LLAVIDAL: Benchmarking Large Language Vision Models for Daily Activities of Living

0

Sign in to get full access
Overview
- This paper presents a new benchmark called LLAVIDAL (Large Language Vision models for Daily Activities of Living) for evaluating large language-vision models on daily activity recognition tasks.
- The authors propose a semi-automated framework for generating video-instruction pairs that cover a diverse set of daily activities, addressing limitations of existing datasets.
- The paper benchmarks several state-of-the-art language-vision models on the LLAVIDAL dataset and provides insights into their performance and generalization capabilities.
Plain English Explanation
The paper focuses on evaluating how well large language-vision models, which combine natural language processing and computer vision, can recognize and understand everyday activities that people perform in their daily lives. These models have shown impressive capabilities in tasks like image captioning and visual question answering, but their performance on more complex, real-world activities has not been thoroughly assessed.
To address this, the researchers created a new benchmark dataset called LLAVIDAL, which contains a large collection of videos demonstrating a wide variety of daily activities, along with corresponding textual instructions. This dataset was generated using a semi-automated approach, which helped ensure it covered a diverse range of tasks that people commonly perform, such as cooking, cleaning, and personal care.
The paper then tests several state-of-the-art language-vision models on the LLAVIDAL dataset, measuring how accurately they can match the video content with the corresponding textual instructions. The results provide insights into the strengths and limitations of these models, highlighting areas where they excel and areas where they struggle, such as with activities that involve multiple steps or require fine-grained understanding of the visual scene.
Overall, this research contributes a valuable new benchmark for assessing the abilities of large language-vision models, which could have important implications for the development of more capable and versatile artificial intelligence systems that can assist people in their daily lives. The LLAVIDAL dataset and the insights from this study could also inform the design of future language-vision models and the development of interactive AI systems that can better understand and engage with real-world human activities.
Technical Explanation
The key elements of this paper include:
-
Semi-automated Framework for Generating ADL Video-instruction Pairs: The authors developed a novel framework to create the LLAVIDAL dataset, which consists of video demonstrations of daily activities paired with corresponding textual instructions. This framework involves a combination of automated and manual steps to ensure the dataset covers a diverse range of activities and is of high quality.
-
LLAVIDAL Benchmark: The LLAVIDAL dataset serves as a new benchmark for evaluating the performance of large language-vision models on the task of matching video content to textual instructions describing daily activities. The dataset contains over 10,000 video-instruction pairs covering a wide variety of activities.
-
Benchmarking Experiments: The paper reports the results of experiments evaluating several state-of-the-art language-vision models, including CLIP, ALIGN, and DiffuSyn, on the LLAVIDAL benchmark. The models' performance is assessed in terms of accuracy, robustness, and generalization capabilities.
-
Insights and Findings: The paper provides detailed analysis of the models' performance, highlighting their strengths and weaknesses in recognizing and understanding different types of daily activities. The results suggest that while these models have made significant progress, they still struggle with certain aspects of real-world activity understanding, such as handling multi-step tasks or fine-grained visual details.
Critical Analysis
The paper provides a comprehensive and well-designed benchmark for evaluating language-vision models on daily activity recognition tasks. The authors have addressed several limitations of existing datasets by creating the LLAVIDAL benchmark, which covers a broader and more diverse set of activities.
However, the paper could have benefited from a more in-depth discussion of the potential limitations and challenges of the LLAVIDAL dataset itself. For example, the authors mention that the dataset was generated using a semi-automated approach, but more details on the quality assurance measures and potential biases in the dataset would have been helpful.
Additionally, while the benchmarking experiments provide valuable insights, the paper could have explored the impact of different model architectures, pretraining strategies, and other factors that may influence the performance of language-vision models on this task. Further analysis along these lines could have yielded additional insights and implications for future model development.
Overall, the LLAVIDAL benchmark and the findings presented in this paper represent an important contribution to the field of language-vision understanding, and the dataset and insights could be leveraged to drive the development of more capable and versatile AI systems that can assist people in their daily lives.
Conclusion
This paper introduces a new benchmark called LLAVIDAL for evaluating large language-vision models on the task of recognizing and understanding daily activities of living. The authors developed a semi-automated framework to generate a diverse dataset of video-instruction pairs covering a wide range of everyday tasks, and they used this benchmark to assess the performance of several state-of-the-art models.
The results provide valuable insights into the strengths and limitations of these models, highlighting areas where they excel and areas where they struggle, such as with multi-step activities or fine-grained visual understanding. These findings have important implications for the continued development of language-vision models and their application in real-world, interactive AI systems that can assist people in their daily lives.
Overall, this research contributes a valuable new tool for the AI community and lays the groundwork for further advancements in the field of language-vision understanding and its practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LLAVIDAL: Benchmarking Large Language Vision Models for Daily Activities of Living
Rajatsubhra Chakraborty, Arkaprava Sinha, Dominick Reilly, Manish Kumar Govind, Pu Wang, Francois Bremond, Srijan Das
Large Language Vision Models (LLVMs) have demonstrated effectiveness in processing internet videos, yet they struggle with the visually perplexing dynamics present in Activities of Daily Living (ADL) due to limited pertinent datasets and models tailored to relevant cues. To this end, we propose a framework for curating ADL multiview datasets to fine-tune LLVMs, resulting in the creation of ADL-X, comprising 100K RGB video-instruction pairs, language descriptions, 3D skeletons, and action-conditioned object trajectories. We introduce LLAVIDAL, an LLVM capable of incorporating 3D poses and relevant object trajectories to understand the intricate spatiotemporal relationships within ADLs. Furthermore, we present a novel benchmark, ADLMCQ, for quantifying LLVM effectiveness in ADL scenarios. When trained on ADL-X, LLAVIDAL consistently achieves state-of-the-art performance across all ADL evaluation metrics. Qualitative analysis reveals LLAVIDAL's temporal reasoning capabilities in understanding ADL. The link to the dataset is provided at: https://adl-x.github.io/
Read more6/14/2024

0
Large Language Models are Zero-Shot Recognizers for Activities of Daily Living
Gabriele Civitarese, Michele Fiori, Priyankar Choudhary, Claudio Bettini
The sensor-based recognition of Activities of Daily Living (ADLs) in smart home environments enables several applications in the areas of energy management, safety, well-being, and healthcare. ADLs recognition is typically based on deep learning methods requiring large datasets to be trained. Recently, several studies proved that Large Language Models (LLMs) effectively capture common-sense knowledge about human activities. However, the effectiveness of LLMs for ADLs recognition in smart home environments still deserves to be investigated. In this work, we propose ADL-LLM, a novel LLM-based ADLs recognition system. ADLLLM transforms raw sensor data into textual representations, that are processed by an LLM to perform zero-shot ADLs recognition. Moreover, in the scenario where a small labeled dataset is available, ADL-LLM can also be empowered with few-shot prompting. We evaluated ADL-LLM on two public datasets, showing its effectiveness in this domain.
Read more7/2/2024

0
Few-Shot Classification of Interactive Activities of Daily Living (InteractADL)
Zane Durante, Robathan Harries, Edward Vendrow, Zelun Luo, Yuta Kyuragi, Kazuki Kozuka, Li Fei-Fei, Ehsan Adeli
Understanding Activities of Daily Living (ADLs) is a crucial step for different applications including assistive robots, smart homes, and healthcare. However, to date, few benchmarks and methods have focused on complex ADLs, especially those involving multi-person interactions in home environments. In this paper, we propose a new dataset and benchmark, InteractADL, for understanding complex ADLs that involve interaction between humans (and objects). Furthermore, complex ADLs occurring in home environments comprise a challenging long-tailed distribution due to the rarity of multi-person interactions, and pose fine-grained visual recognition tasks due to the presence of semantically and visually similar classes. To address these issues, we propose a novel method for fine-grained few-shot video classification called Name Tuning that enables greater semantic separability by learning optimal class name vectors. We show that Name Tuning can be combined with existing prompt tuning strategies to learn the entire input text (rather than only learning the prompt or class names) and demonstrate improved performance for few-shot classification on InteractADL and 4 other fine-grained visual classification benchmarks. For transparency and reproducibility, we release our code at https://github.com/zanedurante/vlm_benchmark.
Read more6/5/2024
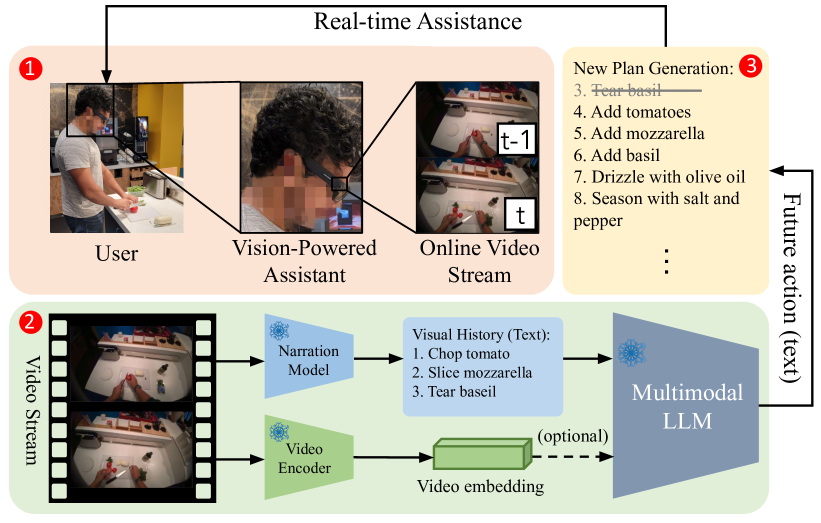
0
User-in-the-loop Evaluation of Multimodal LLMs for Activity Assistance
Mrinal Verghese, Brian Chen, Hamid Eghbalzadeh, Tushar Nagarajan, Ruta Desai
Our research investigates the capability of modern multimodal reasoning models, powered by Large Language Models (LLMs), to facilitate vision-powered assistants for multi-step daily activities. Such assistants must be able to 1) encode relevant visual history from the assistant's sensors, e.g., camera, 2) forecast future actions for accomplishing the activity, and 3) replan based on the user in the loop. To evaluate the first two capabilities, grounding visual history and forecasting in short and long horizons, we conduct benchmarking of two prominent classes of multimodal LLM approaches -- Socratic Models and Vision Conditioned Language Models (VCLMs) on video-based action anticipation tasks using offline datasets. These offline benchmarks, however, do not allow us to close the loop with the user, which is essential to evaluate the replanning capabilities and measure successful activity completion in assistive scenarios. To that end, we conduct a first-of-its-kind user study, with 18 participants performing 3 different multi-step cooking activities while wearing an egocentric observation device called Aria and following assistance from multimodal LLMs. We find that the Socratic approach outperforms VCLMs in both offline and online settings. We further highlight how grounding long visual history, common in activity assistance, remains challenging in current models, especially for VCLMs, and demonstrate that offline metrics do not indicate online performance.
Read more8/14/2024