Long-CLIP: Unlocking the Long-Text Capability of CLIP
2403.15378
0
0

Abstract
Contrastive Language-Image Pre-training (CLIP) has been the cornerstone for zero-shot classification, text-image retrieval, and text-image generation by aligning image and text modalities. Despite its widespread adoption, a significant limitation of CLIP lies in the inadequate length of text input. The length of the text token is restricted to 77, and an empirical study shows the actual effective length is even less than 20. This prevents CLIP from handling detailed descriptions, limiting its applications for image retrieval and text-to-image generation with extensive prerequisites. To this end, we propose Long-CLIP as a plug-and-play alternative to CLIP that supports long-text input, retains or even surpasses its zero-shot generalizability, and aligns the CLIP latent space, making it readily replace CLIP without any further adaptation in downstream frameworks. Nevertheless, achieving this goal is far from straightforward, as simplistic fine-tuning can result in a significant degradation of CLIP's performance. Moreover, substituting the text encoder with a language model supporting longer contexts necessitates pretraining with vast amounts of data, incurring significant expenses. Accordingly, Long-CLIP introduces an efficient fine-tuning solution on CLIP with two novel strategies designed to maintain the original capabilities, including (1) a knowledge-preserved stretching of positional embedding and (2) a primary component matching of CLIP features. With leveraging just one million extra long text-image pairs, Long-CLIP has shown the superiority to CLIP for about 20% in long caption text-image retrieval and 6% in traditional text-image retrieval tasks, e.g., COCO and Flickr30k. Furthermore, Long-CLIP offers enhanced capabilities for generating images from detailed text descriptions by replacing CLIP in a plug-and-play manner.
Create account to get full access
Overview
- This paper presents "Long-CLIP", a method for unlocking the long-text capability of the CLIP model, a popular multimodal neural network that can perform tasks like zero-shot image classification and text-to-image retrieval.
- CLIP was originally trained on image-text pairs with relatively short text captions, limiting its ability to handle longer text inputs. Long-CLIP addresses this by introducing novel architectural and training techniques to enable CLIP to effectively process longer text sequences.
- The authors demonstrate that Long-CLIP outperforms CLIP on a range of long-text tasks, including long-form question answering, long-form summarization, and long-form code generation, while maintaining strong performance on the original CLIP tasks.
Plain English Explanation
The CLIP model is a powerful AI system that can do impressive things like recognize objects in images and find relevant images based on text descriptions. However, CLIP was trained on image-text pairs with relatively short text captions, so it struggles with longer text inputs.
The researchers behind Long-CLIP set out to fix this. They developed new architectural and training techniques to allow CLIP to effectively process longer text sequences, unlocking its potential for tasks that require understanding longer passages of text. For example, Long-CLIP can now do a better job at answering long questions, summarizing long documents, and generating code from lengthy prompts.
By expanding CLIP's capabilities in this way, the Long-CLIP method makes the model more versatile and useful across a wider range of applications. It's an important step forward in advancing the state-of-the-art in multimodal AI systems that can work with both images and text.
Technical Explanation
The key innovations in the Long-CLIP method are:
-
Hierarchical Text Encoder: Instead of CLIP's original linear text encoder, Long-CLIP uses a hierarchical transformer-based encoder that can better capture the structure and semantics of long text sequences.
-
Masked Language Modeling: During pre-training, Long-CLIP introduces a masked language modeling objective to improve the text encoder's ability to understand and generate longer text.
-
Contrastive Fine-tuning: After pre-training, Long-CLIP fine-tunes the model using a contrastive loss function that encourages the text and image encoders to learn aligned representations for long text-image pairs.
Through these architectural and training advances, Long-CLIP is able to outperform the original CLIP model on a variety of long-text tasks, such as long-form question answering, long-form summarization, and long-form code generation, while still maintaining strong performance on the original CLIP tasks like zero-shot image classification and text-to-image retrieval.
Critical Analysis
The authors acknowledge that Long-CLIP is still limited in its ability to handle extremely long text inputs, as might be encountered in real-world applications like legal contracts or research papers. They suggest that further architectural innovations and more efficient training techniques may be needed to truly "demystify" the handling of such long text.
Additionally, while Long-CLIP demonstrates strong performance on a variety of benchmarks, the authors do not provide a deep analysis of the model's failure modes or biases. It would be valuable for future work to more thoroughly investigate the limitations and potential pitfalls of this approach, especially as it is applied to high-stakes applications.
Overall, the Long-CLIP method represents an important advance in multimodal AI, but there is still significant room for improvement in developing models that can robustly and reliably process long text inputs in conjunction with visual information.
Conclusion
The Long-CLIP model addresses a key limitation of the original CLIP system by introducing novel architectural and training techniques that enable the model to effectively process and understand longer text sequences. This unlocks CLIP's potential for a wider range of applications that require reasoning over longer passages of text, such as question answering, summarization, and code generation.
While Long-CLIP demonstrates promising results, the authors acknowledge that there is still room for improvement in handling extremely long text inputs. Continued research in this area has the potential to further advance the state-of-the-art in multimodal AI, leading to systems that can seamlessly integrate and reason over both visual and textual information at scale.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024

CLIP model is an Efficient Online Lifelong Learner
Leyuan Wang, Liuyu Xiang, Yujie Wei, Yunlong Wang, Zhaofeng He
0
0
Online Lifelong Learning (OLL) addresses the challenge of learning from continuous and non-stationary data streams. Existing online lifelong learning methods based on image classification models often require preset conditions such as the total number of classes or maximum memory capacity, which hinders the realization of real never-ending learning and renders them impractical for real-world scenarios. In this work, we propose that vision-language models, such as Contrastive Language-Image Pretraining (CLIP), are more suitable candidates for online lifelong learning. We discover that maintaining symmetry between image and text is crucial during Parameter-Efficient Tuning (PET) for CLIP model in online lifelong learning. To this end, we introduce the Symmetric Image-Text (SIT) tuning strategy. We conduct extensive experiments on multiple lifelong learning benchmark datasets and elucidate the effectiveness of SIT through gradient analysis. Additionally, we assess the impact of lifelong learning on generalizability of CLIP and found that tuning the image encoder is beneficial for lifelong learning, while tuning the text encoder aids in zero-shot learning.
5/27/2024

Jina CLIP: Your CLIP Model Is Also Your Text Retriever
Andreas Koukounas, Georgios Mastrapas, Michael Gunther, Bo Wang, Scott Martens, Isabelle Mohr, Saba Sturua, Mohammad Kalim Akram, Joan Fontanals Mart'inez, Saahil Ognawala, Susana Guzman, Maximilian Werk, Nan Wang, Han Xiao
0
0
Contrastive Language-Image Pretraining (CLIP) is widely used to train models to align images and texts in a common embedding space by mapping them to fixed-sized vectors. These models are key to multimodal information retrieval and related tasks. However, CLIP models generally underperform in text-only tasks compared to specialized text models. This creates inefficiencies for information retrieval systems that keep separate embeddings and models for text-only and multimodal tasks. We propose a novel, multi-task contrastive training method to address this issue, which we use to train the jina-clip-v1 model to achieve the state-of-the-art performance on both text-image and text-text retrieval tasks.
6/27/2024
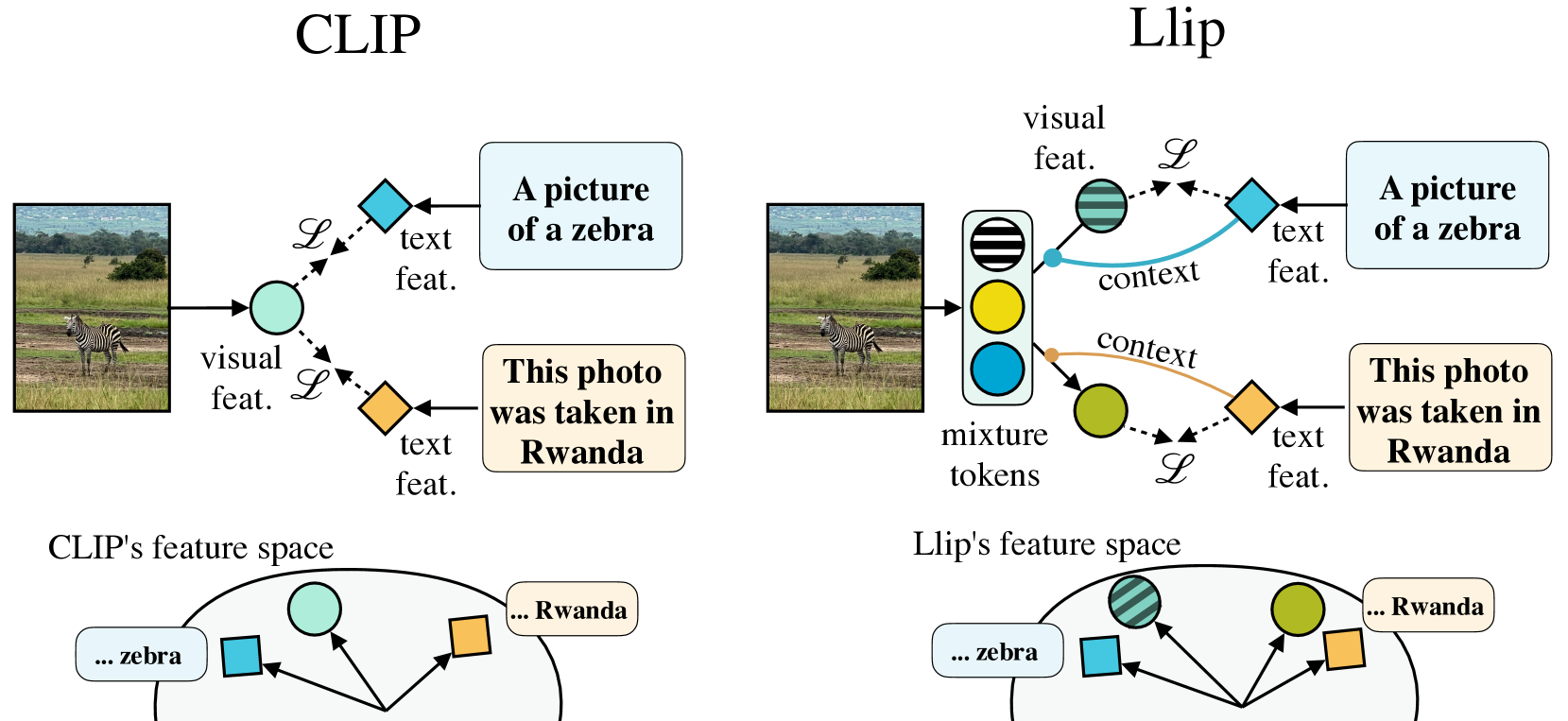
Modeling Caption Diversity in Contrastive Vision-Language Pretraining
Samuel Lavoie, Polina Kirichenko, Mark Ibrahim, Mahmoud Assran, Andrew Gordon Wilson, Aaron Courville, Nicolas Ballas
0
0
There are a thousand ways to caption an image. Contrastive Language Pretraining (CLIP) on the other hand, works by mapping an image and its caption to a single vector -- limiting how well CLIP-like models can represent the diverse ways to describe an image. In this work, we introduce Llip, Latent Language Image Pretraining, which models the diversity of captions that could match an image. Llip's vision encoder outputs a set of visual features that are mixed into a final representation by conditioning on information derived from the text. We show that Llip outperforms non-contextualized baselines like CLIP and SigLIP on a variety of tasks even with large-scale encoders. Llip improves zero-shot classification by an average of 2.9% zero-shot classification benchmarks with a ViT-G/14 encoder. Specifically, Llip attains a zero-shot top-1 accuracy of 83.5% on ImageNet outperforming a similarly sized CLIP by 1.4%. We also demonstrate improvement on zero-shot retrieval on MS-COCO by 6.0%. We provide a comprehensive analysis of the components introduced by the method and demonstrate that Llip leads to richer visual representations.
5/15/2024