LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT

0

Sign in to get full access
Overview
- LyricWhiz is a robust, multilingual, and zero-shot automatic lyrics transcription method.
- It achieves state-of-the-art performance on various lyrics transcription datasets, even in challenging genres like rock and metal.
- The approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, a high-performance chat-based language model.
Plain English Explanation
LyricWhiz is a new way to automatically transcribe song lyrics, even for songs in different languages and challenging musical styles like rock and metal. It doesn't require any special training or setup - it just works. The key is that it uses two powerful AI models:
-
Whisper: This model can recognize speech really well, even when the audio quality isn't perfect. It acts as the "ear" that listens to the song.
-
GPT-4: This is a very advanced language model that can understand and generate human-like text. It takes the text transcribed by Whisper and polishes it up to be a high-quality lyrics transcript.
By combining these two models in a clever way, the LyricWhiz system can produce accurate lyrics transcripts without needing to be trained on lots of examples first. This makes it a robust and versatile tool for capturing song lyrics, even for music that would be challenging for traditional lyrics transcription methods.
Technical Explanation
The core of the LyricWhiz approach is the integration of Whisper, a state-of-the-art speech recognition model, and GPT-4, a large language model with exceptional text generation capabilities. Whisper acts as the "ear" by transcribing the audio input, while GPT-4 refines and polishes the transcription to produce the final lyrics.
Whisper is a weakly supervised model trained on a diverse dataset of speech and text, which enables it to handle a wide range of audio conditions and accents. By leveraging Whisper's robust transcription abilities, LyricWhiz is able to generate initial lyrics transcripts even for challenging musical genres like rock and metal.
The transcripts produced by Whisper are then passed to GPT-4, which uses its advanced language understanding and generation capabilities to improve the quality of the lyrics. GPT-4 can detect and correct errors, fill in missing words, and rephrase the transcription to make it more coherent and natural-sounding.
Importantly, the LyricWhiz approach is zero-shot, meaning it does not require any task-specific training. The system can be directly applied to new audio inputs without the need for additional fine-tuning or adaptation. This makes LyricWhiz a highly flexible and scalable solution for multilingual lyrics transcription.
Critical Analysis
The LyricWhiz approach leverages state-of-the-art AI models to achieve impressive results in a challenging task. However, there are a few potential limitations and areas for further research:
-
Evaluation on Diverse Datasets: While the paper reports strong performance on various lyrics transcription datasets, it would be valuable to assess the method's robustness across an even wider range of musical genres, languages, and recording conditions.
-
Handling Ambiguity and Context: In some cases, the meaning or intent behind certain lyrics may require deeper understanding of the song's context and the artist's intent. It's unclear how well LyricWhiz would handle such ambiguity and nuance.
-
Ethical Considerations: As with any powerful AI system, there may be ethical concerns around the potential misuse or unintended consequences of LyricWhiz, such as enabling the creation of fake or misleading lyrics. Careful consideration of such issues would be important.
-
Integration with Music Industry Workflows: To maximize the impact of LyricWhiz, it would be valuable to explore how the system could be seamlessly integrated into the workflows and tools used by music professionals, such as music producers, lyricists, and streaming platforms.
Overall, the LyricWhiz approach represents an exciting advancement in the field of lyrics transcription, with the potential to significantly improve the process of capturing and preserving song lyrics, especially for languages and genres that have been underserved by traditional methods.
Conclusion
LyricWhiz is a novel, robust, and multilingual approach to automatic lyrics transcription that leverages the strengths of Whisper and GPT-4. By combining these state-of-the-art AI models, LyricWhiz is able to produce high-quality lyrics transcripts without the need for extensive training or adaptation. This makes the system a versatile and scalable solution for capturing song lyrics, even in challenging musical genres and languages.
While the research presents promising results, further exploration of the system's capabilities, limitations, and potential ethical considerations would be valuable. Integrating LyricWhiz into music industry workflows could also greatly enhance its real-world impact and help preserve the rich tapestry of song lyrics across the globe.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LyricWhiz: Robust Multilingual Zero-shot Lyrics Transcription by Whispering to ChatGPT
Le Zhuo, Ruibin Yuan, Jiahao Pan, Yinghao Ma, Yizhi LI, Ge Zhang, Si Liu, Roger Dannenberg, Jie Fu, Chenghua Lin, Emmanouil Benetos, Wei Xue, Yike Guo
We introduce LyricWhiz, a robust, multilingual, and zero-shot automatic lyrics transcription method achieving state-of-the-art performance on various lyrics transcription datasets, even in challenging genres such as rock and metal. Our novel, training-free approach utilizes Whisper, a weakly supervised robust speech recognition model, and GPT-4, today's most performant chat-based large language model. In the proposed method, Whisper functions as the ear by transcribing the audio, while GPT-4 serves as the brain, acting as an annotator with a strong performance for contextualized output selection and correction. Our experiments show that LyricWhiz significantly reduces Word Error Rate compared to existing methods in English and can effectively transcribe lyrics across multiple languages. Furthermore, we use LyricWhiz to create the first publicly available, large-scale, multilingual lyrics transcription dataset with a CC-BY-NC-SA copyright license, based on MTG-Jamendo, and offer a human-annotated subset for noise level estimation and evaluation. We anticipate that our proposed method and dataset will advance the development of multilingual lyrics transcription, a challenging and emerging task.
Read more7/26/2024

0
Towards Building an End-to-End Multilingual Automatic Lyrics Transcription Model
Jiawen Huang, Emmanouil Benetos
Multilingual automatic lyrics transcription (ALT) is a challenging task due to the limited availability of labelled data and the challenges introduced by singing, compared to multilingual automatic speech recognition. Although some multilingual singing datasets have been released recently, English continues to dominate these collections. Multilingual ALT remains underexplored due to the scale of data and annotation quality. In this paper, we aim to create a multilingual ALT system with available datasets. Inspired by architectures that have been proven effective for English ALT, we adapt these techniques to the multilingual scenario by expanding the target vocabulary set. We then evaluate the performance of the multilingual model in comparison to its monolingual counterparts. Additionally, we explore various conditioning methods to incorporate language information into the model. We apply analysis by language and combine it with the language classification performance. Our findings reveal that the multilingual model performs consistently better than the monolingual models trained on the language subsets. Furthermore, we demonstrate that incorporating language information significantly enhances performance.
Read more6/26/2024
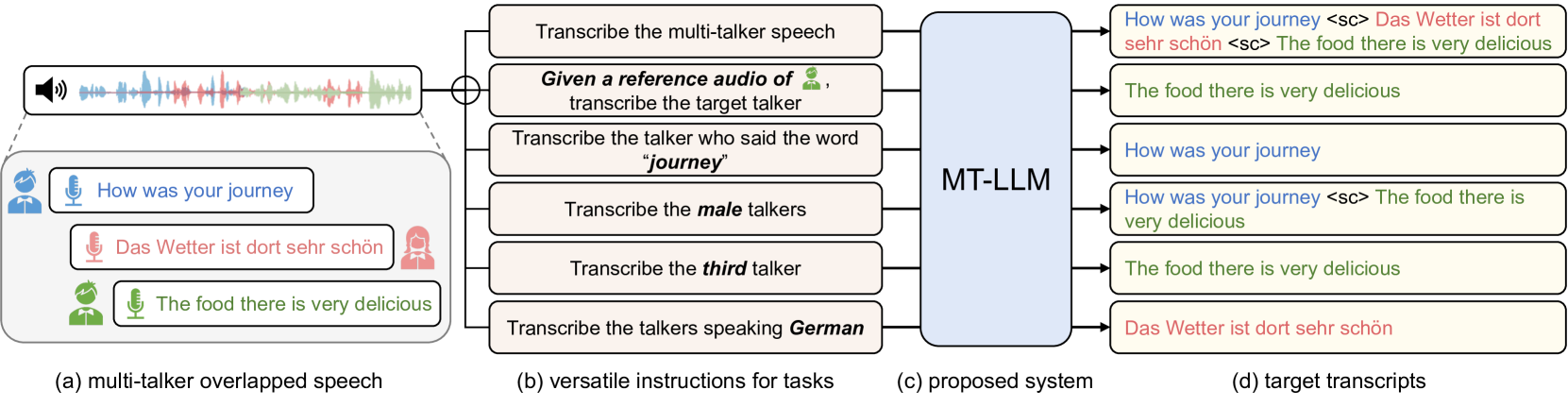
0
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024
🤖
0
Automated Multi-Language to English Machine Translation Using Generative Pre-Trained Transformers
Elijah Pelofske, Vincent Urias, Lorie M. Liebrock
The task of accurate and efficient language translation is an extremely important information processing task. Machine learning enabled and automated translation that is accurate and fast is often a large topic of interest in the machine learning and data science communities. In this study, we examine using local Generative Pretrained Transformer (GPT) models to perform automated zero shot black-box, sentence wise, multi-natural-language translation into English text. We benchmark 16 different open-source GPT models, with no custom fine-tuning, from the Huggingface LLM repository for translating 50 different non-English languages into English using translated TED Talk transcripts as the reference dataset. These GPT model inference calls are performed strictly locally, on single A100 Nvidia GPUs. Benchmark metrics that are reported are language translation accuracy, using BLEU, GLEU, METEOR, and chrF text overlap measures, and wall-clock time for each sentence translation. The best overall performing GPT model for translating into English text for the BLEU metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.152$, for the GLEU metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.256$, for the chrF metric is Llama2-chat-AYT-13B with a mean score across all tested languages of $0.448$, and for the METEOR metric is ReMM-v2-L2-13B with a mean score across all tested languages of $0.438$.
Read more4/24/2024