Towards Building an End-to-End Multilingual Automatic Lyrics Transcription Model

0

Sign in to get full access
Overview
- The paper presents research towards building an end-to-end multilingual automatic lyrics transcription model.
- The goal is to develop a system that can accurately transcribe sung lyrics across multiple languages.
- This would enable applications like automatic captioning for music videos, searchable music databases, and improved music understanding.
Plain English Explanation
The researchers are working on a system that can automatically transcribe the lyrics of songs in different languages. This means the system can listen to a song and type out the words that the singer is singing, even if the song is in a language the system hasn't been trained on before.
This could be very useful for a few reasons. For example, it could allow automatic captions or subtitles to be generated for music videos, so people could read along with the lyrics. It could also enable the creation of searchable databases of song lyrics, making it easier to find specific songs or lyrics. And it could generally improve the way computers understand and process music.
The key challenge is that singing voice is very different from normal speech, so existing speech recognition technology doesn't work well for this task. The researchers are developing new machine learning models and techniques to tackle this problem in a multilingual way, so the system can work for songs in many different languages.
Technical Explanation
The paper proposes an end-to-end deep learning architecture for multilingual automatic lyrics transcription. The model takes raw audio of a singing performance as input and outputs the corresponding lyrics text.
The core of the model is a transformer-based encoder-decoder architecture. The encoder processes the input audio features to produce a high-level representation, while the decoder generates the output text sequence autoregressively. To enable multilingual capabilities, the model uses shared encoder layers and language-specific decoder layers.
The training data consists of paired audio and lyrics text from a diverse set of languages, including English, Chinese, Japanese, and others. The researchers experiment with different data augmentation techniques, such as leveraging parameter-efficient transfer learning and using machine translation to augment multilingual classification, to improve the model's performance on low-resource languages.
Extensive experiments are conducted to evaluate the model's transcription accuracy across multiple languages, singing styles, and audio recording conditions. The results demonstrate the effectiveness of the proposed architecture and training strategies in achieving state-of-the-art multilingual lyrics transcription performance.
Critical Analysis
The paper presents a compelling approach to the challenging problem of multilingual automatic lyrics transcription. By adopting a transformer-based encoder-decoder architecture and leveraging data augmentation techniques, the researchers have made significant progress towards a practical end-to-end solution.
However, the paper also acknowledges several limitations and areas for further research. For example, the model's performance is still heavily dependent on the availability of high-quality parallel audio-lyrics data, which can be difficult to obtain for many languages. The anatomy of an industrial-scale multilingual ASR system highlights the complexity of scaling such systems to real-world deployment.
Additionally, the paper does not address the potential issues of meta-learning for text-to-speech synthesis in a multilingual setting, where differences in prosody and pronunciation across languages can significantly impact the quality of the generated audio.
Further research is needed to explore the generalization capabilities of the proposed model, its robustness to noisy or diverse audio conditions, and its potential to be integrated with other music understanding tasks, such as multilingual answer sentence selection.
Conclusion
The paper presents a promising step towards building an end-to-end multilingual automatic lyrics transcription system. By leveraging advanced deep learning techniques and data augmentation strategies, the researchers have demonstrated the feasibility of accurate lyrics transcription across multiple languages.
While the proposed model has limitations and areas for further development, the research contributes valuable insights and lays the foundation for more robust and scalable multilingual music understanding systems. As these technologies mature, they could enable a wide range of applications, from enhanced music search and recommendation to improved accessibility for music content across global audiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Building an End-to-End Multilingual Automatic Lyrics Transcription Model
Jiawen Huang, Emmanouil Benetos
Multilingual automatic lyrics transcription (ALT) is a challenging task due to the limited availability of labelled data and the challenges introduced by singing, compared to multilingual automatic speech recognition. Although some multilingual singing datasets have been released recently, English continues to dominate these collections. Multilingual ALT remains underexplored due to the scale of data and annotation quality. In this paper, we aim to create a multilingual ALT system with available datasets. Inspired by architectures that have been proven effective for English ALT, we adapt these techniques to the multilingual scenario by expanding the target vocabulary set. We then evaluate the performance of the multilingual model in comparison to its monolingual counterparts. Additionally, we explore various conditioning methods to incorporate language information into the model. We apply analysis by language and combine it with the language classification performance. Our findings reveal that the multilingual model performs consistently better than the monolingual models trained on the language subsets. Furthermore, we demonstrate that incorporating language information significantly enhances performance.
Read more6/26/2024

0
A multilingual training strategy for low resource Text to Speech
Asma Amalas, Mounir Ghogho, Mohamed Chetouani, Rachid Oulad Haj Thami
Recent speech technologies have led to produce high quality synthesised speech due to recent advances in neural Text to Speech (TTS). However, such TTS models depend on extensive amounts of data that can be costly to produce and is hardly scalable to all existing languages, especially that seldom attention is given to low resource languages. With techniques such as knowledge transfer, the burden of creating datasets can be alleviated. In this paper, we therefore investigate two aspects; firstly, whether data from social media can be used for a small TTS dataset construction, and secondly whether cross lingual transfer learning (TL) for a low resource language can work with this type of data. In this aspect, we specifically assess to what extent multilingual modeling can be leveraged as an alternative to training on monolingual corporas. To do so, we explore how data from foreign languages may be selected and pooled to train a TTS model for a target low resource language. Our findings show that multilingual pre-training is better than monolingual pre-training at increasing the intelligibility and naturalness of the generated speech.
Read more9/4/2024
0
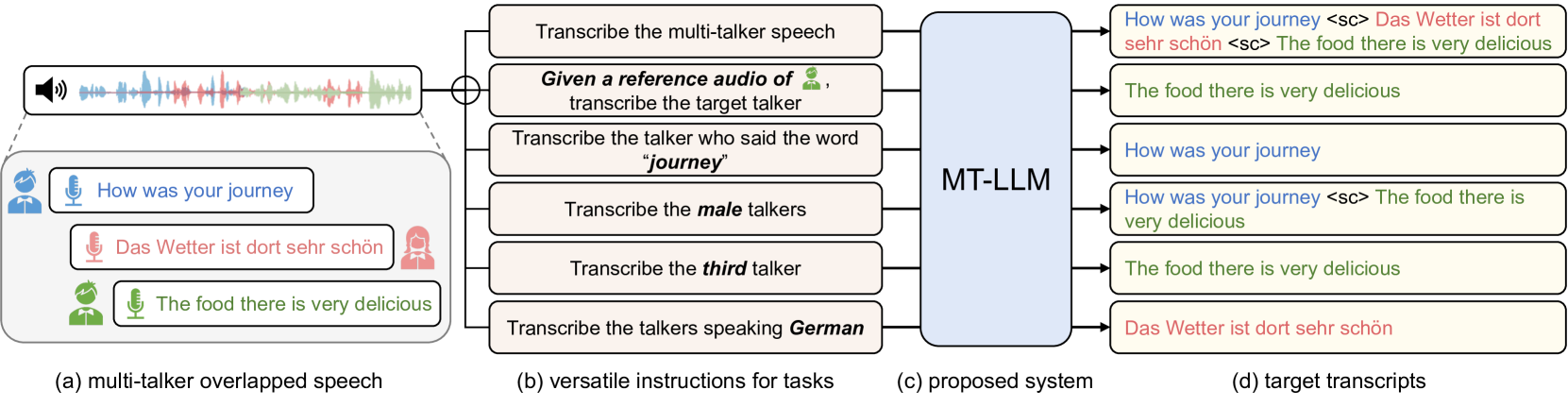
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024
0
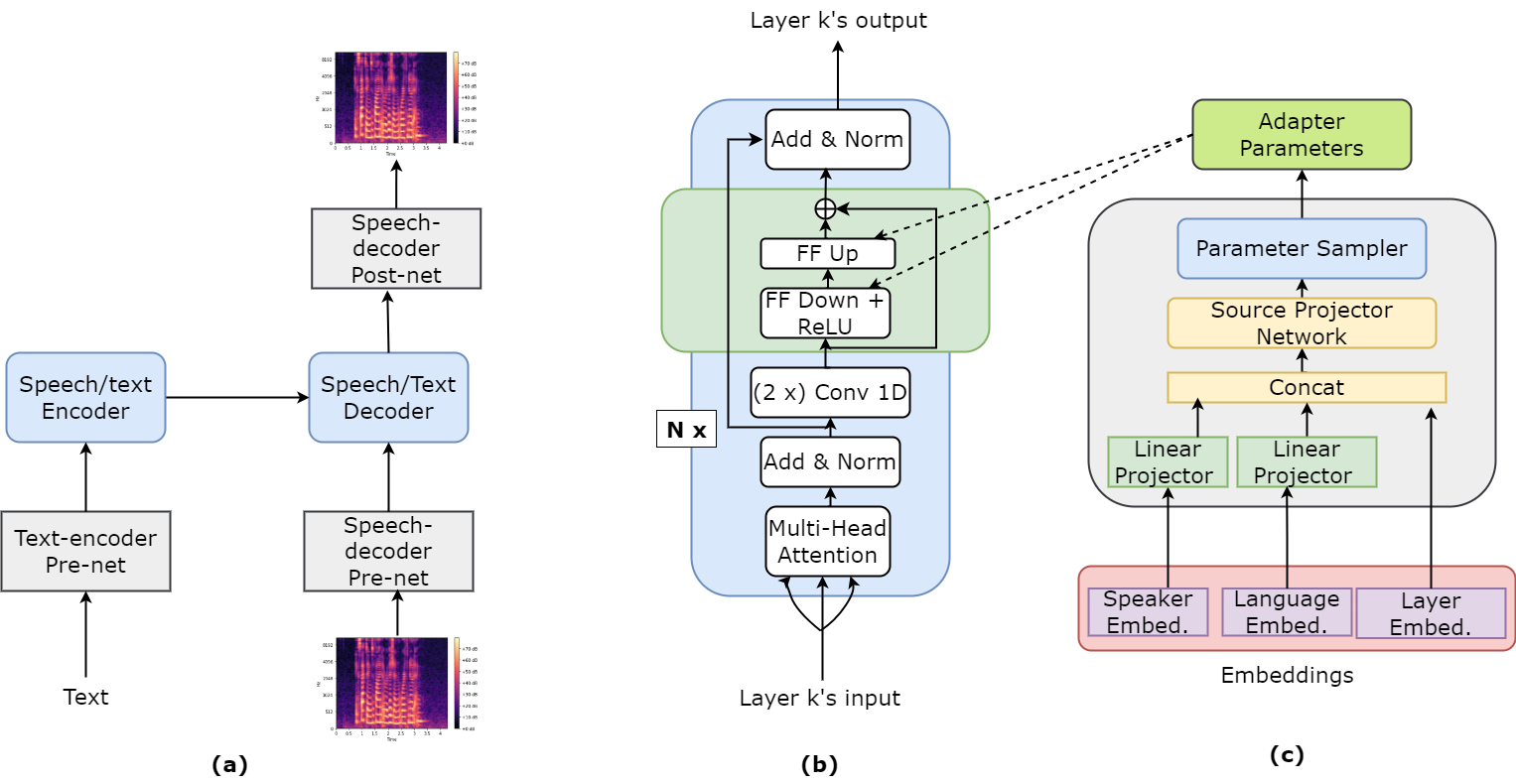
Leveraging Parameter-Efficient Transfer Learning for Multi-Lingual Text-to-Speech Adaptation
Yingting Li, Ambuj Mehrish, Bryan Chew, Bo Cheng, Soujanya Poria
Different languages have distinct phonetic systems and vary in their prosodic features making it challenging to develop a Text-to-Speech (TTS) model that can effectively synthesise speech in multilingual settings. Furthermore, TTS architecture needs to be both efficient enough to capture nuances in multiple languages and efficient enough to be practical for deployment. The standard approach is to build transformer based model such as SpeechT5 and train it on large multilingual dataset. As the size of these models grow the conventional fine-tuning for adapting these model becomes impractical due to heavy computational cost. In this paper, we proposes to integrate parameter-efficient transfer learning (PETL) methods such as adapters and hypernetwork with TTS architecture for multilingual speech synthesis. Notably, in our experiments PETL methods able to achieve comparable or even better performance compared to full fine-tuning with only $sim$2.5% tunable parameters.The code and samples are available at: https://anonymous.4open.science/r/multilingualTTS-BA4C.
Read more6/26/2024