Local Action-Guided Motion Diffusion Model for Text-to-Motion Generation

0

Sign in to get full access
Overview
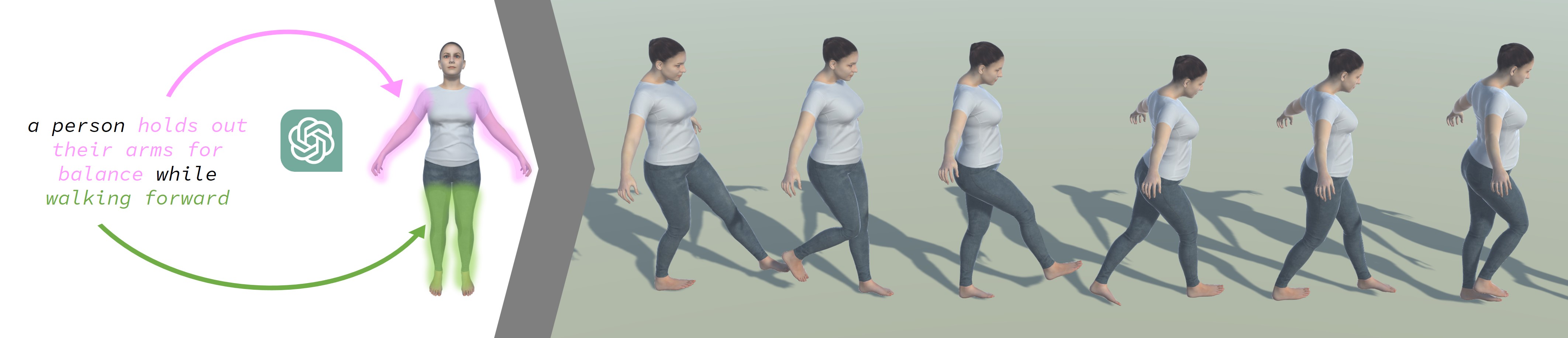
- This paper proposes a novel text-to-motion generation model called the Local Action-Guided Motion Diffusion Model (LAGM).
- The model uses a diffusion-based approach to generate realistic human motion sequences from text descriptions.
- The key innovation is the incorporation of local action guidance, which helps the model learn the spatial and temporal relationships between different body parts during motion.
Plain English Explanation
The researchers have developed a new system that can take a text description and use it to generate a realistic animation of a person moving and performing actions. This is a challenging task because there are complex relationships between how different parts of the body move together in a coordinated way.
The core of their approach is a diffusion model, which is a type of machine learning model that can generate new data by learning from examples. The diffusion model is trained on a large dataset of motion capture data, which records the movements of real people.
The key innovation in this work is the addition of "local action guidance." This means the model not only looks at the overall text description, but also learns about how individual body parts should move in relation to each other during different actions. This helps the model generate more realistic and coordinated motions.
For example, if the text description says "the person is waving their hand," the local action guidance would help the model understand that the arm and hand need to move together in a specific pattern to realistically perform a waving motion. This level of detail is important for creating natural-looking animations from text.
Overall, this research represents an important step forward in the field of text-to-motion generation, which has applications in areas like virtual reality, animation, and robotics. By incorporating local action guidance, the LAGM model is able to generate more lifelike and coherent human motions from text descriptions.
Technical Explanation
The proposed Local Action-Guided Motion Diffusion Model (LAGM) is a text-to-motion generation system that uses a diffusion-based approach. Diffusion models work by learning to gradually transform simple random noise into realistic data, in this case human motion sequences.
The key innovation in LAGM is the incorporation of local action guidance. This means the model not only conditions the motion generation on the overall text description, but also learns to capture the relationships between the movements of individual body parts. This is achieved by introducing an additional loss term that encourages the model to accurately predict the motion of each body part given the current text input and previous motion states.
The LAGM architecture consists of an encoder network that maps the text description into a latent representation, and a diffusion-based decoder network that generates the motion sequence. The local action guidance is implemented by applying an additional neural network module that predicts the movements of each joint at each timestep.
The researchers evaluated LAGM on a large dataset of human motion capture data paired with text descriptions. They show that the local action guidance significantly improves the quality and realism of the generated motions compared to previous diffusion-based text-to-motion and motion style transfer approaches. The model is also able to generate motions for unseen text descriptions, demonstrating its ability to generalize.
Critical Analysis
The LAGM model represents an important advancement in the field of text-to-3D human motion generation, but there are some potential limitations and areas for further research:
-
The model was trained and evaluated on a relatively limited dataset of motion capture data, which may constrain its ability to generalize to more diverse human motions. Expanding the training dataset could help improve the model's versatility.
-
The local action guidance is implemented as an additional neural network module, which increases the model complexity and training time. Exploring more efficient ways to incorporate this guidance could make the approach more scalable.
-
The paper does not provide a detailed analysis of the types of motions the model struggles with or the common failure modes. A more thorough error analysis could help identify areas for future improvements.
-
While the generated motions are generally realistic, there may still be room for improvement in terms of capturing the subtle nuances and dynamics of human movement. Incorporating additional priors or constraints related to biomechanics and motor control could potentially enhance the realism further.
Overall, the LAGM model represents a promising step forward in text-to-motion generation research. The use of local action guidance is a novel and insightful approach that could inspire future work in this area.
Conclusion
The Local Action-Guided Motion Diffusion Model (LAGM) proposed in this paper is a significant advancement in the field of text-to-motion generation. By incorporating local action guidance, the model is able to generate more realistic and coordinated human motions from text descriptions, outperforming previous diffusion-based approaches.
The key innovation of LAGM is the way it models the relationships between the movements of individual body parts, which is crucial for creating natural-looking animations. This level of detail and spatial-temporal understanding is an important step towards building more versatile and intelligent text-to-motion systems.
Overall, this research has the potential to impact a wide range of applications, such as virtual reality, animation, and robotics, by enabling more intuitive and expressive ways of controlling and generating human motion from high-level language input. As the field continues to evolve, we can expect to see further advancements in text-to-motion generation that push the boundaries of what is possible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Local Action-Guided Motion Diffusion Model for Text-to-Motion Generation
Peng Jin, Hao Li, Zesen Cheng, Kehan Li, Runyi Yu, Chang Liu, Xiangyang Ji, Li Yuan, Jie Chen
Text-to-motion generation requires not only grounding local actions in language but also seamlessly blending these individual actions to synthesize diverse and realistic global motions. However, existing motion generation methods primarily focus on the direct synthesis of global motions while neglecting the importance of generating and controlling local actions. In this paper, we propose the local action-guided motion diffusion model, which facilitates global motion generation by utilizing local actions as fine-grained control signals. Specifically, we provide an automated method for reference local action sampling and leverage graph attention networks to assess the guiding weight of each local action in the overall motion synthesis. During the diffusion process for synthesizing global motion, we calculate the local-action gradient to provide conditional guidance. This local-to-global paradigm reduces the complexity associated with direct global motion generation and promotes motion diversity via sampling diverse actions as conditions. Extensive experiments on two human motion datasets, i.e., HumanML3D and KIT, demonstrate the effectiveness of our method. Furthermore, our method provides flexibility in seamlessly combining various local actions and continuous guiding weight adjustment, accommodating diverse user preferences, which may hold potential significance for the community. The project page is available at https://jpthu17.github.io/GuidedMotion-project/.
Read more7/16/2024
0
LGTM: Local-to-Global Text-Driven Human Motion Diffusion Model
Haowen Sun, Ruikun Zheng, Haibin Huang, Chongyang Ma, Hui Huang, Ruizhen Hu
In this paper, we introduce LGTM, a novel Local-to-Global pipeline for Text-to-Motion generation. LGTM utilizes a diffusion-based architecture and aims to address the challenge of accurately translating textual descriptions into semantically coherent human motion in computer animation. Specifically, traditional methods often struggle with semantic discrepancies, particularly in aligning specific motions to the correct body parts. To address this issue, we propose a two-stage pipeline to overcome this challenge: it first employs large language models (LLMs) to decompose global motion descriptions into part-specific narratives, which are then processed by independent body-part motion encoders to ensure precise local semantic alignment. Finally, an attention-based full-body optimizer refines the motion generation results and guarantees the overall coherence. Our experiments demonstrate that LGTM gains significant improvements in generating locally accurate, semantically-aligned human motion, marking a notable advancement in text-to-motion applications. Code and data for this paper are available at https://github.com/L-Sun/LGTM
Read more5/7/2024
🔄
0
On-the-fly Learning to Transfer Motion Style with Diffusion Models: A Semantic Guidance Approach
Lei Hu, Zihao Zhang, Yongjing Ye, Yiwen Xu, Shihong Xia
3D Human motion style transfer is a fundamental problem in computer graphic and animation processing. Existing AdaIN- based methods necessitate datasets with balanced style distribution and content/style labels to train the clustered latent space. However, we may encounter a single unseen style example in practical scenarios, but not in sufficient quantity to constitute a style cluster for AdaIN-based methods. Therefore, in this paper, we propose a novel two-stage framework for few-shot style transfer learning based on the diffusion model. Specifically, in the first stage, we pre-train a diffusion-based text-to-motion model as a generative prior so that it can cope with various content motion inputs. In the second stage, based on the single style example, we fine-tune the pre-trained diffusion model in a few-shot manner to make it capable of style transfer. The key idea is regarding the reverse process of diffusion as a motion-style translation process since the motion styles can be viewed as special motion variations. During the fine-tuning for style transfer, a simple yet effective semantic-guided style transfer loss coordinated with style example reconstruction loss is introduced to supervise the style transfer in CLIP semantic space. The qualitative and quantitative evaluations demonstrate that our method can achieve state-of-the-art performance and has practical applications.
Read more8/9/2024

0
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
Seunggeun Chi, Hyung-gun Chi, Hengbo Ma, Nakul Agarwal, Faizan Siddiqui, Karthik Ramani, Kwonjoon Lee
We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of generating multi-motion sequences, ensuring seamless transitions of motions and coherence across a series of actions. The strength of M2D2M lies in its dynamic transition probability within the discrete diffusion model, which adapts transition probabilities based on the proximity between motion tokens, encouraging mixing between different modes. Complemented by a two-phase sampling strategy that includes independent and joint denoising steps, M2D2M effectively generates long-term, smooth, and contextually coherent human motion sequences, utilizing a model trained for single-motion generation. Extensive experiments demonstrate that M2D2M surpasses current state-of-the-art benchmarks for motion generation from text descriptions, showcasing its efficacy in interpreting language semantics and generating dynamic, realistic motions.
Read more7/22/2024