LLavaGuard: VLM-based Safeguards for Vision Dataset Curation and Safety Assessment

0

Sign in to get full access
Overview
- This paper introduces LlavaGuard, a framework that uses vision-language models (VLMs) to safeguard vision dataset curation and safety assessment.
- LlavaGuard aims to address challenges in ensuring the safety and ethical alignment of vision datasets used to train AI models.
- The framework leverages the capabilities of VLMs to detect potentially harmful or sensitive content in images, as well as to generate descriptive captions that can be used to assess dataset safety.
Plain English Explanation
LlavaGuard: VLM-based Safeguards for Vision Dataset Curation and Safety Assessment is a research paper that presents a new framework for ensuring the safety and ethical alignment of vision datasets used to train AI models. The key idea is to use powerful vision-language models (VLMs) to analyze the content of images and assess their safety.
Vision datasets are crucial for training AI models that can see and understand the world, but they can also contain harmful or sensitive content, such as explicit or biased imagery. LlavaGuard aims to address this challenge by providing a set of tools and safeguards to help curate and assess the safety of vision datasets.
The framework leverages the advanced capabilities of VLMs, which can not only recognize the contents of images, but also generate detailed captions describing what they see. By applying these VLM-based techniques, LlavaGuard can identify potentially problematic images and generate safety assessments that can be used to improve the curation of vision datasets.
This research is particularly relevant given the growing importance of safety and alignment in large language models and the need to address similar challenges in the vision domain. By providing a systematic approach to ensuring the safety of vision datasets, LlavaGuard has the potential to contribute to the development of more ethical and responsible AI systems.
Technical Explanation
LlavaGuard: VLM-based Safeguards for Vision Dataset Curation and Safety Assessment introduces a framework that leverages the capabilities of vision-language models (VLMs) to safeguard the curation and safety assessment of vision datasets.
The key components of the LlavaGuard framework include:
-
Content Analysis: VLMs are used to analyze the content of images in a vision dataset, detecting potentially harmful or sensitive content, such as explicit, biased, or otherwise problematic imagery.
-
Safety Assessment: The VLMs generate detailed captions describing the contents of each image, which can then be used to assess the overall safety and ethical alignment of the dataset.
-
Curation Guidance: Based on the content analysis and safety assessment, LlavaGuard provides guidance and recommendations for curating the vision dataset, ensuring that it is free of harmful or unethical content.
The authors evaluate the performance of LlavaGuard on a range of vision datasets, demonstrating its effectiveness in identifying potentially problematic images and generating meaningful safety assessments. They also discuss the limitations of the approach and areas for future research, such as the need to address the safety and alignment challenges in large language models and the potential for extending these techniques to text-to-image generation models.
Critical Analysis
The LlavaGuard framework represents a promising approach to addressing the important challenge of ensuring the safety and ethical alignment of vision datasets used to train AI models. By leveraging the capabilities of VLMs, the framework provides a systematic way to analyze image content and assess dataset safety, which is a critical step in the development of responsible and trustworthy AI systems.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that the performance of the content analysis and safety assessment components may be influenced by the biases and limitations of the VLMs themselves, which could lead to incomplete or inaccurate assessments. Additionally, the paper does not address how the framework could be extended to handle dynamic or evolving datasets, where new images are continuously added and the safety assessment needs to be updated accordingly.
[Further research is also needed to explore the potential synergies between vision-based safeguards and the ongoing work on safeguarding large language models and developing safety frameworks for text-to-image generation. By integrating these different approaches, it may be possible to create more comprehensive and robust solutions for ensuring the safety and ethical alignment of AI systems across a range of modalities.
Conclusion
LlavaGuard: VLM-based Safeguards for Vision Dataset Curation and Safety Assessment presents a novel framework for addressing the important challenge of ensuring the safety and ethical alignment of vision datasets used to train AI models. By leveraging the capabilities of vision-language models, LlavaGuard provides a systematic approach to analyzing image content, assessing dataset safety, and guiding the curation process.
This research is a valuable contribution to the growing field of AI safety and alignment, as it demonstrates the potential for using advanced AI techniques to address ethical concerns in the development of vision-based AI systems. As the use of AI continues to expand into increasingly sensitive and consequential domains, frameworks like LlavaGuard will play a crucial role in helping to ensure that these systems are developed and deployed in a responsible and trustworthy manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLavaGuard: VLM-based Safeguards for Vision Dataset Curation and Safety Assessment
Lukas Helff, Felix Friedrich, Manuel Brack, Kristian Kersting, Patrick Schramowski
We introduce LlavaGuard, a family of VLM-based safeguard models, offering a versatile framework for evaluating the safety compliance of visual content. Specifically, we designed LlavaGuard for dataset annotation and generative model safeguarding. To this end, we collected and annotated a high-quality visual dataset incorporating a broad safety taxonomy, which we use to tune VLMs on context-aware safety risks. As a key innovation, LlavaGuard's new responses contain comprehensive information, including a safety rating, the violated safety categories, and an in-depth rationale. Further, our introduced customizable taxonomy categories enable the context-specific alignment of LlavaGuard to various scenarios. Our experiments highlight the capabilities of LlavaGuard in complex and real-world applications. We provide checkpoints ranging from 7B to 34B parameters demonstrating state-of-the-art performance, with even the smallest models outperforming baselines like GPT-4. We make our dataset and model weights publicly available and invite further research to address the diverse needs of communities and contexts.
Read more6/10/2024

0
MLLMGuard: A Multi-dimensional Safety Evaluation Suite for Multimodal Large Language Models
Tianle Gu, Zeyang Zhou, Kexin Huang, Dandan Liang, Yixu Wang, Haiquan Zhao, Yuanqi Yao, Xingge Qiao, Keqing Wang, Yujiu Yang, Yan Teng, Yu Qiao, Yingchun Wang
Powered by remarkable advancements in Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) demonstrate impressive capabilities in manifold tasks. However, the practical application scenarios of MLLMs are intricate, exposing them to potential malicious instructions and thereby posing safety risks. While current benchmarks do incorporate certain safety considerations, they often lack comprehensive coverage and fail to exhibit the necessary rigor and robustness. For instance, the common practice of employing GPT-4V as both the evaluator and a model to be evaluated lacks credibility, as it tends to exhibit a bias toward its own responses. In this paper, we present MLLMGuard, a multidimensional safety evaluation suite for MLLMs, including a bilingual image-text evaluation dataset, inference utilities, and a lightweight evaluator. MLLMGuard's assessment comprehensively covers two languages (English and Chinese) and five important safety dimensions (Privacy, Bias, Toxicity, Truthfulness, and Legality), each with corresponding rich subtasks. Focusing on these dimensions, our evaluation dataset is primarily sourced from platforms such as social media, and it integrates text-based and image-based red teaming techniques with meticulous annotation by human experts. This can prevent inaccurate evaluation caused by data leakage when using open-source datasets and ensures the quality and challenging nature of our benchmark. Additionally, a fully automated lightweight evaluator termed GuardRank is developed, which achieves significantly higher evaluation accuracy than GPT-4. Our evaluation results across 13 advanced models indicate that MLLMs still have a substantial journey ahead before they can be considered safe and responsible.
Read more6/14/2024
👀
0
Safety Alignment for Vision Language Models
Zhendong Liu, Yuanbi Nie, Yingshui Tan, Xiangyu Yue, Qiushi Cui, Chongjun Wang, Xiaoyong Zhu, Bo Zheng
Benefiting from the powerful capabilities of Large Language Models (LLMs), pre-trained visual encoder models connected to an LLMs can realize Vision Language Models (VLMs). However, existing research shows that the visual modality of VLMs is vulnerable, with attackers easily bypassing LLMs' safety alignment through visual modality features to launch attacks. To address this issue, we enhance the existing VLMs' visual modality safety alignment by adding safety modules, including a safety projector, safety tokens, and a safety head, through a two-stage training process, effectively improving the model's defense against risky images. For example, building upon the LLaVA-v1.5 model, we achieve a safety score of 8.26, surpassing the GPT-4V on the Red Teaming Visual Language Models (RTVLM) benchmark. Our method boasts ease of use, high flexibility, and strong controllability, and it enhances safety while having minimal impact on the model's general performance. Moreover, our alignment strategy also uncovers some possible risky content within commonly used open-source multimodal datasets. Our code will be open sourced after the anonymous review.
Read more5/24/2024
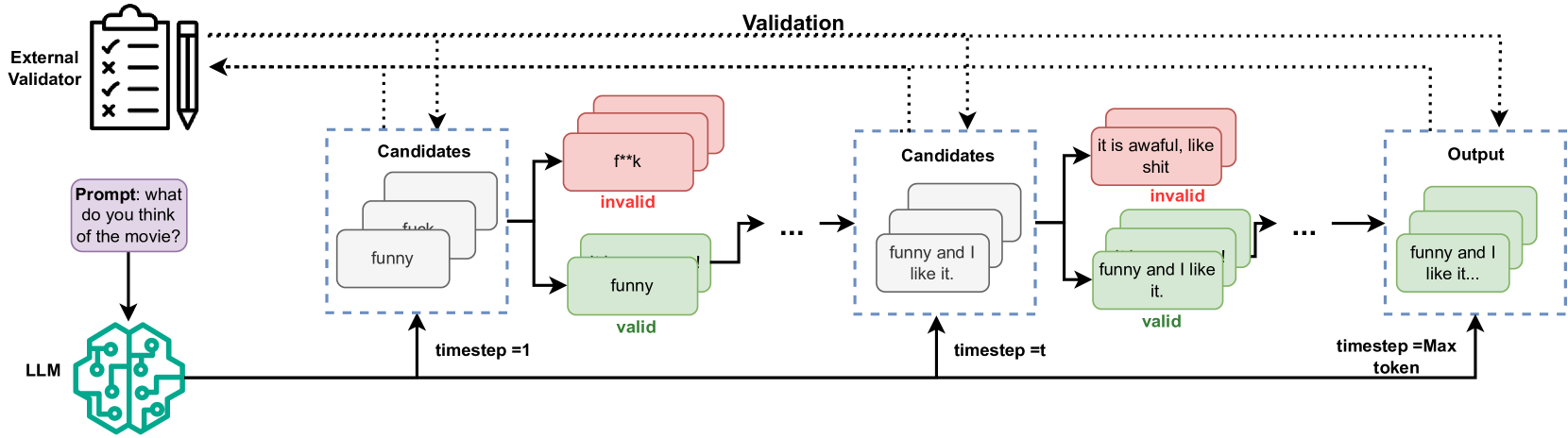
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024