From Neural Activations to Concepts: A Survey on Explaining Concepts in Neural Networks
2310.11884
0
0
Abstract
In this paper, we review recent approaches for explaining concepts in neural networks. Concepts can act as a natural link between learning and reasoning: once the concepts are identified that a neural learning system uses, one can integrate those concepts with a reasoning system for inference or use a reasoning system to act upon them to improve or enhance the learning system. On the other hand, knowledge can not only be extracted from neural networks but concept knowledge can also be inserted into neural network architectures. Since integrating learning and reasoning is at the core of neuro-symbolic AI, the insights gained from this survey can serve as an important step towards realizing neuro-symbolic AI based on explainable concepts.
Create account to get full access
Overview
- This survey paper explores techniques for explaining the inner workings of neural networks and how they map neural activations to higher-level concepts.
- It covers approaches that aim to interpret the meaning and function of individual neurons, as well as methods that seek to identify the specific concepts learned by neural networks.
- The paper discusses the challenges and limitations of these techniques, and highlights opportunities for further research in the field of explainable artificial intelligence (XAI).
Plain English Explanation
Neural networks have become incredibly powerful at tasks like image recognition and language understanding. However, these "black box" models can be difficult to interpret - it's not always clear how they arrive at their outputs or what they've learned about the world.
This survey paper explores different ways that researchers are trying to "open up" neural networks and explain their inner workings. One approach is to look at the individual neurons in a network and try to understand what concepts or features they might be representing. For example, a neuron might be highly activated when it sees a particular object or type of texture.
Another approach is to try to identify the specific higher-level concepts that a neural network has learned, rather than just looking at individual neurons. This could involve techniques like mapping neural activations to concepts or training the network to be "self-explaining" by directly modeling the concepts it has learned.
These techniques face a number of challenges, like how to define and measure what a "concept" really is. But the paper argues that being able to explain neural networks is crucial for building trust, debugging, and using them responsibly in the real world.
Technical Explanation
The paper begins by outlining the importance of explainable artificial intelligence (XAI), particularly for neural networks which can be difficult to interpret. It then surveys a range of techniques for explaining the inner workings of neural networks:
Neuron-Level Explanations: These approaches aim to interpret the function and meaning of individual neurons in a neural network. Strategies include:
- Using similarities between neuron activations and human-defined concepts
- Identifying "concept neurons" that selectively respond to specific semantic concepts
- Training networks to be "self-explaining" by directly modeling the concepts they learn
Concept-Level Explanations: Rather than focusing on individual neurons, these methods try to identify the higher-level concepts that a neural network has learned. Techniques include:
- Using knowledge graphs to empirically discover the concepts captured by a network
- Leveraging symbolic methods and human-labeled data to surface the "hidden concepts" encoded by neurons
The paper also discusses the challenges and limitations of these approaches, such as the difficulty of precisely defining and measuring abstract "concepts." It highlights the need for further research to develop a unified framework for explaining neural networks.
Critical Analysis
The survey provides a comprehensive overview of the key techniques for explaining neural network activations and concepts. The authors do a good job of highlighting the strengths and weaknesses of the different approaches, such as the challenges of precisely defining and measuring abstract "concepts."
One potential limitation is that the paper focuses primarily on visual recognition tasks, and it's not always clear how well the discussed techniques would generalize to other domains like natural language processing. The authors acknowledge this, but more discussion of cross-domain applicability could be useful.
Additionally, the paper doesn't delve deeply into the societal implications and potential risks of explainable AI systems. As these techniques become more advanced, it will be important to consider issues like algorithmic bias, transparency, and the responsible use of these systems.
Overall, this is a well-written and informative survey that provides a solid foundation for understanding the state of the art in neural network interpretability. The authors successfully convey the technical details in an accessible way, and their critical analysis points to promising avenues for future research.
Conclusion
This survey paper offers a comprehensive overview of the techniques being developed to explain the inner workings of neural networks and how they map neural activations to higher-level concepts. The authors discuss both neuron-level and concept-level approaches, highlighting the strengths, limitations, and challenges of each.
The ability to interpret and explain neural networks is crucial for building trust, debugging, and using these powerful models responsibly. While significant progress has been made, the paper identifies the need for further research to develop a more unified framework for neural network explanation.
As AI systems become increasingly ubiquitous, the field of explainable AI will only grow in importance. This survey provides a valuable resource for understanding the current state of the art and the key research directions in this important and rapidly evolving area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
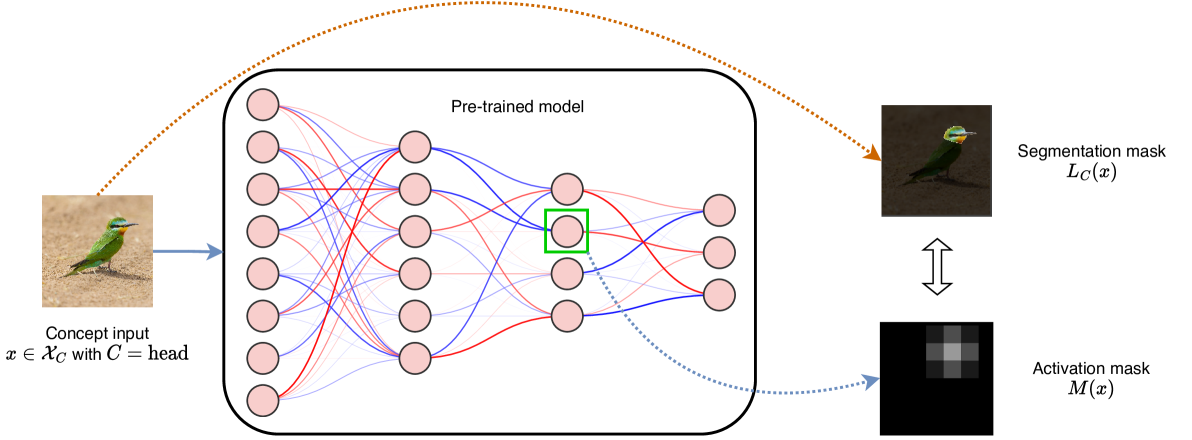
Explaining Explainability: Understanding Concept Activation Vectors
Angus Nicolson, Lisa Schut, J. Alison Noble, Yarin Gal
0
0
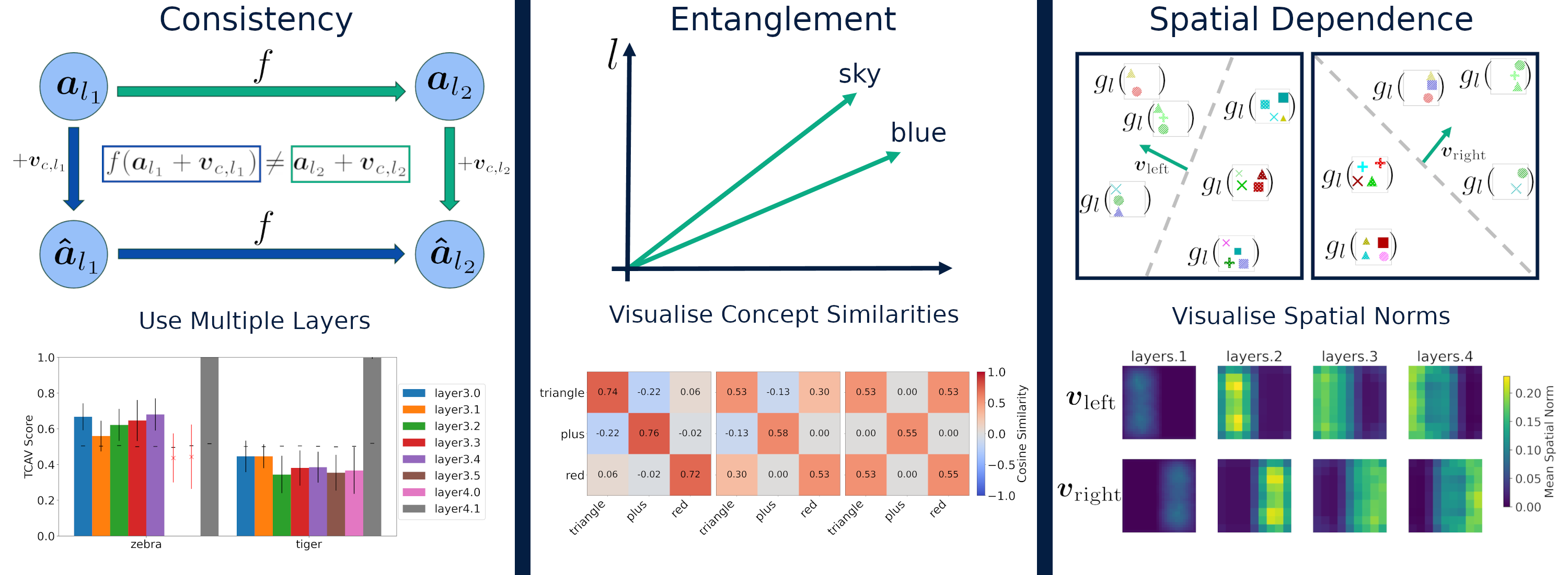
Recent interpretability methods propose using concept-based explanations to translate the internal representations of deep learning models into a language that humans are familiar with: concepts. This requires understanding which concepts are present in the representation space of a neural network. One popular method for finding concepts is Concept Activation Vectors (CAVs), which are learnt using a probe dataset of concept exemplars. In this work, we investigate three properties of CAVs. CAVs may be: (1) inconsistent between layers, (2) entangled with different concepts, and (3) spatially dependent. Each property provides both challenges and opportunities in interpreting models. We introduce tools designed to detect the presence of these properties, provide insight into how they affect the derived explanations, and provide recommendations to minimise their impact. Understanding these properties can be used to our advantage. For example, we introduce spatially dependent CAVs to test if a model is translation invariant with respect to a specific concept and class. Our experiments are performed on ImageNet and a new synthetic dataset, Elements. Elements is designed to capture a known ground truth relationship between concepts and classes. We release this dataset to facilitate further research in understanding and evaluating interpretability methods.
4/8/2024

A Self-explaining Neural Architecture for Generalizable Concept Learning
Sanchit Sinha, Guangzhi Xiong, Aidong Zhang
0
0
With the wide proliferation of Deep Neural Networks in high-stake applications, there is a growing demand for explainability behind their decision-making process. Concept learning models attempt to learn high-level 'concepts' - abstract entities that align with human understanding, and thus provide interpretability to DNN architectures. However, in this paper, we demonstrate that present SOTA concept learning approaches suffer from two major problems - lack of concept fidelity wherein the models fail to learn consistent concepts among similar classes and limited concept interoperability wherein the models fail to generalize learned concepts to new domains for the same task. Keeping these in mind, we propose a novel self-explaining architecture for concept learning across domains which - i) incorporates a new concept saliency network for representative concept selection, ii) utilizes contrastive learning to capture representative domain invariant concepts, and iii) uses a novel prototype-based concept grounding regularization to improve concept alignment across domains. We demonstrate the efficacy of our proposed approach over current SOTA concept learning approaches on four widely used real-world datasets. Empirical results show that our method improves both concept fidelity measured through concept overlap and concept interoperability measured through domain adaptation performance.
5/7/2024

Knowledge graphs for empirical concept retrieval
Lenka Tv{e}tkov'a, Teresa Karen Scheidt, Maria Mandrup Fogh, Ellen Marie Gaunby J{o}rgensen, Finn {AA}rup Nielsen, Lars Kai Hansen
0
0
Concept-based explainable AI is promising as a tool to improve the understanding of complex models at the premises of a given user, viz. as a tool for personalized explainability. An important class of concept-based explainability methods is constructed with empirically defined concepts, indirectly defined through a set of positive and negative examples, as in the TCAV approach (Kim et al., 2018). While it is appealing to the user to avoid formal definitions of concepts and their operationalization, it can be challenging to establish relevant concept datasets. Here, we address this challenge using general knowledge graphs (such as, e.g., Wikidata or WordNet) for comprehensive concept definition and present a workflow for user-driven data collection in both text and image domains. The concepts derived from knowledge graphs are defined interactively, providing an opportunity for personalization and ensuring that the concepts reflect the user's intentions. We test the retrieved concept datasets on two concept-based explainability methods, namely concept activation vectors (CAVs) and concept activation regions (CARs) (Crabbe and van der Schaar, 2022). We show that CAVs and CARs based on these empirical concept datasets provide robust and accurate explanations. Importantly, we also find good alignment between the models' representations of concepts and the structure of knowledge graphs, i.e., human representations. This supports our conclusion that knowledge graph-based concepts are relevant for XAI.
4/11/2024
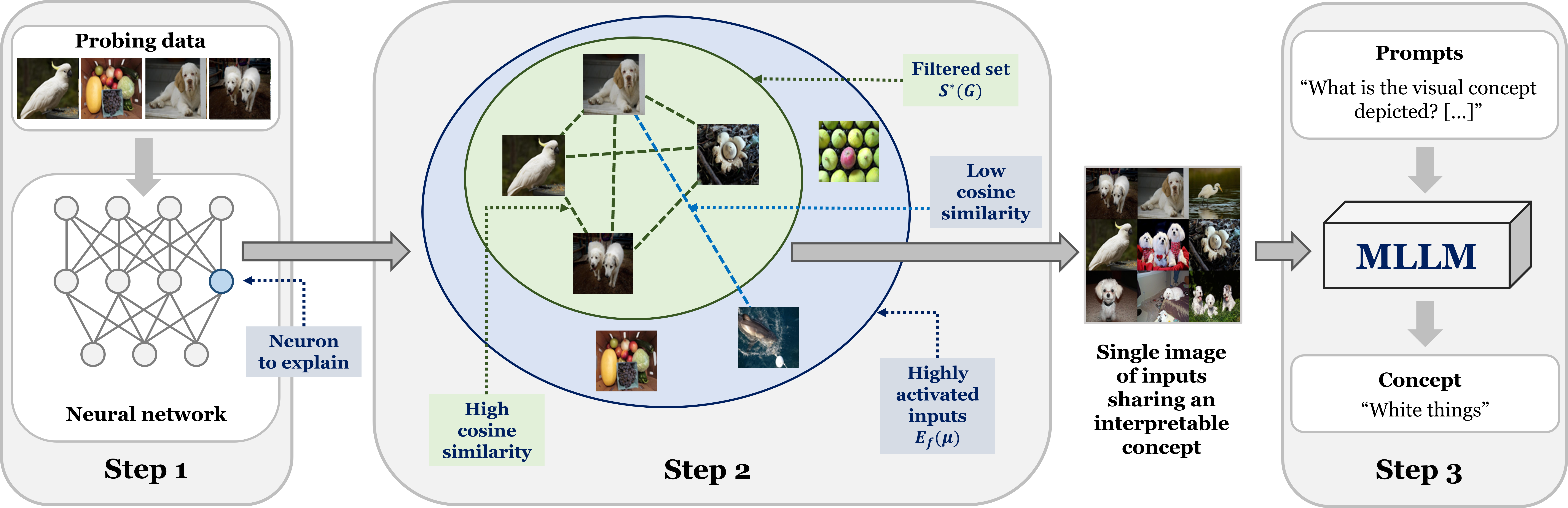
LLM-assisted Concept Discovery: Automatically Identifying and Explaining Neuron Functions
Nhat Hoang-Xuan, Minh Vu, My T. Thai
0
0
Providing textual concept-based explanations for neurons in deep neural networks (DNNs) is of importance in understanding how a DNN model works. Prior works have associated concepts with neurons based on examples of concepts or a pre-defined set of concepts, thus limiting possible explanations to what the user expects, especially in discovering new concepts. Furthermore, defining the set of concepts requires manual work from the user, either by directly specifying them or collecting examples. To overcome these, we propose to leverage multimodal large language models for automatic and open-ended concept discovery. We show that, without a restricted set of pre-defined concepts, our method gives rise to novel interpretable concepts that are more faithful to the model's behavior. To quantify this, we validate each concept by generating examples and counterexamples and evaluating the neuron's response on this new set of images. Collectively, our method can discover concepts and simultaneously validate them, providing a credible automated tool to explain deep neural networks.
6/14/2024