Low-light Object Detection

0
🔎
Sign in to get full access
Overview
- The researchers used a model fusion approach to achieve object detection results close to those of real images.
- Their method is based on the CO-DETR model, which was trained on two sets of data: one containing images under dark conditions and another containing images enhanced with low-light conditions.
- They used various enhancement techniques on the test data to generate multiple sets of prediction results.
- Finally, they applied a clustering aggregation method guided by IoU thresholds to select the optimal results.
Plain English Explanation
The researchers wanted to improve object detection in low-light conditions, so they combined multiple machine learning models to get better results than any single model could achieve on its own. They started with a model called CO-DETR, which had been trained on two different datasets: one with images taken in the dark, and another with images that had been artificially brightened.
To get the best possible results on the test images, the researchers tried out different techniques to enhance the brightness and contrast of the images. They then ran the enhanced images through the CO-DETR model and combined the prediction results in a smart way, using a clustering algorithm to select the most reliable detections.
The key idea is that by leveraging multiple models and image enhancement methods, the researchers were able to achieve object detection performance that was very close to what you'd see on high-quality images taken in good lighting conditions. This could be really useful for applications like self-driving cars or security cameras that need to work well even when lighting is poor.
Technical Explanation
The researchers employed a model fusion approach to achieve object detection results close to those of real images. Their method is based on the CO-DETR model, which was trained on two sets of data: one containing images under dark conditions and another containing images enhanced with low-light conditions.
To generate multiple sets of prediction results, the researchers used various enhancement techniques on the test data. Finally, they applied a clustering aggregation method guided by IoU thresholds to select the optimal results.
Critical Analysis
The paper does not provide much detail on the specific image enhancement techniques used, nor does it evaluate the performance of those techniques in isolation. It would be helpful to know more about the tradeoffs and limitations of the different enhancement methods.
Additionally, the paper does not address the computational complexity or inference time of the overall model fusion approach. In real-world applications, these factors could be important considerations.
While the results demonstrate improved object detection performance compared to individual models, the researchers could have strengthened their analysis by comparing against a wider range of baseline methods, including recent advances in low-light vision and domain adaptation.
Conclusion
Overall, this research presents a promising approach for improving object detection in low-light conditions by combining multiple machine learning models and image enhancement techniques. The model fusion strategy could be applicable to a variety of computer vision tasks beyond just object detection, with potential benefits for applications like autonomous navigation, surveillance, and text recognition in dark environments. However, further research is needed to fully understand the strengths, weaknesses, and practical implications of this method.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
Low-light Object Detection
Pengpeng Li, Haowei Gu, Yang Yang
In this competition we employed a model fusion approach to achieve object detection results close to those of real images. Our method is based on the CO-DETR model, which was trained on two sets of data: one containing images under dark conditions and another containing images enhanced with low-light conditions. We used various enhancement techniques on the test data to generate multiple sets of prediction results. Finally, we applied a clustering aggregation method guided by IoU thresholds to select the optimal results.
Read more5/7/2024
🔍
0
Multi-Object Tracking in the Dark
Xinzhe Wang, Kang Ma, Qiankun Liu, Yunhao Zou, Ying Fu
Low-light scenes are prevalent in real-world applications (e.g. autonomous driving and surveillance at night). Recently, multi-object tracking in various practical use cases have received much attention, but multi-object tracking in dark scenes is rarely considered. In this paper, we focus on multi-object tracking in dark scenes. To address the lack of datasets, we first build a Low-light Multi-Object Tracking (LMOT) dataset. LMOT provides well-aligned low-light video pairs captured by our dual-camera system, and high-quality multi-object tracking annotations for all videos. Then, we propose a low-light multi-object tracking method, termed as LTrack. We introduce the adaptive low-pass downsample module to enhance low-frequency components of images outside the sensor noises. The degradation suppression learning strategy enables the model to learn invariant information under noise disturbance and image quality degradation. These components improve the robustness of multi-object tracking in dark scenes. We conducted a comprehensive analysis of our LMOT dataset and proposed LTrack. Experimental results demonstrate the superiority of the proposed method and its competitiveness in real night low-light scenes. Dataset and Code: https: //github.com/ying-fu/LMOT
Read more5/13/2024

0
Low-Light Object Tracking: A Benchmark
Pengzhi Zhong, Xiaoyu Guo, Defeng Huang, Xiaojun Peng, Yian Li, Qijun Zhao, Shuiwang Li
In recent years, the field of visual tracking has made significant progress with the application of large-scale training datasets. These datasets have supported the development of sophisticated algorithms, enhancing the accuracy and stability of visual object tracking. However, most research has primarily focused on favorable illumination circumstances, neglecting the challenges of tracking in low-ligh environments. In low-light scenes, lighting may change dramatically, targets may lack distinct texture features, and in some scenarios, targets may not be directly observable. These factors can lead to a severe decline in tracking performance. To address this issue, we introduce LLOT, a benchmark specifically designed for Low-Light Object Tracking. LLOT comprises 269 challenging sequences with a total of over 132K frames, each carefully annotated with bounding boxes. This specially designed dataset aims to promote innovation and advancement in object tracking techniques for low-light conditions, addressing challenges not adequately covered by existing benchmarks. To assess the performance of existing methods on LLOT, we conducted extensive tests on 39 state-of-the-art tracking algorithms. The results highlight a considerable gap in low-light tracking performance. In response, we propose H-DCPT, a novel tracker that incorporates historical and darkness clue prompts to set a stronger baseline. H-DCPT outperformed all 39 evaluated methods in our experiments, demonstrating significant improvements. We hope that our benchmark and H-DCPT will stimulate the development of novel and accurate methods for tracking objects in low-light conditions. The LLOT and code are available at https://github.com/OpenCodeGithub/H-DCPT.
Read more8/22/2024
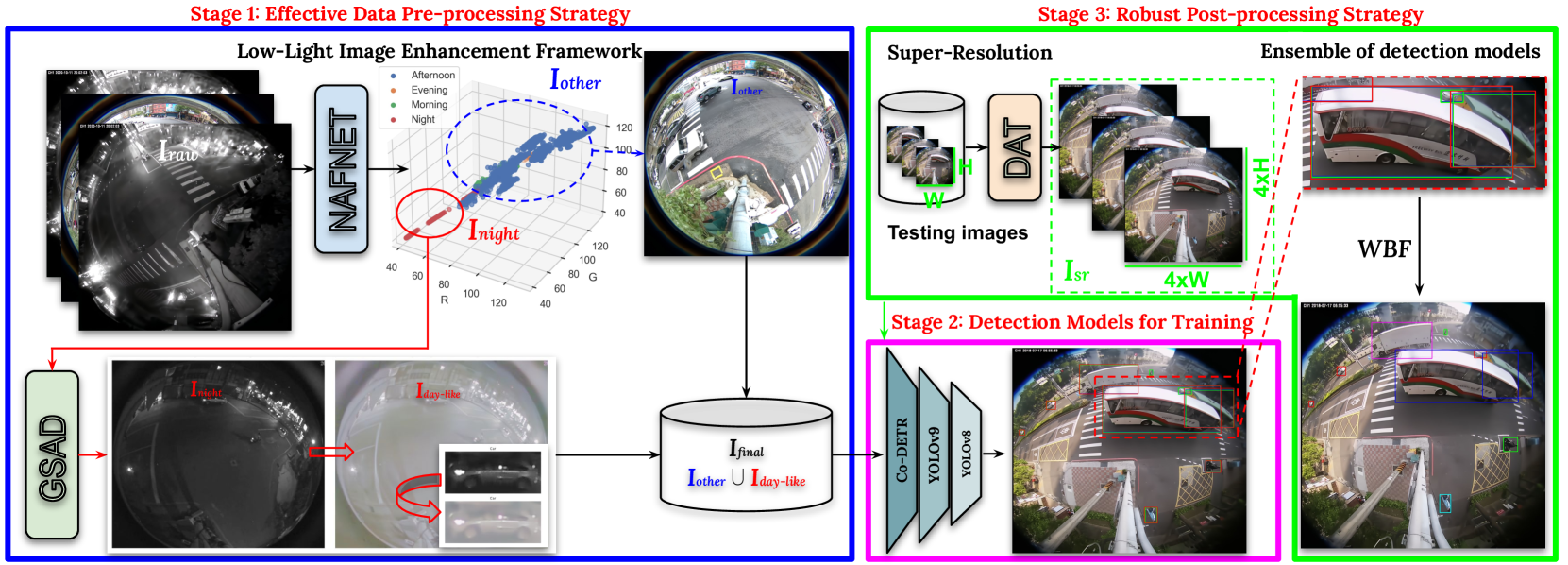
0
Low-Light Image Enhancement Framework for Improved Object Detection in Fisheye Lens Datasets
Dai Quoc Tran, Armstrong Aboah, Yuntae Jeon, Maged Shoman, Minsoo Park, Seunghee Park
This study addresses the evolving challenges in urban traffic monitoring detection systems based on fisheye lens cameras by proposing a framework that improves the efficacy and accuracy of these systems. In the context of urban infrastructure and transportation management, advanced traffic monitoring systems have become critical for managing the complexities of urbanization and increasing vehicle density. Traditional monitoring methods, which rely on static cameras with narrow fields of view, are ineffective in dynamic urban environments, necessitating the installation of multiple cameras, which raises costs. Fisheye lenses, which were recently introduced, provide wide and omnidirectional coverage in a single frame, making them a transformative solution. However, issues such as distorted views and blurriness arise, preventing accurate object detection on these images. Motivated by these challenges, this study proposes a novel approach that combines a ransformer-based image enhancement framework and ensemble learning technique to address these challenges and improve traffic monitoring accuracy, making significant contributions to the future of intelligent traffic management systems. Our proposed methodological framework won 5th place in the 2024 AI City Challenge, Track 4, with an F1 score of 0.5965 on experimental validation data. The experimental results demonstrate the effectiveness, efficiency, and robustness of the proposed system. Our code is publicly available at https://github.com/daitranskku/AIC2024-TRACK4-TEAM15.
Read more4/17/2024