Lyapunov Neural ODE Feedback Control Policies

0

Sign in to get full access
Overview
- The paper proposes a method for designing Lyapunov-stable neural ordinary differential equation (ODE) feedback control policies for nonlinear dynamical systems.
- The approach leverages neural networks to learn the control policy and Lyapunov function, ensuring the closed-loop system stability.
- Experiments demonstrate the effectiveness of the proposed method on various benchmark control tasks.
Plain English Explanation
The paper presents a new way to control complex, nonlinear systems using neural networks. The key idea is to design the control policy and a special function, called the Lyapunov function, that guarantees the system will remain stable over time.
Traditionally, designing stable controllers for nonlinear systems is very challenging. The researchers show how neural networks can be used to learn both the control policy and the Lyapunov function, making the process much more automated and data-driven.
The key advantage is that the resulting control policy is guaranteed to keep the system stable, even as it navigates complex dynamics. This is important for safety-critical applications like robotics or aerospace where system stability is crucial.
Technical Explanation
The paper formulates the problem of designing a feedback control policy for a nonlinear dynamical system, where the goal is to find a control law that stabilizes the system around a desired equilibrium point.
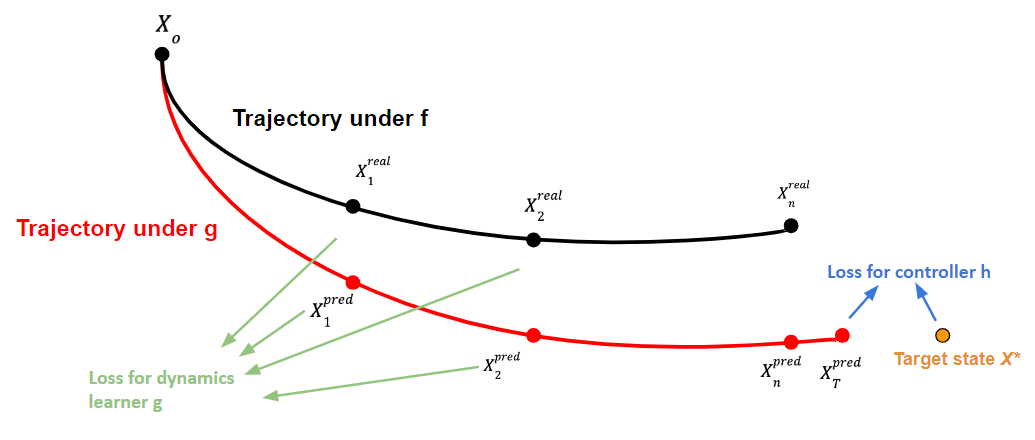
The authors propose a neural ODE-based approach, where the control policy and a Lyapunov function are represented using neural networks. The Lyapunov function serves as a Lyapunov stability certificate, ensuring the closed-loop system is asymptotically stable.
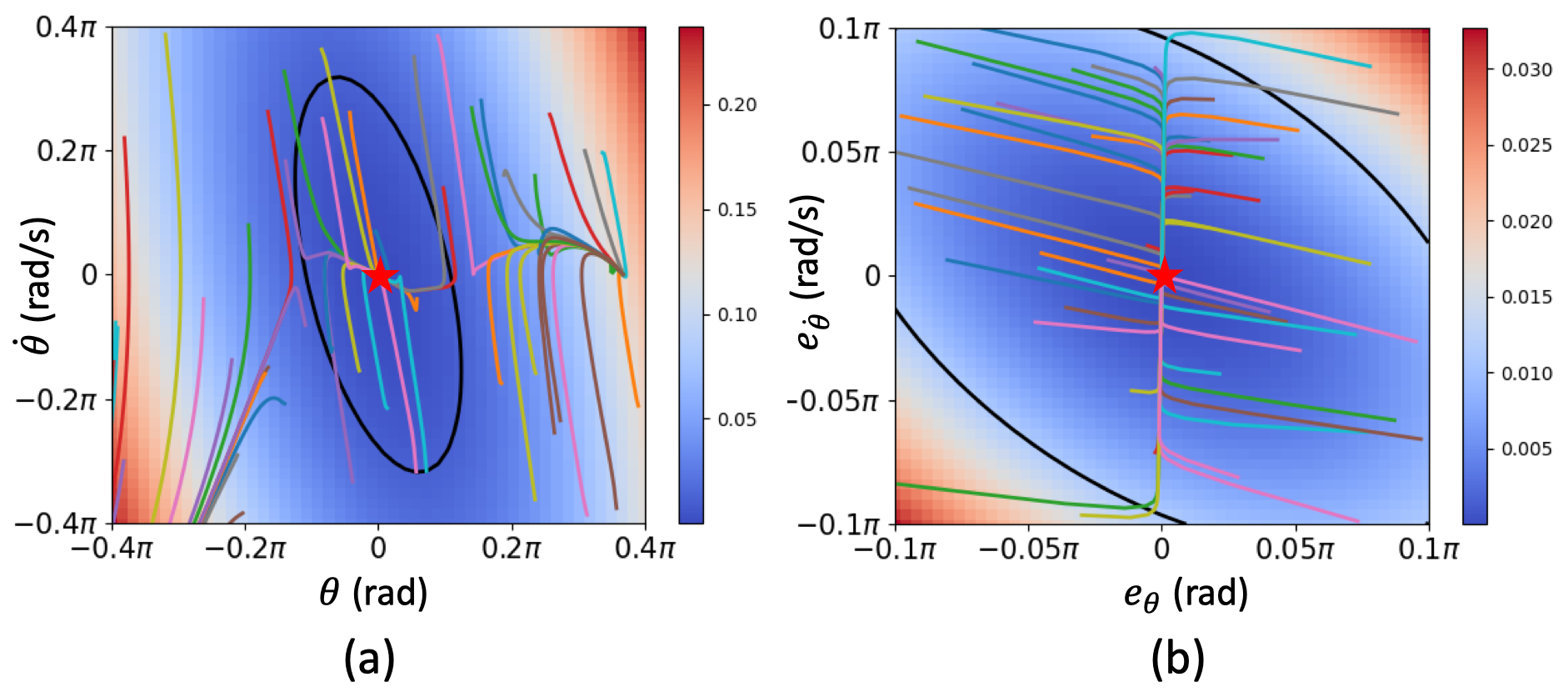
The neural networks are trained jointly to minimize the control effort while preserving Lyapunov stability. Experiments on various benchmark control tasks, including inverted pendulum and quadrotor control, demonstrate the effectiveness of the proposed method in learning stable and high-performance feedback control policies.
Critical Analysis
The paper provides a promising approach for designing Lyapunov-stable neural feedback control policies. The key strength is the ability to jointly learn the control policy and Lyapunov function, ensuring closed-loop stability while leveraging the flexibility of neural networks.
However, the paper does not address the challenge of obtaining a suitable Lyapunov function, which is crucial for establishing stability. The authors rely on a neural network to learn the Lyapunov function, but the convergence and optimality of this approach are not thoroughly analyzed.
Additionally, the experimental evaluation is limited to relatively simple benchmark control problems. More complex, high-dimensional systems with uncertain dynamics would further test the scalability and robustness of the proposed method.
Conclusion
This paper presents a novel approach for designing Lyapunov-stable neural feedback control policies for nonlinear dynamical systems. By jointly learning the control policy and Lyapunov function using neural networks, the method aims to combine the flexibility of neural networks with the formal stability guarantees provided by Lyapunov theory.
The experimental results demonstrate the effectiveness of the proposed method on various benchmark control tasks. However, further research is needed to address the challenges of obtaining suitable Lyapunov functions and scaling the approach to more complex, high-dimensional systems with uncertain dynamics.
Overall, this work represents a promising step towards the development of automated and data-driven methods for designing stable and high-performance control policies for nonlinear systems, with potential applications in robotics, aerospace, and other safety-critical domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Lyapunov Neural ODE Feedback Control Policies
Joshua Hang Sai Ip, Georgios Makrygiorgos, Ali Mesbah
Deep neural networks are increasingly used as an effective way to represent control policies in a wide-range of learning-based control methods. For continuous-time optimal control problems (OCPs), which are central to many decision-making tasks, control policy learning can be cast as a neural ordinary differential equation (NODE) problem wherein state and control constraints are naturally accommodated. This paper presents a Lyapunov-NODE control (L-NODEC) approach to solving continuous-time OCPs for the case of stabilizing a known constrained nonlinear system around a terminal equilibrium point. We propose a Lyapunov loss formulation that incorporates a control-theoretic Lyapunov condition into the problem of learning a state-feedback neural control policy. We establish that L-NODEC ensures exponential stability of the controlled system, as well as its adversarial robustness to uncertain initial conditions. The performance of L-NODEC is illustrated on a benchmark double integrator problem and for optimal control of thermal dose delivery using a cold atmospheric plasma biomedical system. L-NODEC can substantially reduce the inference time necessary to reach the equilibrium state.
Read more9/4/2024
0
Lyapunov-stable Neural Control for State and Output Feedback: A Novel Formulation for Efficient Synthesis and Verification
Lujie Yang, Hongkai Dai, Zhouxing Shi, Cho-Jui Hsieh, Russ Tedrake, Huan Zhang
Learning-based neural network (NN) control policies have shown impressive empirical performance in a wide range of tasks in robotics and control. However, formal (Lyapunov) stability guarantees over the region-of-attraction (ROA) for NN controllers with nonlinear dynamical systems are challenging to obtain, and most existing approaches rely on expensive solvers such as sums-of-squares (SOS), mixed-integer programming (MIP), or satisfiability modulo theories (SMT). In this paper, we demonstrate a new framework for learning NN controllers together with Lyapunov certificates using fast empirical falsification and strategic regularizations. We propose a novel formulation that defines a larger verifiable region-of-attraction (ROA) than shown in the literature, and refines the conventional restrictive constraints on Lyapunov derivatives to focus only on certifiable ROAs. The Lyapunov condition is rigorously verified post-hoc using branch-and-bound with scalable linear bound propagation-based NN verification techniques. The approach is efficient and flexible, and the full training and verification procedure is accelerated on GPUs without relying on expensive solvers for SOS, MIP, nor SMT. The flexibility and efficiency of our framework allow us to demonstrate Lyapunov-stable output feedback control with synthesized NN-based controllers and NN-based observers with formal stability guarantees, for the first time in literature. Source code at https://github.com/Verified-Intelligence/Lyapunov_Stable_NN_Controllers
Read more6/6/2024
0
Neural Control: Concurrent System Identification and Control Learning with Neural ODE
Cheng Chi
Controlling continuous-time dynamical systems is generally a two step process: first, identify or model the system dynamics with differential equations, then, minimize the control objectives to achieve optimal control function and optimal state trajectories. However, any inaccuracy in dynamics modeling will lead to sub-optimality in the resulting control function. To address this, we propose a neural ODE based method for controlling unknown dynamical systems, denoted as Neural Control (NC), which combines dynamics identification and optimal control learning using a coupled neural ODE. Through an intriguing interplay between the two neural networks in coupled neural ODE structure, our model concurrently learns system dynamics as well as optimal controls that guides towards target states. Our experiments demonstrate the effectiveness of our model for learning optimal control of unknown dynamical systems. Codes available at https://github.com/chichengmessi/neural_ode_control/tree/main
Read more4/23/2024
🧠
0
Solving Elliptic Optimal Control Problems via Neural Networks and Optimality System
Yongcheng Dai, Bangti Jin, Ramesh Sau, Zhi Zhou
In this work, we investigate a neural network based solver for optimal control problems (without / with box constraint) for linear and semilinear second-order elliptic problems. It utilizes a coupled system derived from the first-order optimality system of the optimal control problem, and employs deep neural networks to represent the solutions to the reduced system. We present an error analysis of the scheme, and provide $L^2(Omega)$ error bounds on the state, control and adjoint in terms of neural network parameters (e.g., depth, width, and parameter bounds) and the numbers of sampling points. The main tools in the analysis include offset Rademacher complexity and boundedness and Lipschitz continuity of neural network functions. We present several numerical examples to illustrate the method and compare it with two existing ones.
Read more5/9/2024