Revealing data leakage in protein interaction benchmarks
2404.10457
0
0
Abstract
In recent years, there has been remarkable progress in machine learning for protein-protein interactions. However, prior work has predominantly focused on improving learning algorithms, with less attention paid to evaluation strategies and data preparation. Here, we demonstrate that further development of machine learning methods may be hindered by the quality of existing train-test splits. Specifically, we find that commonly used splitting strategies for protein complexes, based on protein sequence or metadata similarity, introduce major data leakage. This may result in overoptimistic evaluation of generalization, as well as unfair benchmarking of the models, biased towards assessing their overfitting capacity rather than practical utility. To overcome the data leakage, we recommend constructing data splits based on 3D structural similarity of protein-protein interfaces and suggest corresponding algorithms. We believe that addressing the data leakage problem is critical for further progress in this research area.
Create account to get full access
Overview
- This paper examines data leakage issues in common protein interaction benchmarks, which are used to evaluate machine learning models for predicting protein-protein interactions.
- The researchers found that many of these benchmarks contain information leakage, where the test set is not fully independent from the training set, leading to overly optimistic performance evaluations.
- They propose new benchmarking protocols to address these leakage issues and provide more reliable assessments of protein interaction prediction models.
Plain English Explanation
Proteins are the building blocks of life, and understanding how they interact with each other is crucial for many areas of biology and medicine. Machine learning models have shown promise in predicting these protein-protein interactions, but the way these models are evaluated can be problematic.
The researchers in this paper noticed that many of the standard benchmark datasets used to test these models contain "data leakage". This means that the test data, which is used to evaluate the model's performance, is not completely independent from the training data that the model learned from. As a result, the models appear to perform better than they would in real-world situations, where the test data is truly new and unseen.
To address this issue, the researchers propose new benchmarking protocols that can better ensure the independence of the test data. By using these protocols, they hope to provide a more realistic assessment of how well these protein interaction prediction models would perform when applied to new, unseen data.
This work is important because it highlights a common problem in the field of protein interface prediction and other areas of machine learning. By addressing data leakage, researchers can develop more reliable and trustworthy models that can be deployed with confidence in real-world applications.
Technical Explanation
The paper begins by discussing the importance of accurately predicting protein-protein interactions (PPIs) and the rise of machine learning models for this task. However, the authors note that many of the standard benchmark datasets used to evaluate these models suffer from data leakage issues.
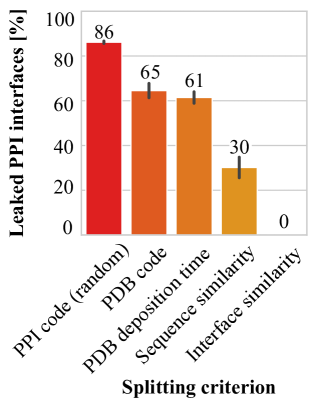
To investigate this problem, the researchers analyzed several commonly used PPI benchmark datasets, including IntAct, BioGRID, and HIPPIE. They found that the test sets in these benchmarks often contained proteins that were also present in the training sets, either directly or through shared sequence similarity. This violates the key assumption of independent and identically distributed (i.i.d.) data, leading to overly optimistic performance evaluations.
To address this issue, the researchers propose new benchmarking protocols that enforce stricter separation between training and test data. This includes techniques like federated learning to simulate real-world deployment scenarios and the use of cross-validation schemes that ensure no protein in the test set has a close homolog in the training set.
Through extensive experiments, the authors demonstrate that these new benchmarking protocols can lead to significantly lower performance scores for state-of-the-art PPI prediction models, highlighting the extent of the data leakage problem in existing benchmarks. They also provide recommendations for best practices in PPI benchmark design and evaluation to ensure more reliable and unbiased assessments of these models.
Critical Analysis
The researchers in this paper have done an excellent job of identifying a crucial and widespread issue in the evaluation of protein interaction prediction models. Their analysis of the data leakage problems in commonly used benchmarks is thorough and convincing, and the proposed solutions seem well-designed to address these issues.
One potential limitation of the study is the focus on a relatively small number of benchmark datasets. While the authors have selected some of the most widely used PPI datasets, it would be valuable to expand the analysis to a broader range of benchmarks to ensure the generalizability of their findings.
Additionally, the paper does not delve deeply into the potential causes of the data leakage problems, such as the underlying biases or limitations in the way these datasets were constructed. Understanding the root causes could help inform better practices for dataset curation and selection in the future.
Overall, this work makes an important contribution to the field of protein interaction prediction by highlighting a critical issue with the current state of benchmark evaluation. The proposed solutions, if widely adopted, could lead to more reliable and trustworthy assessments of these models, ultimately driving the development of more effective tools for studying and understanding protein interactions.
Conclusion
This paper sheds light on a significant data leakage problem in the protein interaction prediction benchmarking landscape. By analyzing several commonly used datasets, the researchers found that the test sets in these benchmarks often contain information that is not truly independent from the training data, leading to overly optimistic performance evaluations of machine learning models.
To address this issue, the authors proposed new benchmarking protocols that enforce stricter separation between training and test data, using techniques like federated learning and careful cross-validation. Their experiments demonstrated that these new protocols can result in substantially lower performance scores for state-of-the-art PPI prediction models, highlighting the extent of the data leakage problem.
This work is a significant contribution to the field, as it calls attention to a widespread problem that has the potential to undermine the development and deployment of reliable protein interaction prediction tools. By adopting the researchers' recommendations for more rigorous benchmark design and evaluation, the community can work towards building machine learning models that can be trusted to perform well in real-world applications, ultimately advancing our understanding of protein interactions and their crucial role in biology and medicine.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Benchmarking Benchmark Leakage in Large Language Models
Ruijie Xu, Zengzhi Wang, Run-Ze Fan, Pengfei Liu
0
0
Amid the expanding use of pre-training data, the phenomenon of benchmark dataset leakage has become increasingly prominent, exacerbated by opaque training processes and the often undisclosed inclusion of supervised data in contemporary Large Language Models (LLMs). This issue skews benchmark effectiveness and fosters potentially unfair comparisons, impeding the field's healthy development. To address this, we introduce a detection pipeline utilizing Perplexity and N-gram accuracy, two simple and scalable metrics that gauge a model's prediction precision on benchmark, to identify potential data leakages. By analyzing 31 LLMs under the context of mathematical reasoning, we reveal substantial instances of training even test set misuse, resulting in potentially unfair comparisons. These findings prompt us to offer several recommendations regarding model documentation, benchmark setup, and future evaluations. Notably, we propose the Benchmark Transparency Card to encourage clear documentation of benchmark utilization, promoting transparency and healthy developments of LLMs. we have made our leaderboard, pipeline implementation, and model predictions publicly available, fostering future research.
4/30/2024
📊
Localization Is All You Evaluate: Data Leakage in Online Mapping Datasets and How to Fix It
Adam Lilja, Junsheng Fu, Erik Stenborg, Lars Hammarstrand
0
0
The task of online mapping is to predict a local map using current sensor observations, e.g. from lidar and camera, without relying on a pre-built map. State-of-the-art methods are based on supervised learning and are trained predominantly using two datasets: nuScenes and Argoverse 2. However, these datasets revisit the same geographic locations across training, validation, and test sets. Specifically, over $80$% of nuScenes and $40$% of Argoverse 2 validation and test samples are less than $5$ m from a training sample. At test time, the methods are thus evaluated more on how well they localize within a memorized implicit map built from the training data than on extrapolating to unseen locations. Naturally, this data leakage causes inflated performance numbers and we propose geographically disjoint data splits to reveal the true performance in unseen environments. Experimental results show that methods perform considerably worse, some dropping more than $45$ mAP, when trained and evaluated on proper data splits. Additionally, a reassessment of prior design choices reveals diverging conclusions from those based on the original split. Notably, the impact of lifting methods and the support from auxiliary tasks (e.g., depth supervision) on performance appears less substantial or follows a different trajectory than previously perceived. Splits can be found at https://github.com/LiljaAdam/geographical-splits
4/8/2024
↗️
Optimal design of experiments in the context of machine-learning inter-atomic potentials: improving the efficiency and transferability of kernel based methods
Bartosz Barzdajn, Christopher P. Race
0
0
Data-driven, machine learning (ML) models of atomistic interactions are often based on flexible and non-physical functions that can relate nuanced aspects of atomic arrangements into predictions of energies and forces. As a result, these potentials are as good as the training data (usually results of so-called ab initio simulations) and we need to make sure that we have enough information for a model to become sufficiently accurate, reliable and transferable. The main challenge stems from the fact that descriptors of chemical environments are often sparse high-dimensional objects without a well-defined continuous metric. Therefore, it is rather unlikely that any ad hoc method of choosing training examples will be indiscriminate, and it will be easy to fall into the trap of confirmation bias, where the same narrow and biased sampling is used to generate train- and test- sets. We will demonstrate that classical concepts of statistical planning of experiments and optimal design can help to mitigate such problems at a relatively low computational cost. The key feature of the method we will investigate is that they allow us to assess the informativeness of data (how much we can improve the model by adding/swapping a training example) and verify if the training is feasible with the current set before obtaining any reference energies and forces -- a so-called off-line approach. In other words, we are focusing on an approach that is easy to implement and doesn't require sophisticated frameworks that involve automated access to high-performance computational (HPC).
5/15/2024
🤿
ContactNet: Geometric-Based Deep Learning Model for Predicting Protein-Protein Interactions
Matan Halfon, Tomer Cohen, Raanan Fattal, Dina Schneidman-Duhovny
0
0
Deep learning approaches achieved significant progress in predicting protein structures. These methods are often applied to protein-protein interactions (PPIs) yet require Multiple Sequence Alignment (MSA) which is unavailable for various interactions, such as antibody-antigen. Computational docking methods are capable of sampling accurate complex models, but also produce thousands of invalid configurations. The design of scoring functions for identifying accurate models is a long-standing challenge. We develop a novel attention-based Graph Neural Network (GNN), ContactNet, for classifying PPI models obtained from docking algorithms into accurate and incorrect ones. When trained on docked antigen and modeled antibody structures, ContactNet doubles the accuracy of current state-of-the-art scoring functions, achieving accurate models among its Top-10 at 43% of the test cases. When applied to unbound antibodies, its Top-10 accuracy increases to 65%. This performance is achieved without MSA and the approach is applicable to other types of interactions, such as host-pathogens or general PPIs.
6/27/2024