MAIRA-1: A specialised large multimodal model for radiology report generation

0

Sign in to get full access
Overview
- This research paper introduces MAIRA-1, a large multimodal model designed specifically for generating radiology reports from medical images and associated clinical information.
- MAIRA-1 is a specialized model that aims to outperform generalist foundation models on tasks related to radiology report generation.
- The paper explores the model's architecture, training, and evaluation, as well as its potential to enhance the efficiency and accuracy of radiologists' report-writing processes.
Plain English Explanation
MAIRA-1 is a specialized artificial intelligence (AI) model that can help radiologists write their reports more efficiently and accurately. Radiologists often need to analyze medical images, like X-rays or CT scans, and then write detailed reports describing their findings. This can be a time-consuming process.
MAIRA-1 is designed to assist radiologists by generating these reports automatically. It takes medical images and other relevant information as input, and then produces a draft report that the radiologist can review and modify as needed. This could help save radiologists time and improve the consistency of their reports.
The researchers who developed MAIRA-1 believe it is more specialized and capable than more general AI models that could also be used for this task. They argue that a model tailored specifically to the radiology domain can outperform these generalist models. MAIRA-1 is trained on a large dataset of medical images and associated reports, allowing it to learn the unique patterns and language used in radiology.
Overall, MAIRA-1 represents an effort to harness the power of AI to streamline the radiology reporting process and potentially improve patient care. By integrating AI-generated reports, radiologists may be able to focus more on analysis and decision-making, rather than time-consuming documentation.
Technical Explanation
The researchers developed MAIRA-1 as a large, multimodal model that can accept both medical images and associated clinical information as input, and generate natural language radiology reports as output. This multimodal approach is designed to leverage the complementary information from different data sources to improve the model's performance.
The model's architecture builds on recent advancements in large language models, such as those used in the GPT-3 framework. However, MAIRA-1 is trained specifically on a large corpus of radiology reports and associated medical images, enabling it to develop a deeper understanding of the domain-specific language and patterns used in this field.
The researchers evaluated MAIRA-1's performance on several benchmarks, including both automatic metrics (e.g., BLEU scores) and human evaluations of the generated reports. The results suggest that MAIRA-1 outperforms generalist models on radiology-specific tasks, demonstrating the potential benefits of a specialized approach.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. For example, they note that MAIRA-1 may struggle with rare or unusual medical conditions that are not well-represented in the training data. Additionally, the model's performance could be influenced by biases present in the training data, which may lead to inconsistencies or inaccuracies in the generated reports.
Further research is needed to better understand the model's strengths and weaknesses, as well as its potential impact on radiologists' workflow and patient outcomes. It will be important to carefully evaluate the safety and reliability of MAIRA-1's outputs before deploying it in clinical settings.
Conclusion
The MAIRA-1 model represents a promising step towards leveraging advanced AI techniques to enhance the radiology reporting process. By developing a specialized, multimodal model that can generate high-quality reports, the researchers aim to improve the efficiency and consistency of radiologists' work, ultimately benefiting patient care.
However, the research also highlights the need for continued scrutiny and refinement of such AI systems to ensure their reliability and safety. As the field of medical AI continues to evolve, it will be crucial to balance the potential benefits with a thorough understanding of the limitations and risks involved.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MAIRA-1: A specialised large multimodal model for radiology report generation
Stephanie L. Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Mercy Ranjit, Anton Schwaighofer, Fernando P'erez-Garc'ia, Valentina Salvatelli, Shaury Srivastav, Anja Thieme, Noel Codella, Matthew P. Lungren, Maria Teodora Wetscherek, Ozan Oktay, Javier Alvarez-Valle
We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.
Read more4/29/2024

0
MAIRA-2: Grounded Radiology Report Generation
Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Anton Schwaighofer, Anja Thieme, Sam Bond-Taylor, Maximilian Ilse, Fernando P'erez-Garc'ia, Valentina Salvatelli, Harshita Sharma, Felix Meissen, Mercy Ranjit, Shaury Srivastav, Julia Gong, Noel C. F. Codella, Fabian Falck, Ozan Oktay, Matthew P. Lungren, Maria Teodora Wetscherek, Javier Alvarez-Valle, Stephanie L. Hyland
Radiology reporting is a complex task requiring detailed medical image understanding and precise language generation, for which generative multimodal models offer a promising solution. However, to impact clinical practice, models must achieve a high level of both verifiable performance and utility. We augment the utility of automated report generation by incorporating localisation of individual findings on the image - a task we call grounded report generation - and enhance performance by incorporating realistic reporting context as inputs. We design a novel evaluation framework (RadFact) leveraging the logical inference capabilities of large language models (LLMs) to quantify report correctness and completeness at the level of individual sentences, while supporting the new task of grounded reporting. We develop MAIRA-2, a large radiology-specific multimodal model designed to generate chest X-ray reports with and without grounding. MAIRA-2 achieves state of the art on existing report generation benchmarks and establishes the novel task of grounded report generation.
Read more9/23/2024
0
M4CXR: Exploring Multi-task Potentials of Multi-modal Large Language Models for Chest X-ray Interpretation
Jonggwon Park, Soobum Kim, Byungmu Yoon, Jihun Hyun, Kyoyun Choi
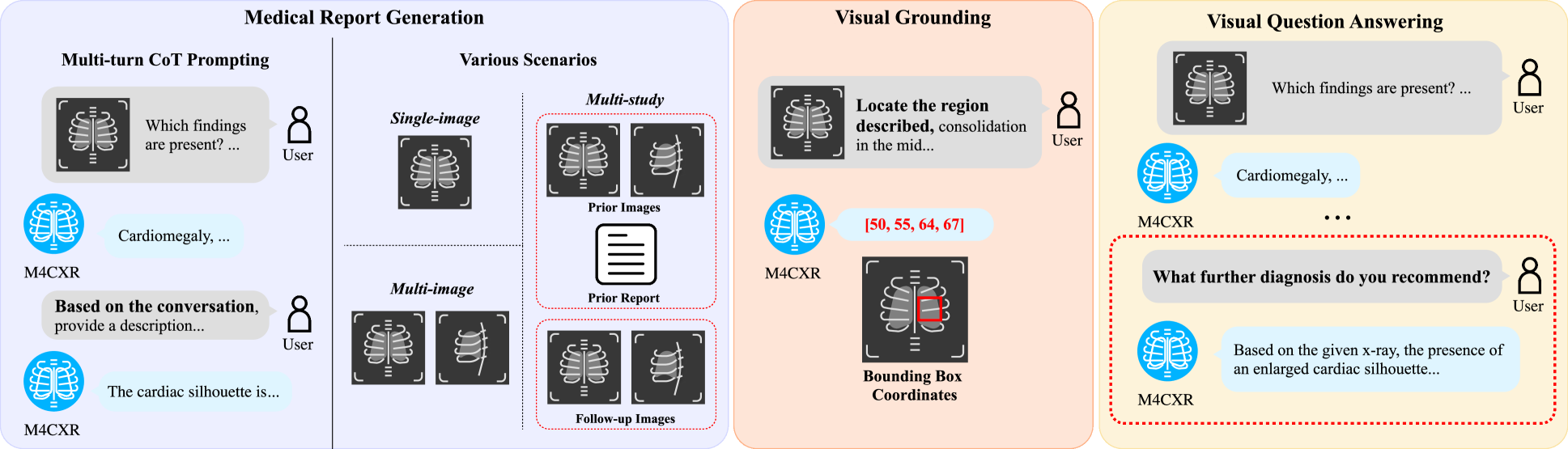
The rapid evolution of artificial intelligence, especially in large language models (LLMs), has significantly impacted various domains, including healthcare. In chest X-ray (CXR) analysis, previous studies have employed LLMs, but with limitations: either underutilizing the multi-tasking capabilities of LLMs or lacking clinical accuracy. This paper presents M4CXR, a multi-modal LLM designed to enhance CXR interpretation. The model is trained on a visual instruction-following dataset that integrates various task-specific datasets in a conversational format. As a result, the model supports multiple tasks such as medical report generation (MRG), visual grounding, and visual question answering (VQA). M4CXR achieves state-of-the-art clinical accuracy in MRG by employing a chain-of-thought prompting strategy, in which it identifies findings in CXR images and subsequently generates corresponding reports. The model is adaptable to various MRG scenarios depending on the available inputs, such as single-image, multi-image, and multi-study contexts. In addition to MRG, M4CXR performs visual grounding at a level comparable to specialized models and also demonstrates outstanding performance in VQA. Both quantitative and qualitative assessments reveal M4CXR's versatility in MRG, visual grounding, and VQA, while consistently maintaining clinical accuracy.
Read more8/30/2024
0
CXR-Agent: Vision-language models for chest X-ray interpretation with uncertainty aware radiology reporting
Naman Sharma
Recently large vision-language models have shown potential when interpreting complex images and generating natural language descriptions using advanced reasoning. Medicine's inherently multimodal nature incorporating scans and text-based medical histories to write reports makes it conducive to benefit from these leaps in AI capabilities. We evaluate the publicly available, state of the art, foundational vision-language models for chest X-ray interpretation across several datasets and benchmarks. We use linear probes to evaluate the performance of various components including CheXagent's vision transformer and Q-former, which outperform the industry-standard Torch X-ray Vision models across many different datasets showing robust generalisation capabilities. Importantly, we find that vision-language models often hallucinate with confident language, which slows down clinical interpretation. Based on these findings, we develop an agent-based vision-language approach for report generation using CheXagent's linear probes and BioViL-T's phrase grounding tools to generate uncertainty-aware radiology reports with pathologies localised and described based on their likelihood. We thoroughly evaluate our vision-language agents using NLP metrics, chest X-ray benchmarks and clinical evaluations by developing an evaluation platform to perform a user study with respiratory specialists. Our results show considerable improvements in accuracy, interpretability and safety of the AI-generated reports. We stress the importance of analysing results for normal and abnormal scans separately. Finally, we emphasise the need for larger paired (scan and report) datasets alongside data augmentation to tackle overfitting seen in these large vision-language models.
Read more7/15/2024