Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic-aware Visual Objects
2312.05278
0
0

Abstract
Large Vision Language Models (LVLMs) have demonstrated impressive zero-shot capabilities in various vision-language dialogue scenarios. However, the absence of fine-grained visual object detection hinders the model from understanding the details of images, leading to irreparable visual hallucinations and factual errors. In this paper, we propose Lyrics, a novel multi-modal pre-training and instruction fine-tuning paradigm that bootstraps vision-language alignment from fine-grained cross-modal collaboration. Building on the foundation of BLIP-2, Lyrics infuses local visual features extracted from a visual refiner that includes image tagging, object detection and semantic segmentation modules into the Querying Transformer, while on the text side, the language inputs equip the boundary boxes and tags derived from the visual refiner. We further introduce a two-stage training scheme, in which the pre-training stage bridges the modality gap through explicit and comprehensive vision-language alignment targets. During the instruction fine-tuning stage, we introduce semantic-aware visual feature extraction, a crucial method that enables the model to extract informative features from concrete visual objects. Our approach achieves robust performance on 13 datasets across various vision-language tasks, and demonstrates promising multi-modal understanding, perception and conversation capabilities in 11 scenario-based benchmark toolkits.
Create account to get full access
Overview
- This paper introduces a novel approach to improving the alignment between large language models and visual representations, focusing on fine-grained understanding.
- The key idea is to leverage semantic-aware visual objects to better capture the relationships between language and visual content.
- The proposed method outperforms state-of-the-art approaches on a range of language-vision tasks, demonstrating its effectiveness in boosting fine-grained language-vision alignment.
Plain English Explanation
The paper describes a new way to help large language models, such as GPT-3, better understand the connection between words and visual information. Large language models are powerful at processing and generating human-like text, but they can struggle to fully capture the nuanced relationships between language and visual content.
The researchers address this by incorporating "semantic-aware visual objects" into the language-vision alignment process. Essentially, they are using more detailed information about the objects and visual elements in an image, beyond just the objects themselves. This helps the language model better understand the context and meaning behind the visual content, leading to improved performance on tasks that require fine-grained language-vision understanding.
For example, if the language model is asked to describe an image, the additional semantic information about the visual elements can help it generate more accurate and detailed descriptions, rather than just listing the objects it sees. This could be particularly useful for applications like image captioning, visual question answering, and even multimodal machine translation.
The paper demonstrates that this approach outperforms other state-of-the-art methods on a variety of language-vision benchmarks, highlighting the potential of leveraging semantic-aware visual representations to boost the alignment between language and vision.
Technical Explanation
The paper proposes a novel approach to improve the fine-grained alignment between large language models and visual representations, building upon recent advancements in harnessing the power of large vision-language models and semantically-prompted language models for improved visual descriptions.
The key innovation is the use of "semantic-aware visual objects," which capture more detailed information about the visual elements in an image beyond just the object labels. This includes attributes, relationships, and contextual information about the objects, which is then leveraged to improve the alignment between language and vision.
The proposed architecture consists of a language model and a visual encoder that are jointly trained to optimize the alignment between language and these semantic-aware visual representations. This is facilitated by the joint visual-text prompting technique, which allows the model to learn the complex mapping between language and the rich visual semantics.
Extensive experiments on a range of language-vision benchmarks, including fine-grained image-text alignment and visual question answering, demonstrate the effectiveness of the proposed approach in boosting fine-grained language-vision alignment compared to state-of-the-art methods.
Critical Analysis
The paper presents a compelling approach to improving the alignment between language models and visual representations, but it is important to consider some potential caveats and areas for further research.
One limitation is that the reliance on semantic-aware visual objects may introduce additional complexity and computational overhead, which could hinder the scalability and practical deployment of the proposed method. Further research is needed to understand the trade-offs between the performance gains and the increased model complexity.
Additionally, the paper focuses on a specific set of language-vision tasks, and it would be valuable to explore the generalizability of the approach to a broader range of applications, such as multimodal reasoning and generation.
Furthermore, while the paper demonstrates impressive results on benchmarks, it is crucial to also consider the potential biases and limitations of the datasets used. Careful evaluation of the model's performance in real-world, diverse, and challenging scenarios would provide a more comprehensive understanding of its strengths and weaknesses.
Overall, the paper makes a valuable contribution to the field of language-vision alignment and highlights the potential of leveraging semantic-aware visual representations to enhance the fine-grained understanding of the relationship between language and visual content.
Conclusion
This paper introduces a novel approach to improving the fine-grained alignment between large language models and visual representations. By incorporating semantic-aware visual objects, the proposed method is able to capture more detailed information about the visual elements, leading to enhanced language-vision understanding.
The experimental results demonstrate the effectiveness of this approach, outperforming state-of-the-art methods on a range of language-vision tasks. This work highlights the potential of leveraging rich visual semantics to boost the performance of large language models in applications that require fine-grained multimodal reasoning and generation.
As the field of language-vision AI continues to advance, this research contributes to the growing body of work aimed at bridging the gap between human-like language understanding and the nuanced perception of the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
CoLLaVO: Crayon Large Language and Vision mOdel
Byung-Kwan Lee, Beomchan Park, Chae Won Kim, Yong Man Ro
0
0
The remarkable success of Large Language Models (LLMs) and instruction tuning drives the evolution of Vision Language Models (VLMs) towards a versatile general-purpose model. Yet, it remains unexplored whether current VLMs genuinely possess quality object-level image understanding capabilities determined from 'what objects are in the image?' or 'which object corresponds to a specified bounding box?'. Our findings reveal that the image understanding capabilities of current VLMs are strongly correlated with their zero-shot performance on vision language (VL) tasks. This suggests that prioritizing basic image understanding is crucial for VLMs to excel at VL tasks. To enhance object-level image understanding, we propose Crayon Large Language and Vision mOdel (CoLLaVO), which incorporates instruction tuning with Crayon Prompt as a new visual prompt tuning scheme based on panoptic color maps. Furthermore, we present a learning strategy of Dual QLoRA to preserve object-level image understanding without forgetting it during visual instruction tuning, thereby achieving a significant leap in numerous VL benchmarks in a zero-shot setting.
6/4/2024

Contrasting Intra-Modal and Ranking Cross-Modal Hard Negatives to Enhance Visio-Linguistic Compositional Understanding
Le Zhang, Rabiul Awal, Aishwarya Agrawal
0
0
Vision-Language Models (VLMs), such as CLIP, exhibit strong image-text comprehension abilities, facilitating advances in several downstream tasks such as zero-shot image classification, image-text retrieval, and text-to-image generation. However, the compositional reasoning abilities of existing VLMs remains subpar. The root of this limitation lies in the inadequate alignment between the images and captions in the pretraining datasets. Additionally, the current contrastive learning objective fails to focus on fine-grained grounding components like relations, actions, and attributes, resulting in bag-of-words representations. We introduce a simple and effective method to improve compositional reasoning in VLMs. Our method better leverages available datasets by refining and expanding the standard image-text contrastive learning framework. Our approach does not require specific annotations and does not incur extra parameters. When integrated with CLIP, our technique yields notable improvement over state-of-the-art baselines across five vision-language compositional benchmarks. We open-source our code at https://github.com/lezhang7/Enhance-FineGrained.
4/26/2024

Enhancing Fine-Grained Image Classifications via Cascaded Vision Language Models
Canshi Wei
0
0
Fine-grained image classification, particularly in zero/few-shot scenarios, presents a significant challenge for vision-language models (VLMs), such as CLIP. These models often struggle with the nuanced task of distinguishing between semantically similar classes due to limitations in their pre-trained recipe, which lacks supervision signals for fine-grained categorization. This paper introduces CascadeVLM, an innovative framework that overcomes the constraints of previous CLIP-based methods by effectively leveraging the granular knowledge encapsulated within large vision-language models (LVLMs). Experiments across various fine-grained image datasets demonstrate that CascadeVLM significantly outperforms existing models, specifically on the Stanford Cars dataset, achieving an impressive 85.6% zero-shot accuracy. Performance gain analysis validates that LVLMs produce more accurate predictions for challenging images that CLIPs are uncertain about, bringing the overall accuracy boost. Our framework sheds light on a holistic integration of VLMs and LVLMs for effective and efficient fine-grained image classification.
5/21/2024
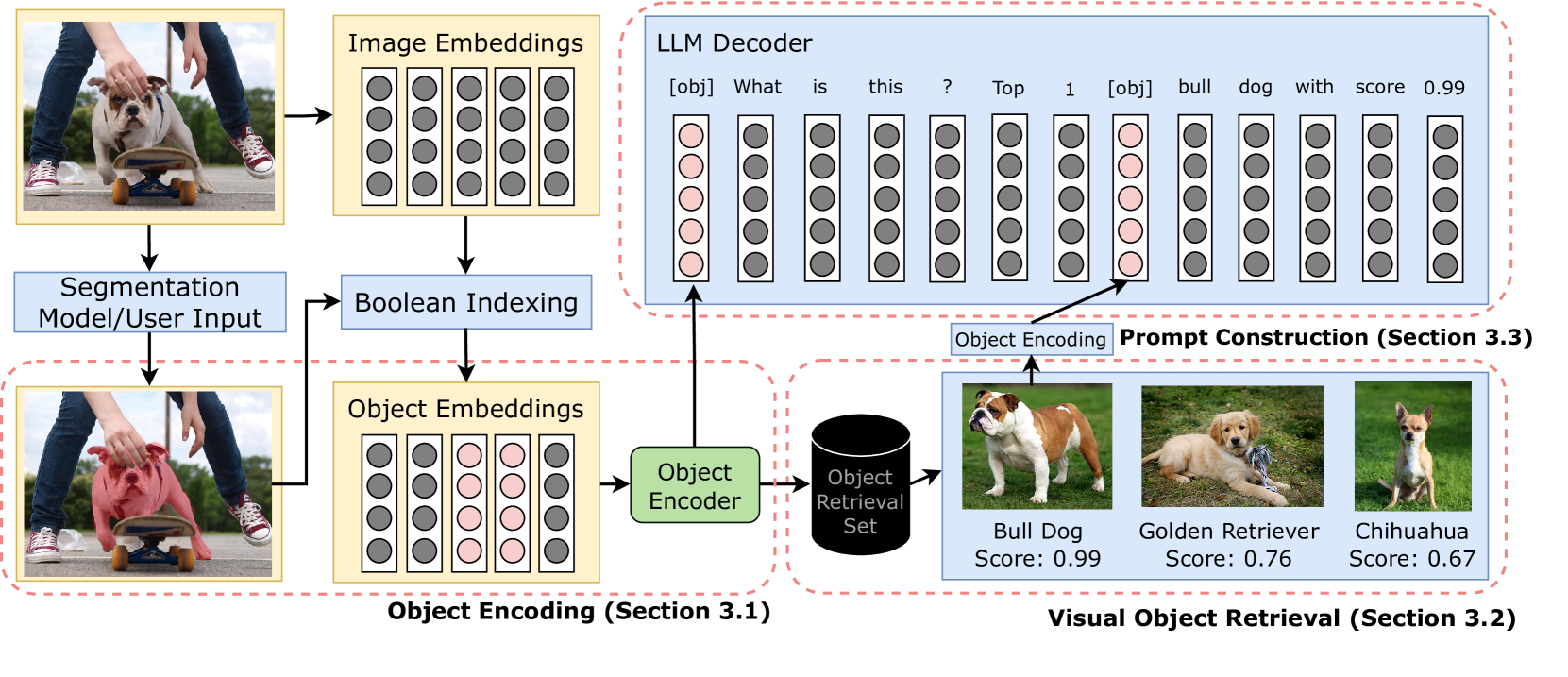
OLIVE: Object Level In-Context Visual Embeddings
Timothy Ossowski, Junjie Hu
0
0
Recent generalist vision-language models (VLMs) have demonstrated impressive reasoning capabilities across diverse multimodal tasks. However, these models still struggle with fine-grained object-level understanding and grounding. In terms of modeling, existing VLMs implicitly align text tokens with image patch tokens, which is ineffective for embedding alignment at the same granularity and inevitably introduces noisy spurious background features. Additionally, these models struggle when generalizing to unseen visual concepts and may not be reliable for domain-specific tasks without further fine-tuning. To address these limitations, we propose a novel method to prompt large language models with in-context visual object vectors, thereby enabling controllable object-level reasoning. This eliminates the necessity of fusing a lengthy array of image patch features and significantly speeds up training. Furthermore, we propose region-level retrieval using our object representations, facilitating rapid adaptation to new objects without additional training. Our experiments reveal that our method achieves competitive referring object classification and captioning performance, while also offering zero-shot generalization and robustness to visually challenging contexts.
6/4/2024