MAD Speech: Measures of Acoustic Diversity of Speech

0

Sign in to get full access
Overview
- The paper presents MAD Speech, a set of measures to quantify the acoustic diversity of speech.
- These measures can be used to assess the performance of speech generation models, particularly in terms of their ability to produce diverse and natural-sounding speech.
- The researchers developed several new metrics, including Acoustic Diversity, Acoustic Richness, and Acoustic Novelty, and evaluated them on several speech datasets.
Plain English Explanation
The paper introduces a new way to measure the diversity of speech generated by AI models. When you train an AI to generate speech, like for a virtual assistant, you want it to be able to produce a wide range of natural-sounding speech, not just the same few phrases over and over. The researchers developed new metrics, or ways of calculating, the acoustic diversity, acoustic richness, and acoustic novelty of the speech. They tested these metrics on different speech datasets to see how well they work. This can help researchers and companies building speech AI systems to better understand and improve the diversity of the speech their models can generate.
Technical Explanation
The paper introduces MAD Speech, a set of measures to quantify the acoustic diversity of speech generated by AI models. The key measures developed are:
- Acoustic Diversity: Measures the overall variation in the acoustic features of the generated speech.
- Acoustic Richness: Captures the breadth of the acoustic space covered by the generated speech.
- Acoustic Novelty: Quantifies how different each generated utterance is from the others.
The researchers evaluated these metrics on several speech datasets, including MLAAD, EAS, and Audio-is-All-One. They compared the results to other diversity measures like linguistic diversity to validate the effectiveness of the MAD Speech metrics.
Critical Analysis
The paper provides a comprehensive set of measures to assess the acoustic diversity of generated speech, which is an important aspect of speech AI system performance. However, the evaluation is limited to a few datasets, and the researchers acknowledge that further work is needed to validate the metrics on a wider range of speech generation tasks and models.
Additionally, the paper does not address potential biases or ethical concerns that may arise from using these metrics, such as the risk of reinforcing stereotypes or excluding certain accents or speaking styles. As speech AI systems become more widespread, it will be important for future work to consider these broader societal implications.
Conclusion
The MAD Speech measures introduced in this paper provide a valuable new tool for evaluating the diversity of speech generated by AI models. These metrics can help researchers and developers create more natural and engaging speech AI systems. As the field of speech generation continues to advance, the ideas and insights presented in this paper will likely play an important role in driving further progress.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MAD Speech: Measures of Acoustic Diversity of Speech
Matthieu Futeral, Andrea Agostinelli, Marco Tagliasacchi, Neil Zeghidour, Eugene Kharitonov
Generative spoken language models produce speech in a wide range of voices, prosody, and recording conditions, seemingly approaching the diversity of natural speech. However, the extent to which generated speech is acoustically diverse remains unclear due to a lack of appropriate metrics. We address this gap by developing lightweight metrics of acoustic diversity, which we collectively refer to as MAD Speech. We focus on measuring five facets of acoustic diversity: voice, gender, emotion, accent, and background noise. We construct the metrics as a composition of specialized, per-facet embedding models and an aggregation function that measures diversity within the embedding space. Next, we build a series of datasets with a priori known diversity preferences for each facet. Using these datasets, we demonstrate that our proposed metrics achieve a stronger agreement with the ground-truth diversity than baselines. Finally, we showcase the applicability of our proposed metrics across several real-life evaluation scenarios. MAD Speech will be made publicly accessible.
Read more4/17/2024
📊
0
MADGF: Multi-Agent Data Generation Framework
Peng Xie, Kani Chen
Automatic Speech Recognition (ASR) systems predominantly cater to monolingual inputs and struggle with the complexity introduced by mixed language audio. In this paper, we present a novel Multi-Agent Data Generation Framework (MADGF) to address this challenge. We finetune the open-source multilingual ASR model, Whisper, utilizing our generated Mixed Cantonese and English (MCE) audio dataset, Which achieved an impressive Mix Error Rate (MER) of 14.28%, 35.13% lower than the original model. Meanwhile, single language recognition ability is not affected, 12.6% Character Error Rate (CER) in Common voice zh-HK, 14.8% Word Error Rate (WER) in Common voice en. However, these metrics do not encompass all aspects critical to the ASR systems. Hence, we propose a novel evaluation metric called Fidelity to the Original Audio, Accuracy, and Latency (FAL).
Read more6/12/2024
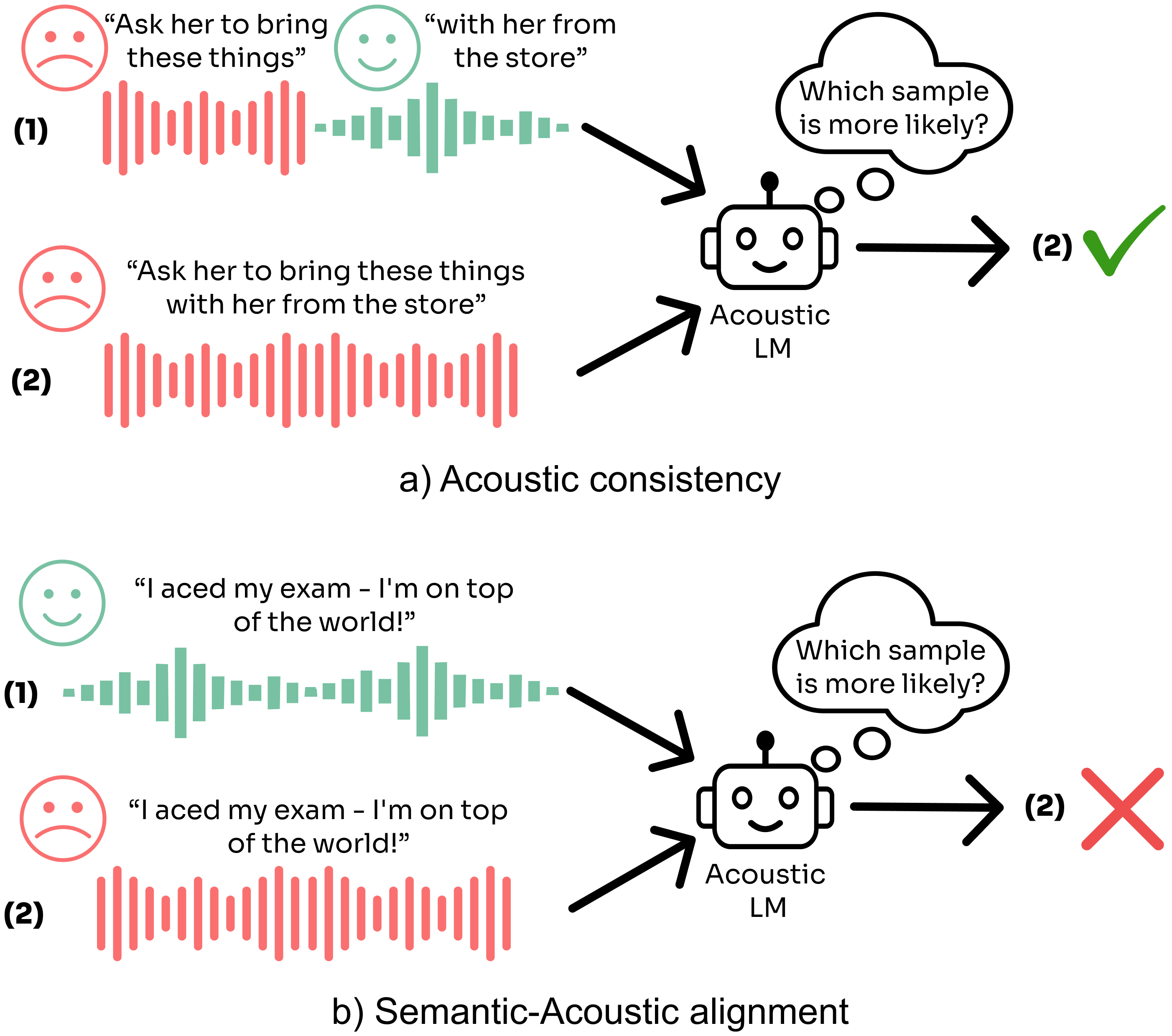
0
A Suite for Acoustic Language Model Evaluation
Gallil Maimon, Amit Roth, Yossi Adi
Speech language models have recently demonstrated great potential as universal speech processing systems. Such models have the ability to model the rich acoustic information existing in audio signals, beyond spoken content, such as emotion, background noise, etc. Despite this, evaluation benchmarks which evaluate awareness to a wide range of acoustic aspects, are lacking. To help bridge this gap, we introduce SALMon, a novel evaluation suite encompassing background noise, emotion, speaker identity and room impulse response. The proposed benchmarks both evaluate the consistency of the inspected element and how much it matches the spoken text. We follow a modelling based approach, measuring whether a model gives correct samples higher scores than incorrect ones. This approach makes the benchmark fast to compute even for large models. We evaluated several speech language models on SALMon, thus highlighting the strengths and weaknesses of each evaluated method. Code and data are publicly available at https://pages.cs.huji.ac.il/adiyoss-lab/salmon/ .
Read more9/12/2024

0
DASB -- Discrete Audio and Speech Benchmark
Pooneh Mousavi, Luca Della Libera, Jarod Duret, Artem Ploujnikov, Cem Subakan, Mirco Ravanelli
Discrete audio tokens have recently gained considerable attention for their potential to connect audio and language processing, enabling the creation of modern multimodal large language models. Ideal audio tokens must effectively preserve phonetic and semantic content along with paralinguistic information, speaker identity, and other details. While several types of audio tokens have been recently proposed, identifying the optimal tokenizer for various tasks is challenging due to the inconsistent evaluation settings in existing studies. To address this gap, we release the Discrete Audio and Speech Benchmark (DASB), a comprehensive leaderboard for benchmarking discrete audio tokens across a wide range of discriminative tasks, including speech recognition, speaker identification and verification, emotion recognition, keyword spotting, and intent classification, as well as generative tasks such as speech enhancement, separation, and text-to-speech. Our results show that, on average, semantic tokens outperform compression tokens across most discriminative and generative tasks. However, the performance gap between semantic tokens and standard continuous representations remains substantial, highlighting the need for further research in this field.
Read more6/24/2024