LLARVA: Vision-Action Instruction Tuning Enhances Robot Learning
2406.11815
0
0

Abstract
In recent years, instruction-tuned Large Multimodal Models (LMMs) have been successful at several tasks, including image captioning and visual question answering; yet leveraging these models remains an open question for robotics. Prior LMMs for robotics applications have been extensively trained on language and action data, but their ability to generalize in different settings has often been less than desired. To address this, we introduce LLARVA, a model trained with a novel instruction tuning method that leverages structured prompts to unify a range of robotic learning tasks, scenarios, and environments. Additionally, we show that predicting intermediate 2-D representations, which we refer to as visual traces, can help further align vision and action spaces for robot learning. We generate 8.5M image-visual trace pairs from the Open X-Embodiment dataset in order to pre-train our model, and we evaluate on 12 different tasks in the RLBench simulator as well as a physical Franka Emika Panda 7-DoF robot. Our experiments yield strong performance, demonstrating that LLARVA - using 2-D and language representations - performs well compared to several contemporary baselines, and can generalize across various robot environments and configurations.
Create account to get full access
Overview
- This paper introduces LLARVA, a vision-action instruction tuning approach that enhances robot learning.
- LLARVA combines language, vision, and action to enable robots to better understand and execute instructions.
- The key idea is to use language-based instruction tuning to improve the robot's ability to perceive visual cues and map them to appropriate actions.
Plain English Explanation
LLARVA is a new technique that helps robots learn better by combining language, vision, and action. Robots often struggle to understand and follow instructions, especially when those instructions involve complex visual cues and actions. LLARVA aims to address this challenge by using language-based training to improve the robot's ability to see things in the world and map those visual cues to the right actions.
The core idea is that by training the robot on language-based instructions, you can enhance its visual perception and action planning capabilities. For example, if you train the robot to understand phrases like "pick up the red ball" or "place the object on the table," it can learn to better recognize those visual elements and perform the corresponding physical actions. This builds on related work in vision-language-action models and open-source vision-language-action frameworks.
Technical Explanation
The key innovation in LLARVA is the use of "vision-action instruction tuning" to enhance the robot's learning. The researchers first train a base model on standard robot control tasks. They then fine-tune this model by exposing it to language-based instructions that describe visual scenes and the corresponding actions.
This fine-tuning process helps the model learn to better recognize visual elements (e.g., objects, locations) and associate them with the appropriate actions. For example, after training on instructions like "pick up the red ball," the model learns to detect red balls in the environment and execute the pick-up motion.
The researchers evaluate LLARVA on a range of robot manipulation tasks, including object rearrangement, tool use, and multi-step sequences. They find that the vision-action instruction tuning approach significantly improves the robot's performance compared to baseline models that do not use this technique. This builds on prior work on action contextualization and adaptive task planning.
Critical Analysis
The LLARVA approach represents an important step forward in enabling robots to better understand and execute complex, language-based instructions. By bridging the gap between visual perception, language understanding, and action planning, the technique could have significant implications for a wide range of robotic applications, from household assistants to industrial automation.
That said, the paper acknowledges several limitations and areas for future research. For example, the experiments are conducted in relatively controlled, simulated environments, and it's unclear how well the approach would generalize to more complex, real-world scenarios. Additionally, the language-based instructions used in the study are relatively simplistic, and it's not known how well the technique would handle more nuanced, context-dependent language.
[Further research could explore ways to extend the vision-language-action capabilities of LLARVA, such as by incorporating more generative visual instruction tuning or leveraging recent advances in embodied AI and vision-language-action models.]
Conclusion
Overall, the LLARVA paper presents a promising approach for enhancing robot learning by integrating language, vision, and action. By using language-based instruction tuning to improve the robot's visual perception and action planning, the technique could help pave the way for more intuitive and capable robotic systems that can better understand and execute complex, real-world instructions. While more research is needed to address the current limitations, LLARVA represents an exciting step forward in the field of robot learning and control.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
Xiang Li, Cristina Mata, Jongwoo Park, Kumara Kahatapitiya, Yoo Sung Jang, Jinghuan Shang, Kanchana Ranasinghe, Ryan Burgert, Mu Cai, Yong Jae Lee, Michael S. Ryoo
0
0
Large Language Models (LLMs) equipped with extensive world knowledge and strong reasoning skills can tackle diverse tasks across domains, often by posing them as conversation-style instruction-response pairs. In this paper, we propose LLaRA: Large Language and Robotics Assistant, a framework which formulates robot action policy as conversations, and provides improved responses when trained with auxiliary data that complements policy learning. LLMs with visual inputs, i.e., Vision Language Models (VLMs), have the capacity to process state information as visual-textual prompts and generate optimal policy decisions in text. To train such action policy VLMs, we first introduce an automated pipeline to generate diverse high-quality robotics instruction data from existing behavior cloning data. A VLM finetuned with the resulting collection of datasets based on a conversation-style formulation tailored for robotics tasks, can generate meaningful robot action policy decisions. Our experiments across multiple simulated and real-world environments demonstrate the state-of-the-art performance of the proposed LLaRA framework. The code, datasets, and pretrained models are available at https://github.com/LostXine/LLaRA.
7/1/2024
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
Pengxiang Ding, Han Zhao, Wenjie Zhang, Wenxuan Song, Ningxi Yang, Donglin Wang
0
0
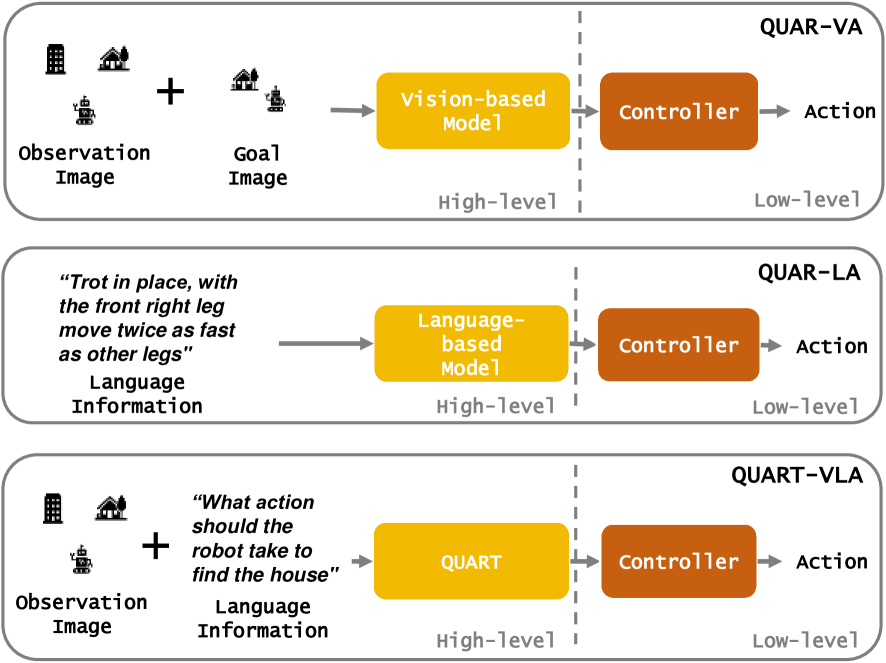
The important manifestation of robot intelligence is the ability to naturally interact and autonomously make decisions. Traditional approaches to robot control often compartmentalize perception, planning, and decision-making, simplifying system design but limiting the synergy between different information streams. This compartmentalization poses challenges in achieving seamless autonomous reasoning, decision-making, and action execution. To address these limitations, a novel paradigm, named Vision-Language-Action tasks for QUAdruped Robots (QUAR-VLA), has been introduced in this paper. This approach tightly integrates visual information and instructions to generate executable actions, effectively merging perception, planning, and decision-making. The central idea is to elevate the overall intelligence of the robot. Within this framework, a notable challenge lies in aligning fine-grained instructions with visual perception information. This emphasizes the complexity involved in ensuring that the robot accurately interprets and acts upon detailed instructions in harmony with its visual observations. Consequently, we propose QUAdruped Robotic Transformer (QUART), a family of VLA models to integrate visual information and instructions from diverse modalities as input and generates executable actions for real-world robots and present QUAdruped Robot Dataset (QUARD), a large-scale multi-task dataset including navigation, complex terrain locomotion, and whole-body manipulation tasks for training QUART models. Our extensive evaluation (4000 evaluation trials) shows that our approach leads to performant robotic policies and enables QUART to obtain a range of emergent capabilities.
6/18/2024
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn
0
0
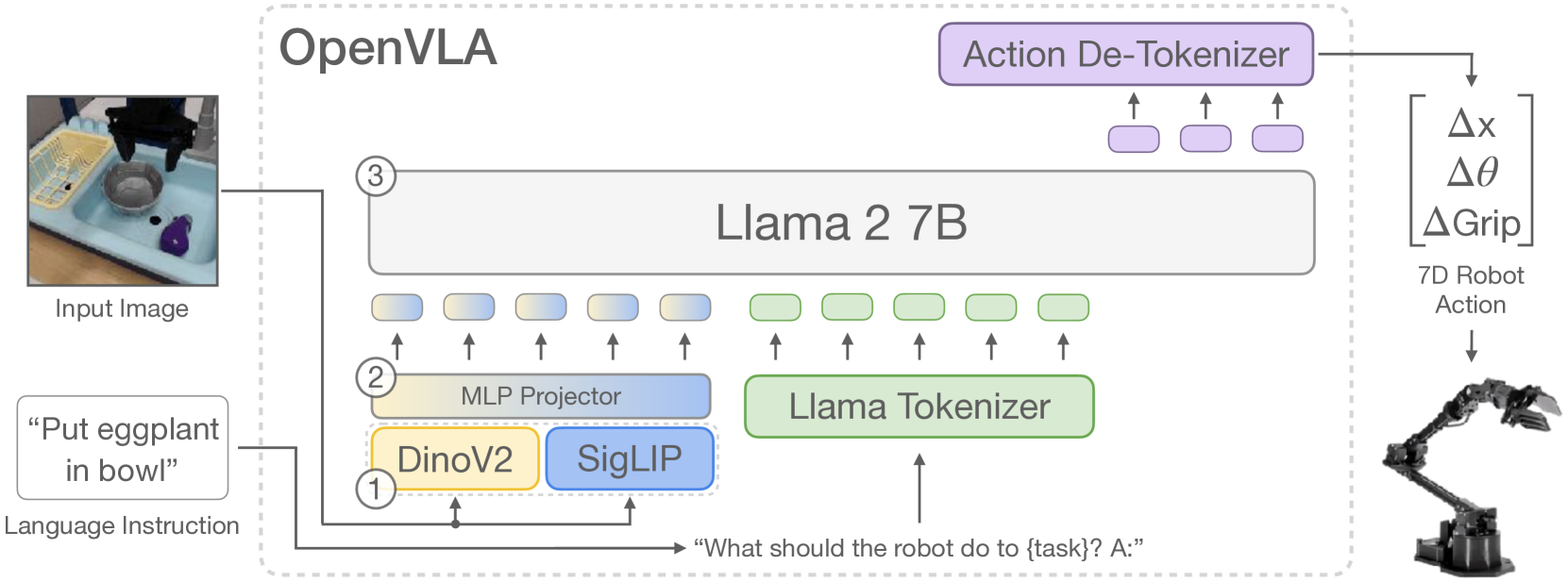
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
6/14/2024
🤖
A Survey on Vision-Language-Action Models for Embodied AI
Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, Irwin King
0
0
Deep learning has demonstrated remarkable success across many domains, including computer vision, natural language processing, and reinforcement learning. Representative artificial neural networks in these fields span convolutional neural networks, Transformers, and deep Q-networks. Built upon unimodal neural networks, numerous multi-modal models have been introduced to address a range of tasks such as visual question answering, image captioning, and speech recognition. The rise of instruction-following robotic policies in embodied AI has spurred the development of a novel category of multi-modal models known as vision-language-action models (VLAs). Their multi-modality capability has become a foundational element in robot learning. Various methods have been proposed to enhance traits such as versatility, dexterity, and generalizability. Some models focus on refining specific components through pretraining. Others aim to develop control policies adept at predicting low-level actions. Certain VLAs serve as high-level task planners capable of decomposing long-horizon tasks into executable subtasks. Over the past few years, a myriad of VLAs have emerged, reflecting the rapid advancement of embodied AI. Therefore, it is imperative to capture the evolving landscape through a comprehensive survey.
5/24/2024