Load Balancing in Federated Learning

0

Sign in to get full access
Overview
- Examines the issue of load balancing in federated learning, where multiple devices collaborate to train a shared machine learning model
- Proposes a new algorithm called FlexTL to address challenges with existing load balancing approaches
- Evaluates FlexTL's performance through simulations and real-world experiments
Plain English Explanation
Federated learning is a technique where many devices, like smartphones or IoT sensors, work together to train a shared machine learning model. This can be more efficient than having a central server do all the training. However, ensuring the work is evenly distributed across the devices, or "load balanced," is a challenge.
The paper introduces a new algorithm called FlexTL that aims to improve load balancing in federated learning. It does this by dynamically adjusting the amount of work assigned to each device based on factors like the device's computing power and network connection speed. This helps to prevent slower devices from holding back the overall training process.
The researchers tested FlexTL through computer simulations as well as real-world experiments involving actual devices. The results suggest FlexTL can outperform existing load balancing approaches, leading to faster model training times without compromising accuracy.
Technical Explanation
The paper proposes a new load balancing algorithm called FlexTL (Flexible Task Allocation) for federated learning. Existing approaches often use static task allocation, where each device is assigned a fixed amount of work. FlexTL instead dynamically adjusts the workload for each device based on factors like the device's computing capability and network conditions.
The key idea behind FlexTL is to estimate each device's training time - the time it takes for a device to complete its assigned training tasks. FlexTL then uses these time estimates to allocate more work to faster devices and less to slower ones. This helps mitigate the "straggler" problem, where slow devices hold back the overall training progress.
The paper describes the mathematical formulation of the FlexTL algorithm and how it can be implemented in a federated learning system. It also presents an extensive evaluation, including simulations and real-world experiments on diverse datasets and hardware configurations. The results show FlexTL can achieve up to 2x speedups over static load balancing approaches while maintaining model performance.
Critical Analysis
The paper provides a thorough and well-designed study of the load balancing problem in federated learning. The proposed FlexTL algorithm appears to be a significant improvement over existing techniques, with the potential to greatly accelerate federated training in real-world scenarios.
One limitation mentioned in the paper is that FlexTL relies on accurate estimates of each device's training time. In practice, these estimates may be difficult to obtain, especially for heterogeneous device configurations. The authors suggest exploring techniques like online learning to adaptively refine the time estimates, but further research may be needed in this area.
Additionally, the paper focuses on a centralized federated learning setting. An interesting direction for future work could be to investigate how FlexTL or similar load balancing approaches could be extended to decentralized federated learning architectures, where devices coordinate without a central coordinator.
Overall, the FlexTL algorithm presented in this paper represents an important contribution to the field of federated learning, with the potential to significantly improve the efficiency and scalability of this distributed training paradigm.
Conclusion
This paper addresses the critical challenge of load balancing in federated learning, where multiple devices collaborate to train a shared machine learning model. The authors propose a new algorithm called FlexTL that dynamically adjusts the workload assigned to each device based on its computing capabilities and network conditions.
Through extensive simulations and real-world experiments, the paper demonstrates that FlexTL can achieve substantial speedups in federated training times compared to existing static load balancing approaches, without compromising model performance. This work represents an important step forward in enabling efficient and scalable federated learning systems, with potential applications in areas like edge computing and distributed forecasting.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Load Balancing in Federated Learning
Alireza Javani, Zhiying Wang
Federated Learning (FL) is a decentralized machine learning framework that enables learning from data distributed across multiple remote devices, enhancing communication efficiency and data privacy. Due to limited communication resources, a scheduling policy is often applied to select a subset of devices for participation in each FL round. The scheduling process confronts significant challenges due to the need for fair workload distribution, efficient resource utilization, scalability in environments with numerous edge devices, and statistically heterogeneous data across devices. This paper proposes a load metric for scheduling policies based on the Age of Information and addresses the above challenges by minimizing the load metric variance across the clients. Furthermore, a decentralized Markov scheduling policy is presented, that ensures a balanced workload distribution while eliminating the management overhead irrespective of the network size due to independent client decision-making. We establish the optimal parameters of the Markov chain model and validate our approach through simulations. The results demonstrate that reducing the load metric variance not only promotes fairness and improves operational efficiency, but also enhances the convergence rate of the learning models.
Read more8/2/2024

0
Efficient Data Distribution Estimation for Accelerated Federated Learning
Yuanli Wang, Lei Huang
Federated Learning(FL) is a privacy-preserving machine learning paradigm where a global model is trained in-situ across a large number of distributed edge devices. These systems are often comprised of millions of user devices and only a subset of available devices can be used for training in each epoch. Designing a device selection strategy is challenging, given that devices are highly heterogeneous in both their system resources and training data. This heterogeneity makes device selection very crucial for timely model convergence and sufficient model accuracy. To tackle the FL client heterogeneity problem, various client selection algorithms have been developed, showing promising performance improvement in terms of model coverage and accuracy. In this work, we study the overhead of client selection algorithms in a large scale FL environment. Then we propose an efficient data distribution summary calculation algorithm to reduce the overhead in a real-world large scale FL environment. The evaluation shows that our proposed solution could achieve up to 30x reduction in data summary time, and up to 360x reduction in clustering time.
Read more6/5/2024
0
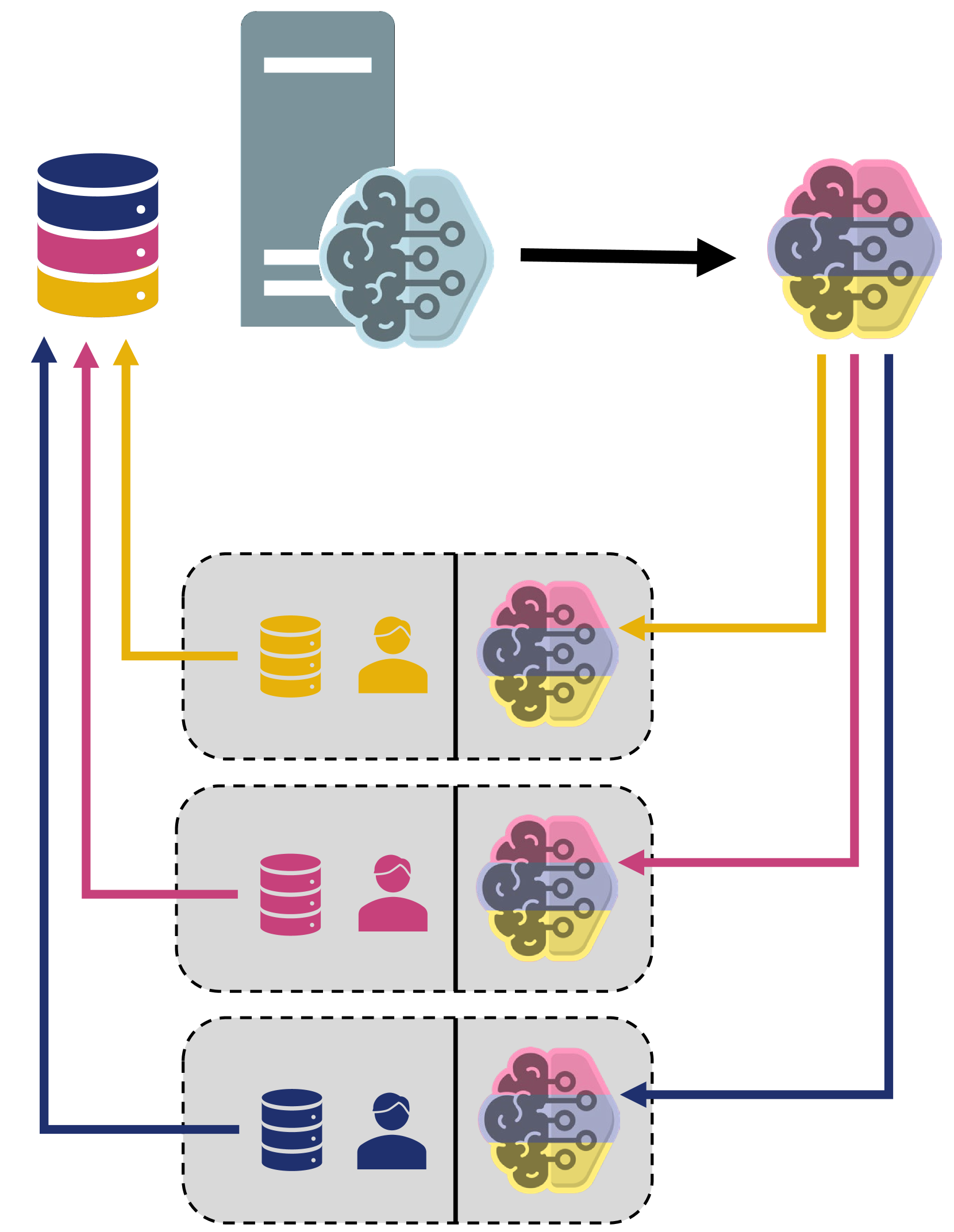
Federated Learning: A Cutting-Edge Survey of the Latest Advancements and Applications
Azim Akhtarshenas, Mohammad Ali Vahedifar, Navid Ayoobi, Behrouz Maham, Tohid Alizadeh, Sina Ebrahimi, David L'opez-P'erez
Robust machine learning (ML) models can be developed by leveraging large volumes of data and distributing the computational tasks across numerous devices or servers. Federated learning (FL) is a technique in the realm of ML that facilitates this goal by utilizing cloud infrastructure to enable collaborative model training among a network of decentralized devices. Beyond distributing the computational load, FL targets the resolution of privacy issues and the reduction of communication costs simultaneously. To protect user privacy, FL requires users to send model updates rather than transmitting large quantities of raw and potentially confidential data. Specifically, individuals train ML models locally using their own data and then upload the results in the form of weights and gradients to the cloud for aggregation into the global model. This strategy is also advantageous in environments with limited bandwidth or high communication costs, as it prevents the transmission of large data volumes. With the increasing volume of data and rising privacy concerns, alongside the emergence of large-scale ML models like Large Language Models (LLMs), FL presents itself as a timely and relevant solution. It is therefore essential to review current FL algorithms to guide future research that meets the rapidly evolving ML demands. This survey provides a comprehensive analysis and comparison of the most recent FL algorithms, evaluating them on various fronts including mathematical frameworks, privacy protection, resource allocation, and applications. Beyond summarizing existing FL methods, this survey identifies potential gaps, open areas, and future challenges based on the performance reports and algorithms used in recent studies. This survey enables researchers to readily identify existing limitations in the FL field for further exploration.
Read more5/28/2024

0
A Framework for testing Federated Learning algorithms using an edge-like environment
Felipe Machado Schwanck, Marcos Tomazzoli Leipnitz, Joel Lu'is Carbonera, Juliano Araujo Wickboldt
Federated Learning (FL) is a machine learning paradigm in which many clients cooperatively train a single centralized model while keeping their data private and decentralized. FL is commonly used in edge computing, which involves placing computer workloads (both hardware and software) as close as possible to the edge, where the data is being created and where actions are occurring, enabling faster response times, greater data privacy, and reduced data transfer costs. However, due to the heterogeneous data distributions/contents of clients, it is non-trivial to accurately evaluate the contributions of local models in global centralized model aggregation. This is an example of a major challenge in FL, commonly known as data imbalance or class imbalance. In general, testing and assessing FL algorithms can be a very difficult and complex task due to the distributed nature of the systems. In this work, a framework is proposed and implemented to assess FL algorithms in a more easy and scalable way. This framework is evaluated over a distributed edge-like environment managed by a container orchestration platform (i.e. Kubernetes).
Read more7/19/2024