications. More comprehensive testing would be helpful.
-
The paper doesn't provide much detail on the computational overhead of the query-aware neural network used to identify the relevant parts of the LLM. This overhead could potentially offset some of the gains from selective activation.
-
The authors mention that QuickLLaMA could be combined with other efficiency techniques, like OptLLM or XL3M, but they don't explore these combinations in depth. Investigating synergies with other methods could lead to even greater efficiency improvements.
-
The paper does not address the potential impact of uncertainty-aware techniques on the QuickLLaMA approach, which could be an interesting area for future research.
-
While the authors demonstrate the benefits of QuickLLaMA for semantic query processing, the paper does not explore other potential use cases or real-world applications in depth.
Overall, the QuickLLaMA method appears to be a valuable contribution to the field of efficient inference for large language models, but further research and development could help address some of the limitations and unlock additional use cases.
Conclusion
QuickLLaMA is a novel technique that can significantly accelerate the inference process for large language models like GPT-3 and LAMLA. By using a query-aware approach to selectively activate only the most relevant parts of the LLM for a given input, QuickLLaMA can achieve speedups of up to 10x while maintaining high accuracy.
This could be a game-changer for applications that require the capabilities of large language models but need to operate in real-time, such as chatbots, virtual assistants, or semantic query processing systems. The authors have demonstrated the potential of QuickLLaMA, and further research and development in this area could lead to even more efficient and versatile language models that can be deployed at scale.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
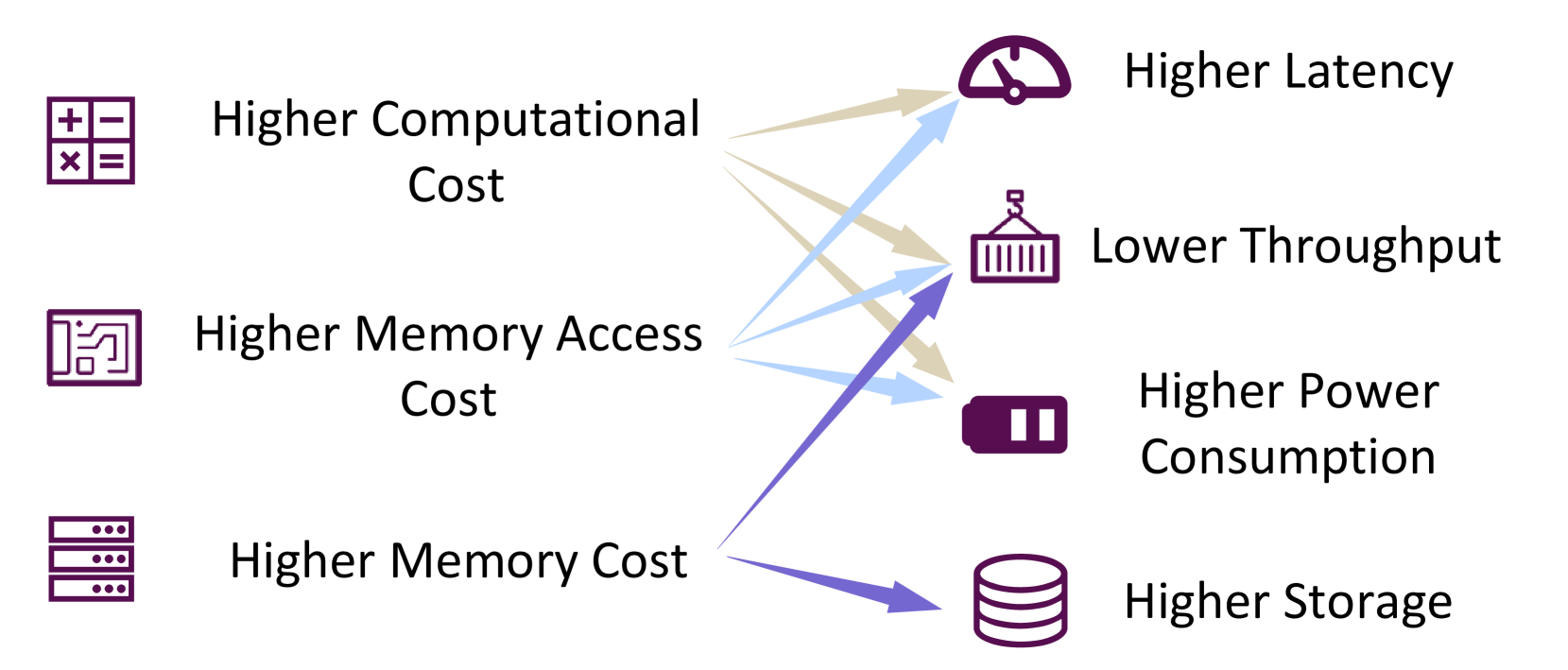
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
6/11/2024
LiveMind: Low-latency Large Language Models with Simultaneous Inference
Chuangtao Chen, Grace Li Zhang, Xunzhao Yin, Cheng Zhuo, Ulf Schlichtmann, Bing Li
0
0
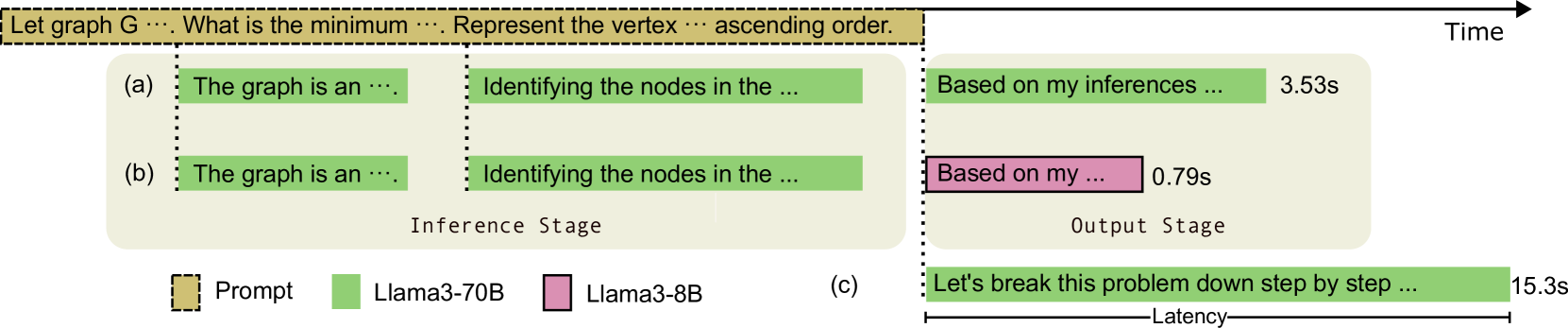
In this paper, we introduce a novel low-latency inference framework for large language models (LLMs) inference which enables LLMs to perform inferences with incomplete prompts. By reallocating computational processes to prompt input phase, we achieve a substantial reduction in latency, thereby significantly enhancing the interactive experience for users of LLMs. The framework adeptly manages the visibility of the streaming prompt to the model, allowing it to infer from incomplete prompts or await additional prompts. Compared with traditional inference methods that utilize complete prompts, our approach demonstrates an average reduction of 59% in response latency on the MMLU-Pro dataset, while maintaining comparable accuracy. Additionally, our framework facilitates collaborative inference and output across different models. By employing an LLM for inference and a small language model (SLM) for output, we achieve an average 68% reduction in response latency, alongside a 5.5% improvement in accuracy on the MMLU-Pro dataset compared with the SLM baseline. For long prompts exceeding 20 sentences, the response latency can be reduced by up to 93%.
6/21/2024
OptLLM: Optimal Assignment of Queries to Large Language Models
Yueyue Liu, Hongyu Zhang, Yuantian Miao, Van-Hoang Le, Zhiqiang Li
0
0
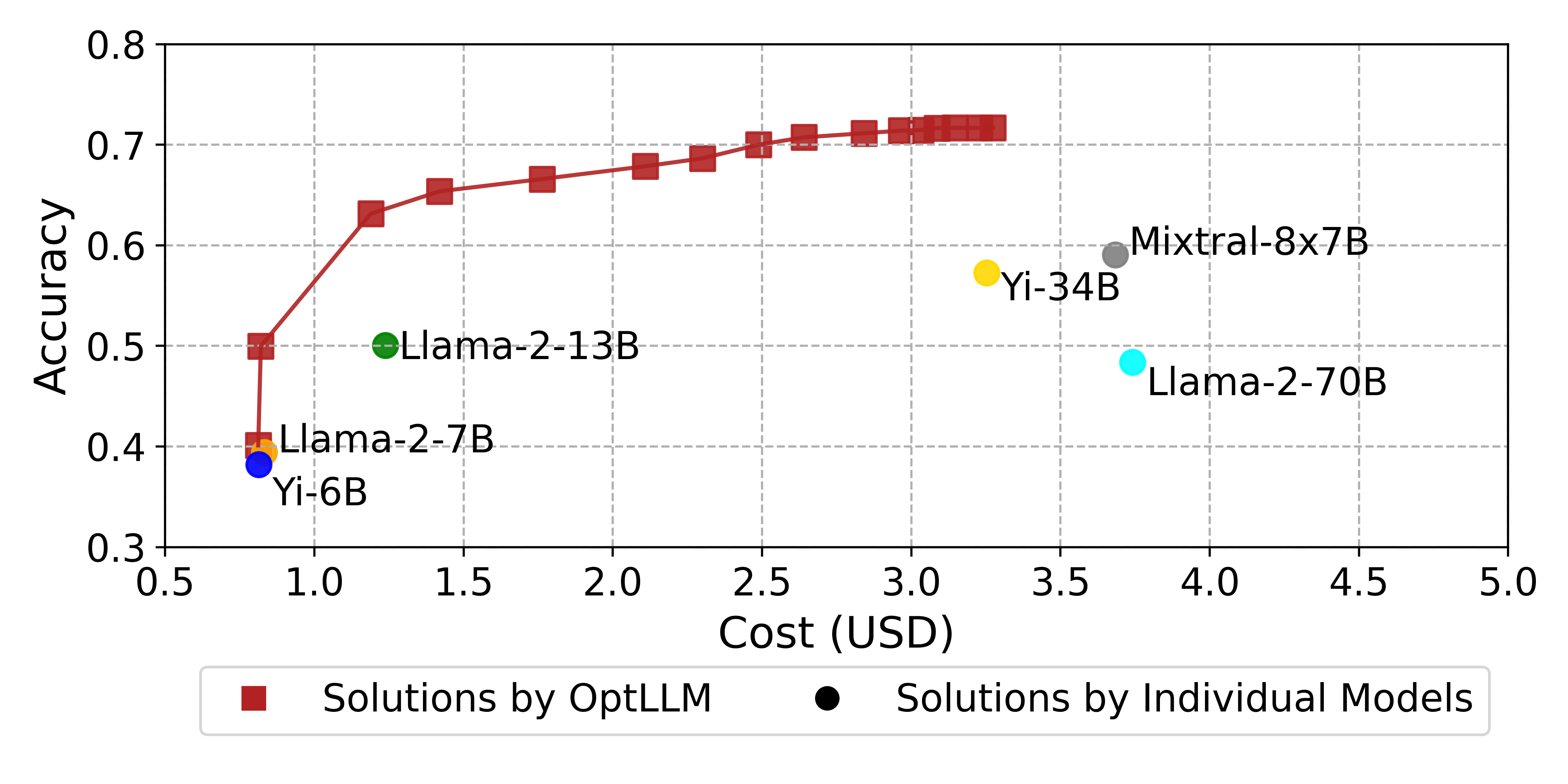
Large Language Models (LLMs) have garnered considerable attention owing to their remarkable capabilities, leading to an increasing number of companies offering LLMs as services. Different LLMs achieve different performance at different costs. A challenge for users lies in choosing the LLMs that best fit their needs, balancing cost and performance. In this paper, we propose a framework for addressing the cost-effective query allocation problem for LLMs. Given a set of input queries and candidate LLMs, our framework, named OptLLM, provides users with a range of optimal solutions to choose from, aligning with their budget constraints and performance preferences, including options for maximizing accuracy and minimizing cost. OptLLM predicts the performance of candidate LLMs on each query using a multi-label classification model with uncertainty estimation and then iteratively generates a set of non-dominated solutions by destructing and reconstructing the current solution. To evaluate the effectiveness of OptLLM, we conduct extensive experiments on various types of tasks, including text classification, question answering, sentiment analysis, reasoning, and log parsing. Our experimental results demonstrate that OptLLM substantially reduces costs by 2.40% to 49.18% while achieving the same accuracy as the best LLM. Compared to other multi-objective optimization algorithms, OptLLM improves accuracy by 2.94% to 69.05% at the same cost or saves costs by 8.79% and 95.87% while maintaining the highest attainable accuracy.
5/27/2024
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, Song Han
0
0
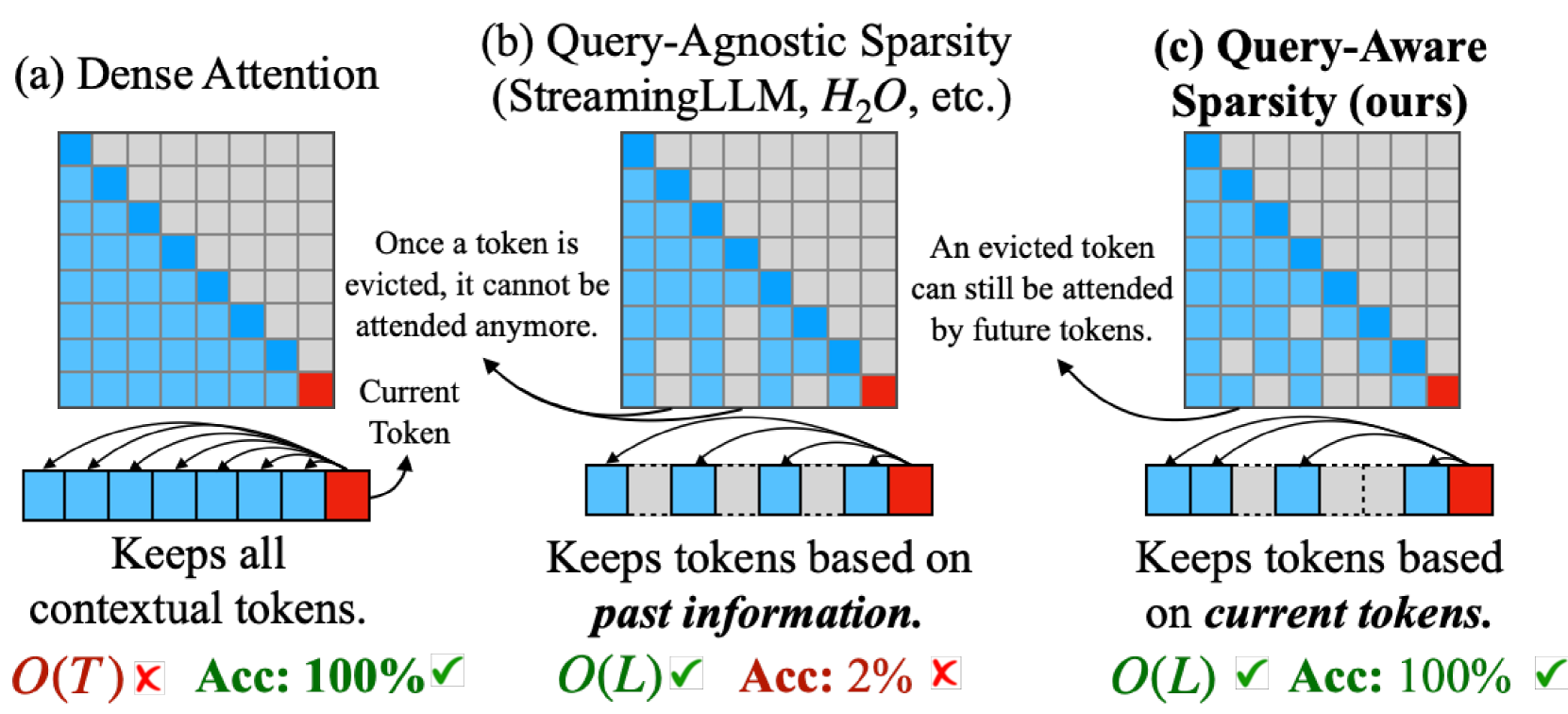
As the demand for long-context large language models (LLMs) increases, models with context windows of up to 128K or 1M tokens are becoming increasingly prevalent. However, long-context LLM inference is challenging since the inference speed decreases significantly as the sequence length grows. This slowdown is primarily caused by loading a large KV cache during self-attention. Previous works have shown that a small portion of critical tokens will dominate the attention outcomes. However, we observe the criticality of a token highly depends on the query. To this end, we propose Quest, a query-aware KV cache selection algorithm. Quest keeps track of the minimal and maximal Key values in KV cache pages and estimates the criticality of a given page using Query vectors. By only loading the Top-K critical KV cache pages for attention, Quest significantly speeds up self-attention without sacrificing accuracy. We show that Quest can achieve up to 2.23x self-attention speedup, which reduces inference latency by 7.03x while performing well on tasks with long dependencies with negligible accuracy loss. Code is available at http://github.com/mit-han-lab/Quest .
6/18/2024