LoFiT: Localized Fine-tuning on LLM Representations

0
🛠️
Sign in to get full access
Overview
- The paper explores a new technique called Localized Fine-Tuning on LLM Representations (LoFiT) to adapt large language models (LLMs) for new tasks.
- LoFiT identifies a subset of attention heads that are most important for a specific task, then trains offset vectors to add to the model's hidden representations at those selected heads.
- The paper compares LoFiT's performance to representation intervention methods like Inference-time Intervention and other parameter-efficient fine-tuning methods like LoRA.
Plain English Explanation
Large language models (LLMs) like GPT-3 are powerful AI systems trained on massive amounts of text data. These models can be adapted to perform new tasks, but it's often challenging to do so efficiently. The paper introduces a new technique called Localized Fine-Tuning on LLM Representations (LoFiT) that offers a more effective way to adapt LLMs for new tasks.
The key idea behind LoFiT is to identify a small subset of the model's attention heads (around 3%) that are most important for a specific task, and then train offset vectors to add to the model's hidden representations at those selected heads. This allows the model to be adapted for the new task without having to retrain the entire model from scratch.
The paper shows that LoFiT's intervention vectors are more effective for LLM adaptation than vectors from other representation intervention methods, like Inference-time Intervention. LoFiT also achieves comparable performance to other parameter-efficient fine-tuning methods, such as LoRA, while modifying 20x-200x fewer parameters.
The key benefit of LoFiT is that it allows LLMs to be adapted for new tasks in a more efficient and targeted way, without the need for extensive retraining of the entire model. This could be particularly useful in scenarios where computational resources are limited or where fast adaptation to new tasks is required.
Technical Explanation
The paper introduces a new technique called Localized Fine-Tuning on LLM Representations (LoFiT) for adapting large language models (LLMs) to new tasks. The core idea behind LoFiT is to identify a subset of the model's attention heads that are most important for a specific task, and then train offset vectors to add to the model's hidden representations at those selected heads.
The authors compare LoFiT's performance to other representation intervention methods, such as Inference-time Intervention, and other parameter-efficient fine-tuning methods, like LoRA and Half Fine-Tuning.
The experiments show that LoFiT's intervention vectors are more effective for LLM adaptation than vectors from representation intervention methods, and that the localization step is important - selecting a task-specific set of attention heads can lead to higher performance than intervening on heads selected for a different task.
For the tasks studied, LoFiT achieves comparable performance to other parameter-efficient fine-tuning methods, such as LoRA, despite modifying 20x-200x fewer parameters. This suggests that LoFiT provides a more efficient way to adapt LLMs for new tasks, which could be particularly useful in scenarios where computational resources are limited or where fast adaptation to new tasks is required.
Critical Analysis
The paper presents a novel and promising approach to adapting large language models for new tasks. The key strength of LoFiT is its ability to achieve strong performance while modifying a much smaller number of parameters compared to other fine-tuning methods.
One potential limitation of the research is that it has only been evaluated on a limited set of tasks, such as truthfulness and reasoning. It would be valuable to see how LoFiT performs on a broader range of tasks, including more open-ended and creative tasks, to better understand its generalizability.
Additionally, the paper does not provide much insight into the mechanisms by which LoFiT achieves its performance gains. Further analysis of the learned offset vectors and their interaction with the model's attention heads could help shed light on the underlying reasons for LoFiT's effectiveness.
Balancing Speciality and Versatility: A Coarse-to-Fine Framework for Efficient Adaptation is another related work that explores efficient adaptation of LLMs. Comparing LoFiT's approach to this framework could provide additional insights and opportunities for further development.
Overall, the paper presents a compelling and practical approach to LLM adaptation that warrants further exploration and research. Continued advancements in this area could lead to more efficient and effective ways of leveraging large language models for a wide range of applications.
Conclusion
The paper introduces a new technique called Localized Fine-Tuning on LLM Representations (LoFiT) that provides an effective way to adapt large language models (LLMs) for new tasks. LoFiT identifies a sparse subset of attention heads that are most important for a specific task and trains offset vectors to add to the model's hidden representations at those selected heads.
The key benefits of LoFiT are its strong performance, which is comparable to other parameter-efficient fine-tuning methods, and its ability to achieve these results while modifying 20x-200x fewer parameters. This makes LoFiT a promising approach for adapting LLMs in scenarios where computational resources are limited or where fast adaptation to new tasks is required.
Further research is needed to explore LoFiT's generalizability to a broader range of tasks and to better understand the underlying mechanisms behind its effectiveness. Nonetheless, the paper presents a significant contribution to the field of efficient LLM adaptation, with the potential to enable more widespread and practical applications of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
0
LoFiT: Localized Fine-tuning on LLM Representations
Fangcong Yin, Xi Ye, Greg Durrett
Recent work in interpretability shows that large language models (LLMs) can be adapted for new tasks in a learning-free way: it is possible to intervene on LLM representations to elicit desired behaviors for alignment. For instance, adding certain bias vectors to the outputs of certain attention heads is reported to boost the truthfulness of models. In this work, we show that localized fine-tuning serves as an effective alternative to such representation intervention methods. We introduce a framework called Localized Fine-Tuning on LLM Representations (LoFiT), which identifies a subset of attention heads that are most important for learning a specific task, then trains offset vectors to add to the model's hidden representations at those selected heads. LoFiT localizes to a sparse set of heads (3%) and learns the offset vectors from limited training data, comparable to the settings used for representation intervention. For truthfulness and reasoning tasks, we find that LoFiT's intervention vectors are more effective for LLM adaptation than vectors from representation intervention methods such as Inference-time Intervention. We also find that the localization step is important: selecting a task-specific set of attention heads can lead to higher performance than intervening on heads selected for a different task. Finally, for the tasks we study, LoFiT achieves comparable performance to other parameter-efficient fine-tuning methods such as LoRA, despite modifying 20x-200x fewer parameters than these methods.
Read more6/4/2024
0
Low-rank finetuning for LLMs: A fairness perspective
Saswat Das, Marco Romanelli, Cuong Tran, Zarreen Reza, Bhavya Kailkhura, Ferdinando Fioretto
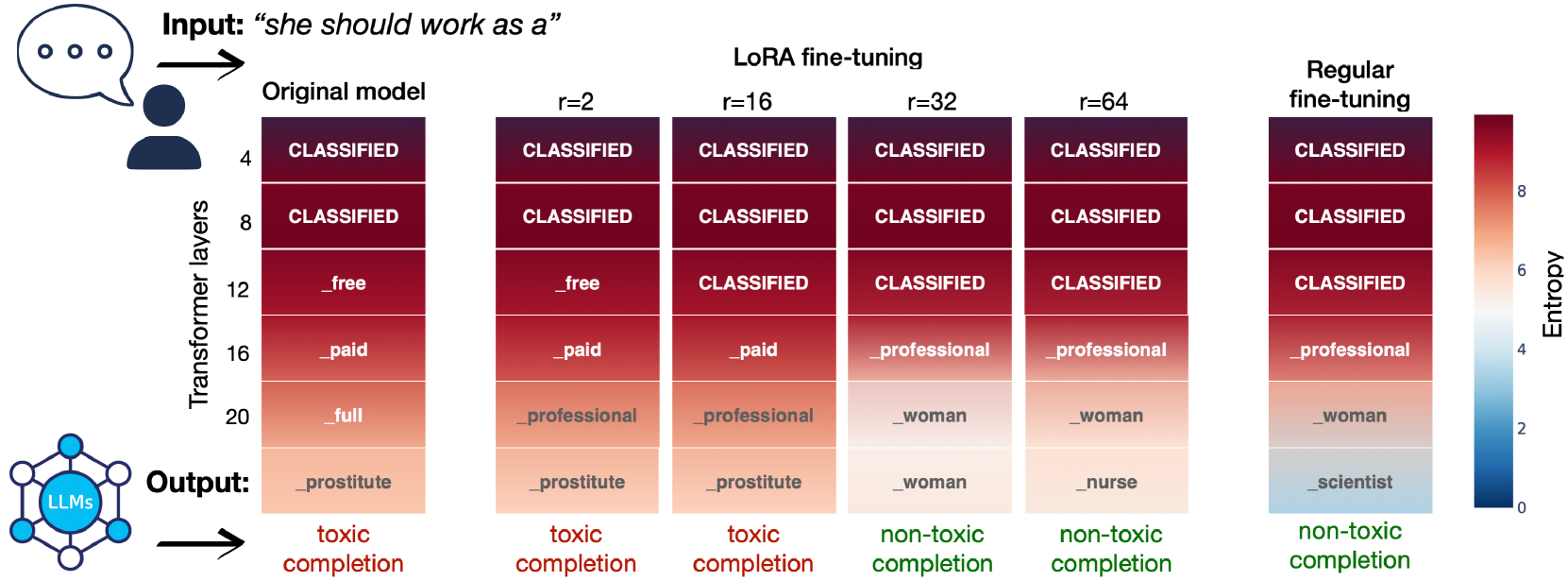
Low-rank approximation techniques have become the de facto standard for fine-tuning Large Language Models (LLMs) due to their reduced computational and memory requirements. This paper investigates the effectiveness of these methods in capturing the shift of fine-tuning datasets from the initial pre-trained data distribution. Our findings reveal that there are cases in which low-rank fine-tuning falls short in learning such shifts. This, in turn, produces non-negligible side effects, especially when fine-tuning is adopted for toxicity mitigation in pre-trained models, or in scenarios where it is important to provide fair models. Through comprehensive empirical evidence on several models, datasets, and tasks, we show that low-rank fine-tuning inadvertently preserves undesirable biases and toxic behaviors. We also show that this extends to sequential decision-making tasks, emphasizing the need for careful evaluation to promote responsible LLMs development.
Read more5/30/2024
💬
2
ReFT: Representation Finetuning for Language Models
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, Christopher Potts
Parameter-efficient finetuning (PEFT) methods seek to adapt large neural models via updates to a small number of weights. However, much prior interpretability work has shown that representations encode rich semantic information, suggesting that editing representations might be a more powerful alternative. We pursue this hypothesis by developing a family of Representation Finetuning (ReFT) methods. ReFT methods operate on a frozen base model and learn task-specific interventions on hidden representations. We define a strong instance of the ReFT family, Low-rank Linear Subspace ReFT (LoReFT), and we identify an ablation of this method that trades some performance for increased efficiency. Both are drop-in replacements for existing PEFTs and learn interventions that are 15x--65x more parameter-efficient than LoRA. We showcase LoReFT on eight commonsense reasoning tasks, four arithmetic reasoning tasks, instruction-tuning, and GLUE. In all these evaluations, our ReFTs deliver the best balance of efficiency and performance, and almost always outperform state-of-the-art PEFTs. We release a generic ReFT training library publicly at https://github.com/stanfordnlp/pyreft.
Read more5/24/2024

0
Balancing Speciality and Versatility: a Coarse to Fine Framework for Supervised Fine-tuning Large Language Model
Hengyuan Zhang, Yanru Wu, Dawei Li, Sak Yang, Rui Zhao, Yong Jiang, Fei Tan
Aligned Large Language Models (LLMs) showcase remarkable versatility, capable of handling diverse real-world tasks. Meanwhile, aligned LLMs are also expected to exhibit speciality, excelling in specific applications. However, fine-tuning with extra data, a common practice to gain speciality, often leads to catastrophic forgetting (CF) of previously acquired versatility, hindering the model's performance across diverse tasks. In response to this challenge, we propose CoFiTune, a coarse to fine framework in an attempt to strike the balance between speciality and versatility. At the coarse-grained level, an empirical tree-search algorithm is utilized to pinpoint and update specific modules that are crucial for speciality, while keeping other parameters frozen; at the fine-grained level, a soft-masking mechanism regulates the update to the LLMs, mitigating the CF issue without harming speciality. In an overall evaluation of both speciality and versatility, CoFiTune consistently outperforms baseline methods across diverse tasks and model scales. Compared to the full-parameter SFT, CoFiTune leads to about 14% versatility improvement and marginal speciality loss on a 13B model. Lastly, based on further analysis, we provide a speculative insight into the information forwarding process in LLMs, which helps explain the effectiveness of the proposed method. The code is available at https://github.com/rattlesnakey/CoFiTune.
Read more8/14/2024