LLaMA Pro: Progressive LLaMA with Block Expansion

1
Sign in to get full access
Introduction
This paper proposes a novel approach called "LLaMA Pro" that builds upon the popular LLaMA language model. LLaMA Pro introduces a "progressive" training mechanism that gradually expands the model's capabilities over time, allowing it to handle more complex tasks and data as it grows. The key innovation is the "block expansion" technique, which selectively adds new neural network layers to the model as it is fine-tuned on new datasets, rather than training a completely new model from scratch.
Related Work
Advancements in Large Language Models.
The paper situates LLaMA Pro within the broader context of advancements in large language models (LLMs), such as novel paradigms for boosting translation capabilities, massive language adaptation, and explorations of unleashing the power of LLMs. These efforts have pushed the boundaries of what LLMs can achieve, motivating the need for flexible and scalable approaches like LLaMA Pro.
Post-pretraining.
The paper also acknowledges the importance of post-pretraining techniques, such as expanding LLMs for spoken language understanding and large language model automatic computer extension (L2MAC), which have demonstrated the potential for LLMs to adapt to new domains and tasks beyond their initial pretraining.
Plain English Explanation
LLaMA Pro is a new way of training large language models (LLMs) that allows them to gradually expand their capabilities over time. Instead of training a completely new model from scratch every time, LLaMA Pro adds new neural network layers to an existing model as it is fine-tuned on new datasets. This "block expansion" technique makes the training process more efficient and allows the model to build upon its previous knowledge, rather than starting from scratch.
The key idea is to create a "progressive" training approach, where the model starts with a basic foundation and then selectively adds new capabilities as needed. This is similar to how humans learn, building upon their existing knowledge and skills to tackle more complex tasks over time. By adopting this approach, LLaMA Pro can be more flexible and adaptable than traditional LLMs, which are often trained on a fixed set of data and tasks.
The paper positions LLaMA Pro within the broader context of advancements in LLMs, such as novel techniques for improving translation and language adaptation. These efforts have pushed the boundaries of what LLMs can do, and LLaMA Pro aims to build on this progress by offering a more scalable and efficient way of training and expanding these powerful models.
Technical Explanation
The paper introduces the LLaMA Pro framework, which builds upon the existing LLaMA language model. The key innovation is the "block expansion" technique, which selectively adds new neural network layers to the model as it is fine-tuned on new datasets. This contrasts with the traditional approach of training a completely new model from scratch for each new task or dataset.
The LLaMA Pro training process consists of several stages:
- Pretraining: The model is first trained on a large, generic corpus of text data to acquire a broad base of knowledge and language understanding.
- Task-specific fine-tuning: The model is then fine-tuned on specific datasets or tasks, such as question answering or summarization.
- Block expansion: During the fine-tuning stage, the model's architecture is dynamically expanded by adding new neural network layers. These new layers are trained to handle the specific requirements of the new task or dataset, while the existing layers are fine-tuned to maintain their previous capabilities.
By adopting this progressive training approach, LLaMA Pro can build upon its existing knowledge and skills, rather than starting from scratch for each new task. This makes the training process more efficient and allows the model to scale to handle increasingly complex tasks and datasets over time.
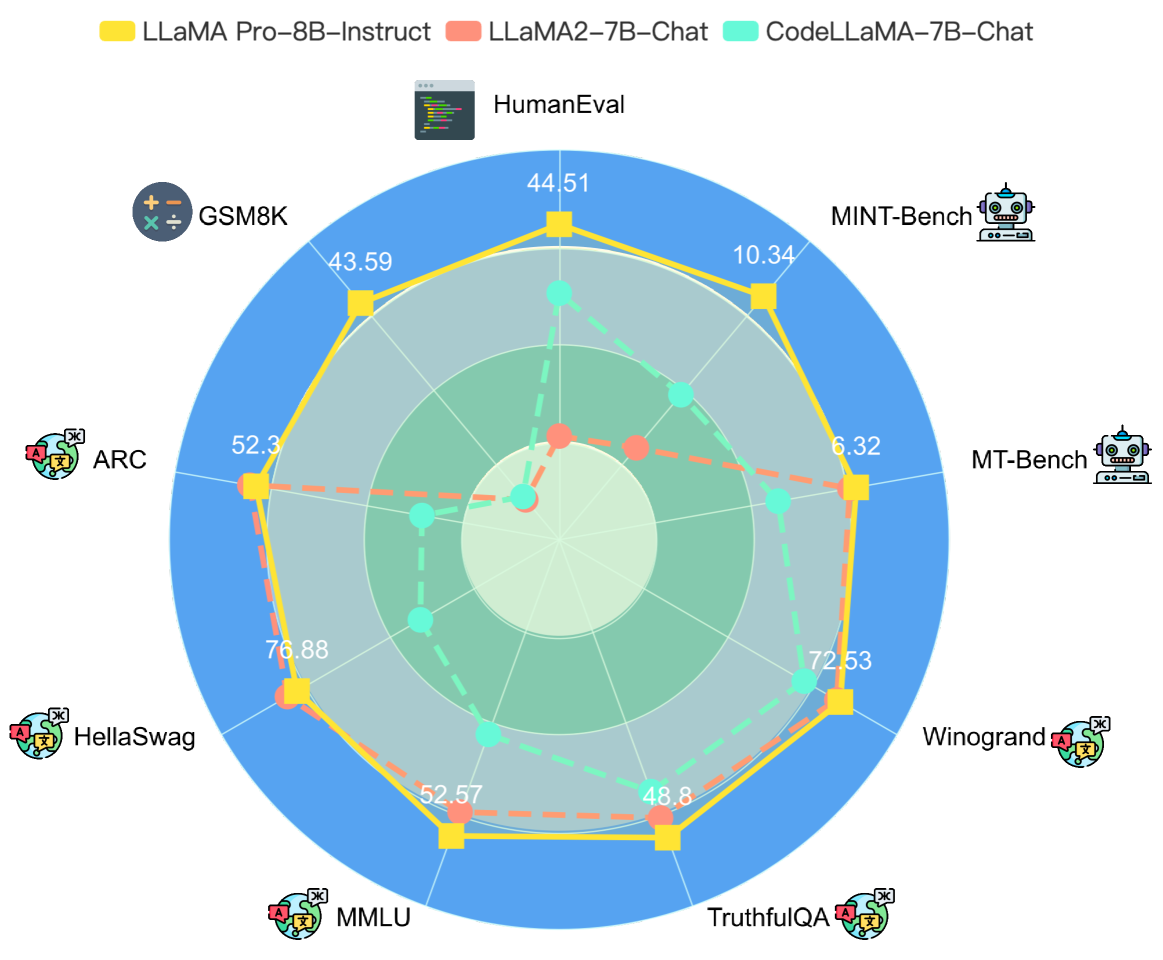
The paper presents experimental results demonstrating the effectiveness of the LLaMA Pro approach, showing that it can achieve competitive performance on a range of language tasks while requiring less training time and computational resources than training completely new models from scratch.
Critical Analysis
The paper presents a well-designed and promising approach to training more flexible and scalable large language models. The "block expansion" technique is an interesting innovation that addresses some of the limitations of traditional fine-tuning methods, which often require starting from scratch for each new task or dataset.
One potential concern is the complexity of the LLaMA Pro training process, which involves multiple stages and the dynamic expansion of the model's architecture. While this approach may be more efficient in the long run, it could also add overhead and introduce new challenges in terms of model management and optimization.
Additionally, the paper focuses primarily on the technical aspects of the LLaMA Pro framework and its performance on various language tasks. It would be valuable to see more discussion on the broader implications and potential societal impacts of such a scalable and adaptable language model, as well as any ethical considerations that may arise.
Further research could also explore the generalizability of the block expansion approach, investigating whether it can be applied to other types of neural networks or tasks beyond natural language processing.
Conclusion
The LLaMA Pro paper presents a novel and promising approach to training large language models that can gradually expand their capabilities over time. The key innovation of "block expansion" allows the model to build upon its existing knowledge and skills, rather than starting from scratch for each new task or dataset.
By adopting a progressive training approach, LLaMA Pro aims to create more flexible and scalable language models that can adapt to a wider range of applications and domains. This work contributes to the ongoing efforts to push the boundaries of what large language models can achieve, with potential implications for a variety of fields, from natural language processing to general artificial intelligence.
As the field of language models continues to evolve, approaches like LLaMA Pro will likely play an important role in developing more powerful and versatile AI systems that can tackle increasingly complex tasks and challenges.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
LLaMA Pro: Progressive LLaMA with Block Expansion
Chengyue Wu, Yukang Gan, Yixiao Ge, Zeyu Lu, Jiahao Wang, Ye Feng, Ying Shan, Ping Luo
Humans generally acquire new skills without compromising the old; however, the opposite holds for Large Language Models (LLMs), e.g., from LLaMA to CodeLLaMA. To this end, we propose a new post-pretraining method for LLMs with an expansion of Transformer blocks. We tune the expanded blocks using only new corpus, efficiently and effectively improving the model's knowledge without catastrophic forgetting. In this paper, we experiment on the corpus of code and math, yielding LLaMA Pro-8.3B, a versatile foundation model initialized from LLaMA2-7B, excelling in general tasks, programming, and mathematics. LLaMA Pro and its instruction-following counterpart (LLaMA Pro-Instruct) achieve advanced performance among various benchmarks, demonstrating superiority over existing open models in the LLaMA family and the immense potential of reasoning and addressing diverse tasks as an intelligent agent. Our findings provide valuable insights into integrating natural and programming languages, laying a solid foundation for developing advanced language agents that operate effectively in various environments.
Read more5/31/2024

0
A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
Read more4/16/2024

0
MaLA-500: Massive Language Adaptation of Large Language Models
Peiqin Lin, Shaoxiong Ji, Jorg Tiedemann, Andr'e F. T. Martins, Hinrich Schutze
Large language models (LLMs) have advanced the state of the art in natural language processing. However, their predominant design for English or a limited set of languages creates a substantial gap in their effectiveness for low-resource languages. To bridge this gap, we introduce MaLA-500, a novel large language model designed to cover an extensive range of 534 languages. To train MaLA-500, we employ vocabulary extension and continued pretraining on LLaMA 2 with Glot500-c. Our intrinsic evaluation demonstrates that MaLA-500 is better at predicting the given texts of low-resource languages than existing multilingual LLMs. Moreover, the extrinsic evaluation of in-context learning shows that MaLA-500 outperforms previous LLMs on SIB200 and Taxi1500 by a significant margin, i.e., 11.68% and 4.82% marco-average accuracy across languages. We release MaLA-500 at https://huggingface.co/MaLA-LM
Read more4/4/2024
💬
0
Exploring and Unleashing the Power of Large Language Models in Automated Code Translation
Zhen Yang, Fang Liu, Zhongxing Yu, Jacky Wai Keung, Jia Li, Shuo Liu, Yifan Hong, Xiaoxue Ma, Zhi Jin, Ge Li
Code translation tools (transpilers) are developed for automatic source-to-source translation. Although learning-based transpilers have shown impressive enhancement against rule-based counterparts, owing to their task-specific pre-training on extensive monolingual corpora. Their current performance still remains unsatisfactory for practical deployment, and the associated training resources are also prohibitively expensive. LLMs pre-trained on huge amounts of human-written code/text have shown remarkable performance in many code intelligence tasks due to their powerful generality, even without task-specific training. Thus, LLMs can potentially circumvent the above limitations, but they have not been exhaustively explored yet. This paper investigates diverse LLMs and learning-based transpilers for automated code translation tasks, finding that: although certain LLMs have outperformed current transpilers, they still have some accuracy issues, where most of the failures are induced by a lack of comprehension of source programs, missing clear instructions on I/O types in translation, and ignoring discrepancies between source and target programs. Enlightened by the above findings, we further propose UniTrans, a Unified code Translation framework, applicable to various LLMs, for unleashing their power in this field. Specifically, UniTrans first crafts a series of test cases for target programs with the assistance of source programs. Next, it harnesses the above auto-generated test cases to augment the code translation and then evaluate their correctness via execution. Afterward, UniTrans further (iteratively) repairs incorrectly translated programs prompted by test case execution results. Extensive experiments are conducted on six settings of translation datasets between Python, Java, and C++. Three recent LLMs of diverse sizes are tested with UniTrans, and all achieve substantial improvements.
Read more5/14/2024