LLM Evaluators Recognize and Favor Their Own Generations
2404.13076
0
0
Abstract
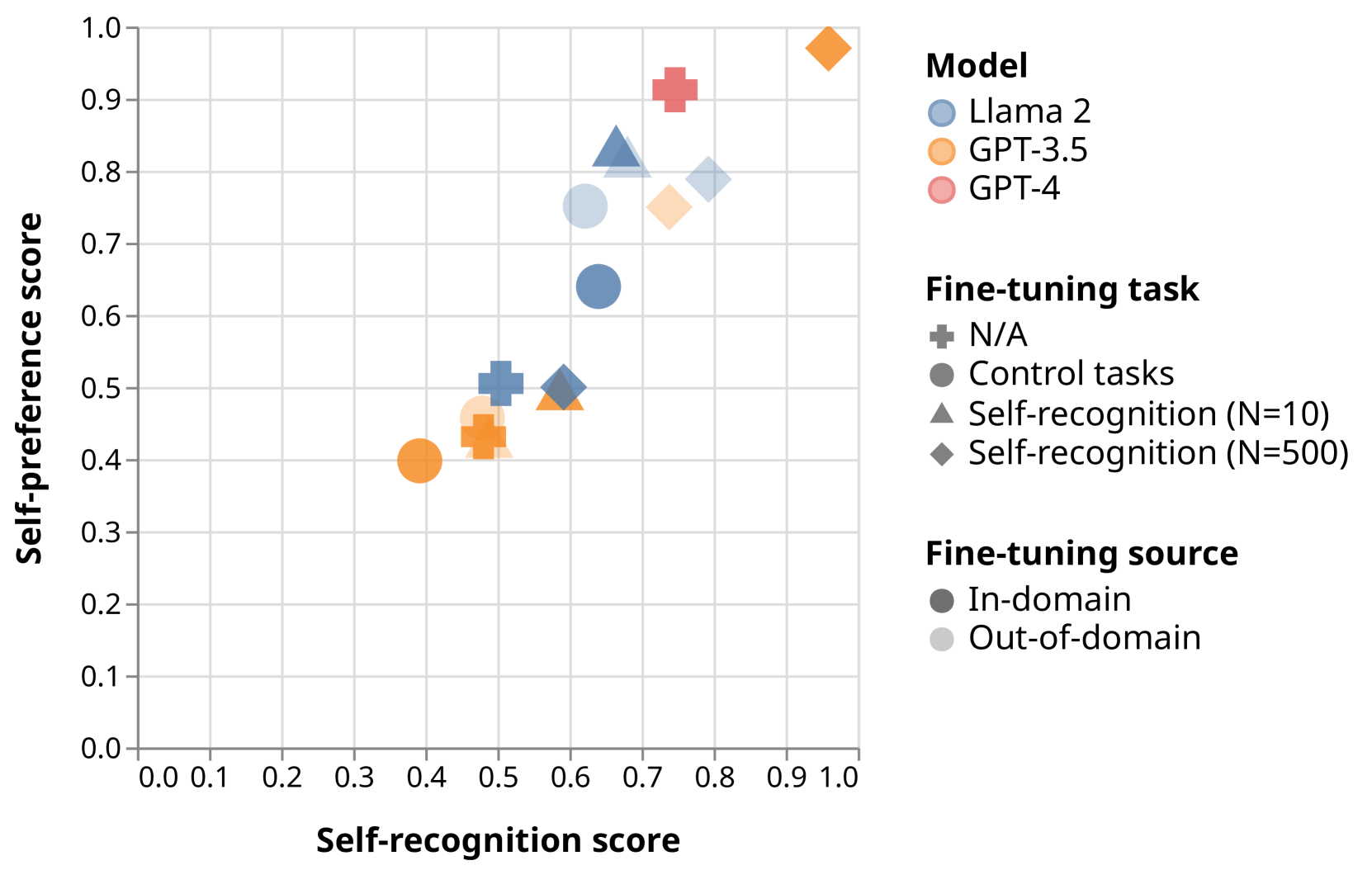
Self-evaluation using large language models (LLMs) has proven valuable not only in benchmarking but also methods like reward modeling, constitutional AI, and self-refinement. But new biases are introduced due to the same LLM acting as both the evaluator and the evaluatee. One such bias is self-preference, where an LLM evaluator scores its own outputs higher than others' while human annotators consider them of equal quality. But do LLMs actually recognize their own outputs when they give those texts higher scores, or is it just a coincidence? In this paper, we investigate if self-recognition capability contributes to self-preference. We discover that, out of the box, LLMs such as GPT-4 and Llama 2 have non-trivial accuracy at distinguishing themselves from other LLMs and humans. By fine-tuning LLMs, we discover a linear correlation between self-recognition capability and the strength of self-preference bias; using controlled experiments, we show that the causal explanation resists straightforward confounders. We discuss how self-recognition can interfere with unbiased evaluations and AI safety more generally.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers investigate whether large language model (LLM) evaluators exhibit a preference for LLMs from their own generation.
- They define and measure "self-preference" and "self-recognition" to quantify this bias.
- The study suggests that evaluators tend to favor their own generation of LLMs, potentially leading to skewed assessments and development priorities.
Plain English Explanation
Researchers have noticed that the people who evaluate large language models (LLMs) - the powerful AI systems that can understand and generate human-like text - may have a bias towards the LLMs that are similar to their own generation. This means that evaluators might give higher ratings or prefer LLMs that are developed around the same time as the evaluators, rather than evaluating all LLMs objectively.
To understand this bias, the researchers defined two key concepts: "self-preference" and "self-recognition". Self-preference is when evaluators tend to rate LLMs from their own generation higher than LLMs from other generations. Self-recognition is when evaluators can more accurately identify LLMs from their own generation compared to other generations.
The researchers conducted experiments to measure these biases and found evidence that evaluators do indeed exhibit self-preference and self-recognition, potentially leading to skewed assessments of LLMs and prioritizing the development of LLMs that cater to the evaluators' own generation rather than the needs of the broader population.
This is an important finding because it suggests that the process of evaluating and developing LLMs may be influenced by the personal biases of the evaluators, which could potentially lead to the creation of LLMs that are not as broadly useful or representative as they could be.
Technical Explanation
The researchers used a combination of human evaluations and automated evaluations to assess the presence of self-preference and self-recognition in LLM evaluators. They collected datasets of LLM outputs spanning different generations and had both human and automated evaluators assess the quality of the outputs.
To measure self-preference, the researchers analyzed the evaluation scores given by the evaluators and looked for a systematic bias towards LLMs from the same generation as the evaluators. To measure self-recognition, they examined the evaluators' ability to accurately identify the generation of the LLMs they were assessing.
The results of their experiments, as reported in the paper, suggest that both self-preference and self-recognition are present in LLM evaluators, indicating that the development and deployment of LLMs may be influenced by the personal biases of the evaluators. This finding aligns with previous research on the challenges of aligning LLM evaluation with broader societal needs.
Critical Analysis
The paper acknowledges several limitations of the study, including the potential for confounding factors in the evaluation datasets and the need for further research to understand the underlying causes of the observed biases.
Additionally, the paper does not address the potential implications of these biases on the real-world deployment and use of LLMs, or how the research community and industry could work to mitigate these issues. Further research may be needed to explore these aspects in more depth.
It is also worth considering whether the observed biases are specific to the LLM evaluation context or if they reflect more general human tendencies to favor information and perspectives that are familiar or similar to one's own experiences, as suggested by prior work.
Conclusion
This paper presents evidence that LLM evaluators exhibit a systematic bias towards LLMs from their own generation, both in terms of preferring the performance of these LLMs and being better able to recognize them. This finding raises important questions about the objectivity and fairness of the LLM evaluation process, which is crucial for the development and deployment of these powerful AI systems in a way that serves the needs of all members of society.
The research highlights the need for greater awareness and mitigation of evaluator biases in the LLM development ecosystem, to ensure that the advancement of these technologies is not unduly skewed by the personal perspectives of the individuals responsible for assessing them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Deceiving to Enlighten: Coaxing LLMs to Self-Reflection for Enhanced Bias Detection and Mitigation
Ruoxi Cheng, Haoxuan Ma, Shuirong Cao, Tianyu Shi
0
0
Biases and stereotypes in Large Language Models (LLMs) can have negative implications for user experience and societal outcomes. Current approaches to bias mitigation like Reinforcement Learning from Human Feedback (RLHF) rely on costly manual feedback. While LLMs have the capability to understand logic and identify biases in text, they often struggle to effectively acknowledge and address their own biases due to factors such as prompt influences, internal mechanisms, and policies. We found that informing LLMs that the content they generate is not their own and questioning them about potential biases in the text can significantly enhance their recognition and improvement capabilities regarding biases. Based on this finding, we propose RLRF (Reinforcement Learning from Reflection through Debates as Feedback), replacing human feedback with AI for bias mitigation. RLRF engages LLMs in multi-role debates to expose biases and gradually reduce biases in each iteration using a ranking scoring mechanism. The dialogue are then used to create a dataset with high-bias and low-bias instances to train the reward model in reinforcement learning. This dataset can be generated by the same LLMs for self-reflection or a superior LLMs guiding the former in a student-teacher mode to enhance its logical reasoning abilities. Experimental results demonstrate the significant effectiveness of our approach in bias reduction.
4/30/2024
![SELF-[IN]CORRECT: LLMs Struggle with Refining Self-Generated Responses](https://arxiv.org/html/2404.04298v1/x1.png)
SELF-[IN]CORRECT: LLMs Struggle with Refining Self-Generated Responses
Dongwei Jiang, Jingyu Zhang, Orion Weller, Nathaniel Weir, Benjamin Van Durme, Daniel Khashabi
0
0
Can LLMs continually improve their previous outputs for better results? An affirmative answer would require LLMs to be better at discriminating among previously-generated alternatives, than generating initial responses. We explore the validity of this hypothesis in practice. We first introduce a unified framework that allows us to compare the generative and discriminative capability of any model on any task. Then, in our resulting experimental analysis of several LLMs, we do not observe the performance of those models on discrimination to be reliably better than generation. We hope these findings inform the growing literature on self-improvement AI systems.
4/9/2024
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
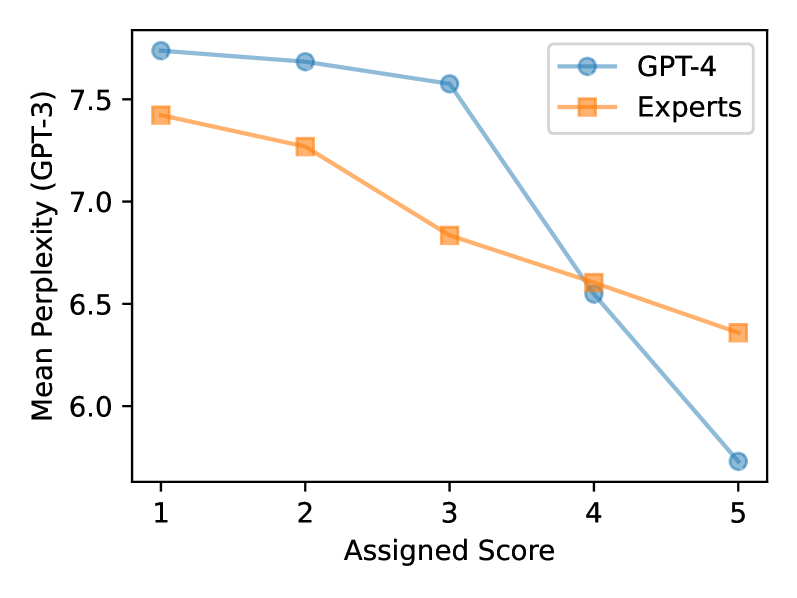
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024
➖
LLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked
Mansi Phute, Alec Helbling, Matthew Hull, ShengYun Peng, Sebastian Szyller, Cory Cornelius, Duen Horng Chau
0
0
Large language models (LLMs) are popular for high-quality text generation but can produce harmful content, even when aligned with human values through reinforcement learning. Adversarial prompts can bypass their safety measures. We propose LLM Self Defense, a simple approach to defend against these attacks by having an LLM screen the induced responses. Our method does not require any fine-tuning, input preprocessing, or iterative output generation. Instead, we incorporate the generated content into a pre-defined prompt and employ another instance of an LLM to analyze the text and predict whether it is harmful. We test LLM Self Defense on GPT 3.5 and Llama 2, two of the current most prominent LLMs against various types of attacks, such as forcefully inducing affirmative responses to prompts and prompt engineering attacks. Notably, LLM Self Defense succeeds in reducing the attack success rate to virtually 0 using both GPT 3.5 and Llama 2. The code is publicly available at https://github.com/poloclub/llm-self-defense
5/3/2024