A Suite for Acoustic Language Model Evaluation

0
Sign in to get full access
Overview
- This paper introduces a suite of evaluation tasks for acoustic language models.
- The suite includes tasks for assessing the performance of language models on a variety of speech-related challenges.
- The goal is to provide a standardized way to evaluate and compare different acoustic language models.
Plain English Explanation
The paper describes a collection of evaluation tasks that can be used to assess the capabilities of language models when it comes to speech-related applications. Language models are artificial intelligence systems that have been trained on large amounts of text data to understand and generate human language.
While language models have become increasingly sophisticated, most evaluation has focused on their performance on written text. This paper argues that it's also important to evaluate how well they can handle speech-related challenges, such as understanding spoken language, recognizing accents and dialects, or generating natural-sounding speech.
The evaluation suite includes tasks like speech recognition, where the model must transcribe spoken audio, and speaker identification, where the model must determine who is speaking. There are also tasks related to dialog understanding and text-to-speech generation.
By providing a standardized set of evaluation tasks, the researchers hope to make it easier for researchers and developers to compare the performance of different acoustic language models. This could help drive progress in areas like voice assistants, real-time translation, and other speech-based technologies.
Technical Explanation
The paper introduces a Suite for Acoustic Language Model Evaluation, which consists of a set of tasks designed to assess the performance of language models on speech-related challenges. The tasks include:
- Speech Recognition: Transcribing spoken audio into text
- Speaker Identification: Determining who is speaking in an audio clip
- Dialog Understanding: Comprehending and responding to spoken dialog
- Text-to-Speech: Generating natural-sounding synthetic speech from text
The researchers argue that while language models have become highly capable on written text, their performance on speech-related tasks has received less attention. This suite aims to provide a standardized way to evaluate and compare different acoustic language models.
The tasks are designed to cover a range of speech-related challenges, such as handling accents, background noise, and conversational speech. The researchers also introduce new benchmark datasets for some of the tasks, to enable more rigorous and consistent evaluations.
By providing this evaluation suite, the researchers hope to drive progress in areas like voice assistants, real-time translation, and other speech-based technologies that rely on advanced language understanding and generation capabilities.
Critical Analysis
The paper makes a compelling case for the need to expand language model evaluation beyond written text and into the realm of speech processing. The proposed evaluation suite covers a diverse set of relevant tasks and the introduction of new benchmark datasets is a valuable contribution.
However, the paper does not address some potential limitations or caveats of the approach. For example, it's unclear how the individual tasks in the suite relate to real-world, end-user applications of acoustic language models. There may be a need for additional, more holistic evaluation scenarios that capture the end-to-end user experience.
Additionally, the paper does not discuss potential biases or fairness issues that could arise in these speech-related tasks, such as the model's performance on diverse accents, dialects, or speaker demographics. Ensuring the robustness and fairness of acoustic language models is an important consideration that could be explored further.
Finally, the paper does not provide much insight into the specific design choices behind the evaluation tasks or the rationale for the selected benchmarks. Some additional discussion of these aspects could help readers better understand the scope and limitations of the proposed suite.
Conclusion
This paper introduces a comprehensive suite of evaluation tasks for assessing the capabilities of acoustic language models. By providing a standardized way to measure performance on speech-related challenges, the researchers aim to drive progress in areas like voice assistants and real-time translation.
The evaluation suite covers a diverse range of tasks, from speech recognition to dialog understanding, and includes the introduction of new benchmark datasets. This is a valuable contribution that could help researchers and developers better understand the strengths and weaknesses of different acoustic language models.
While the paper makes a strong case for the importance of speech-focused language model evaluation, there are some potential limitations and areas for further exploration, such as the need for more holistic end-user scenarios and considerations of bias and fairness. Overall, this work represents an important step in advancing the state of the art in acoustic language modeling and its applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Suite for Acoustic Language Model Evaluation
Gallil Maimon, Amit Roth, Yossi Adi
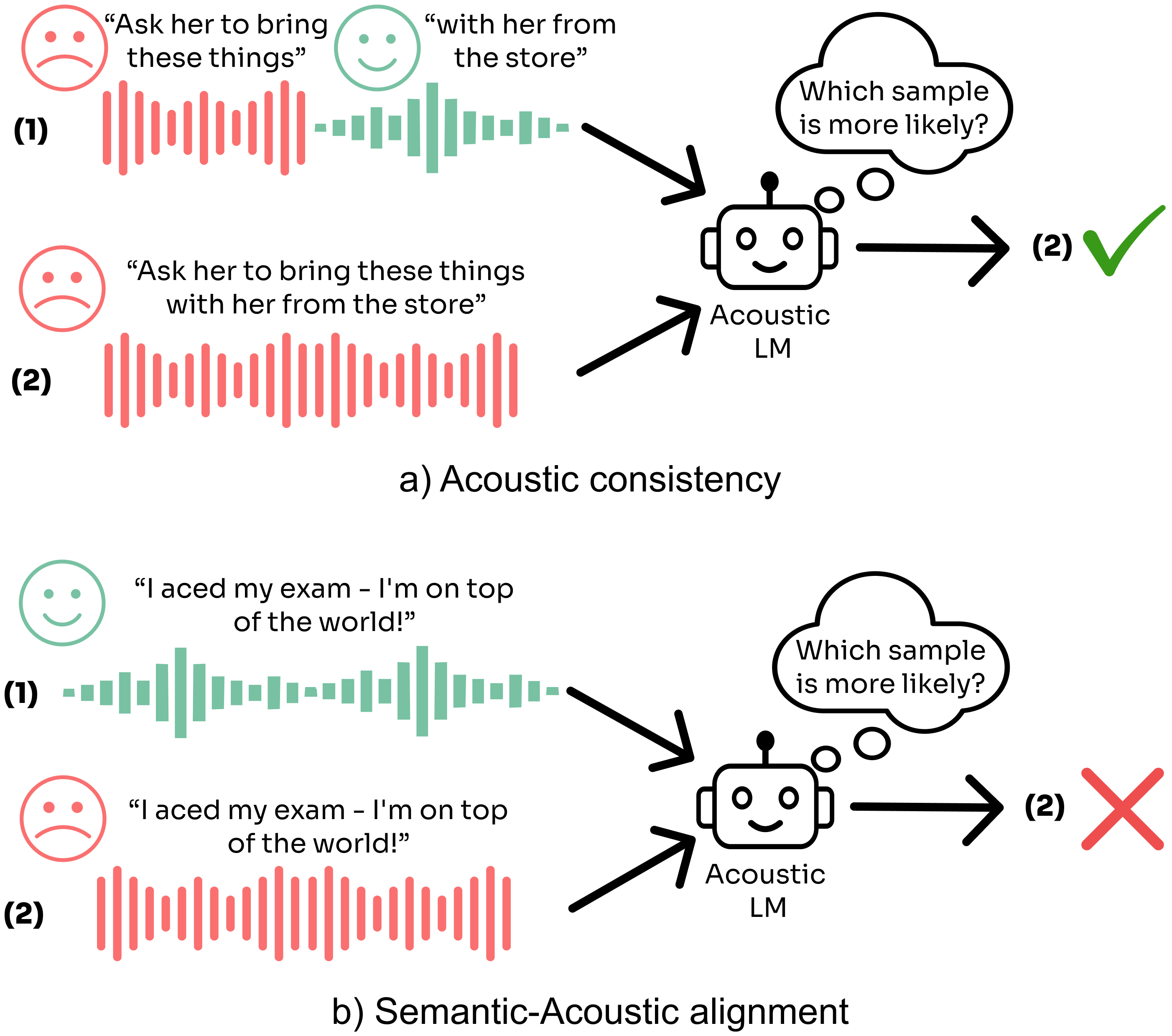
Speech language models have recently demonstrated great potential as universal speech processing systems. Such models have the ability to model the rich acoustic information existing in audio signals, beyond spoken content, such as emotion, background noise, etc. Despite this, evaluation benchmarks which evaluate awareness to a wide range of acoustic aspects, are lacking. To help bridge this gap, we introduce SALMon, a novel evaluation suite encompassing background noise, emotion, speaker identity and room impulse response. The proposed benchmarks both evaluate the consistency of the inspected element and how much it matches the spoken text. We follow a modelling based approach, measuring whether a model gives correct samples higher scores than incorrect ones. This approach makes the benchmark fast to compute even for large models. We evaluated several speech language models on SALMon, thus highlighting the strengths and weaknesses of each evaluated method. Code and data are publicly available at https://pages.cs.huji.ac.il/adiyoss-lab/salmon/ .
Read more9/12/2024
0
SD-Eval: A Benchmark Dataset for Spoken Dialogue Understanding Beyond Words
Junyi Ao, Yuancheng Wang, Xiaohai Tian, Dekun Chen, Jun Zhang, Lu Lu, Yuxuan Wang, Haizhou Li, Zhizheng Wu
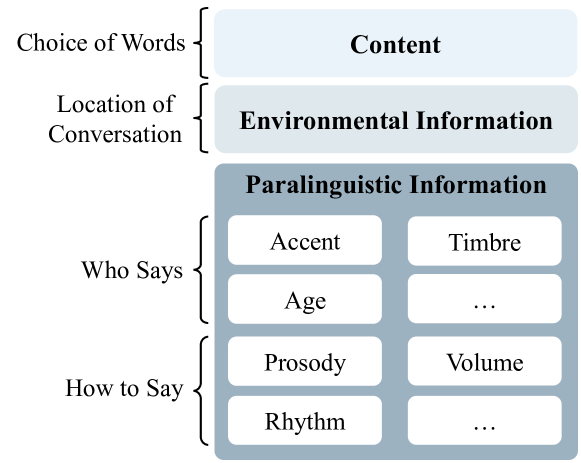
Speech encompasses a wealth of information, including but not limited to content, paralinguistic, and environmental information. This comprehensive nature of speech significantly impacts communication and is crucial for human-computer interaction. Chat-Oriented Large Language Models (LLMs), known for their general-purpose assistance capabilities, have evolved to handle multi-modal inputs, including speech. Although these models can be adept at recognizing and analyzing speech, they often fall short of generating appropriate responses. We argue that this is due to the lack of principles on task definition and model development, which requires open-source datasets and metrics suitable for model evaluation. To bridge the gap, we present SD-Eval, a benchmark dataset aimed at multidimensional evaluation of spoken dialogue understanding and generation. SD-Eval focuses on paralinguistic and environmental information and includes 7,303 utterances, amounting to 8.76 hours of speech data. The data is aggregated from eight public datasets, representing four perspectives: emotion, accent, age, and background sound. To assess the SD-Eval benchmark dataset, we implement three different models and construct a training set following a similar process as SD-Eval. The training set contains 1,052.72 hours of speech data and 724.4k utterances. We also conduct a comprehensive evaluation using objective evaluation methods (e.g. BLEU and ROUGE), subjective evaluations and LLM-based metrics for the generated responses. Models conditioned with paralinguistic and environmental information outperform their counterparts in both objective and subjective measures. Moreover, experiments demonstrate LLM-based metrics show a higher correlation with human evaluation compared to traditional metrics. We open-source SD-Eval at https://github.com/amphionspace/SD-Eval.
Read more6/21/2024

0
AudioBench: A Universal Benchmark for Audio Large Language Models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, Nancy F. Chen
We introduce AudioBench, a universal benchmark designed to evaluate Audio Large Language Models (AudioLLMs). It encompasses 8 distinct tasks and 26 datasets, among which, 7 are newly proposed datasets. The evaluation targets three main aspects: speech understanding, audio scene understanding, and voice understanding (paralinguistic). Despite recent advancements, there lacks a comprehensive benchmark for AudioLLMs on instruction following capabilities conditioned on audio signals. AudioBench addresses this gap by setting up datasets as well as desired evaluation metrics. Besides, we also evaluated the capabilities of five popular models and found that no single model excels consistently across all tasks. We outline the research outlook for AudioLLMs and anticipate that our open-sourced evaluation toolkit, data, and leaderboard will offer a robust testbed for future model developments.
Read more9/4/2024
1
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, Chao Zhang
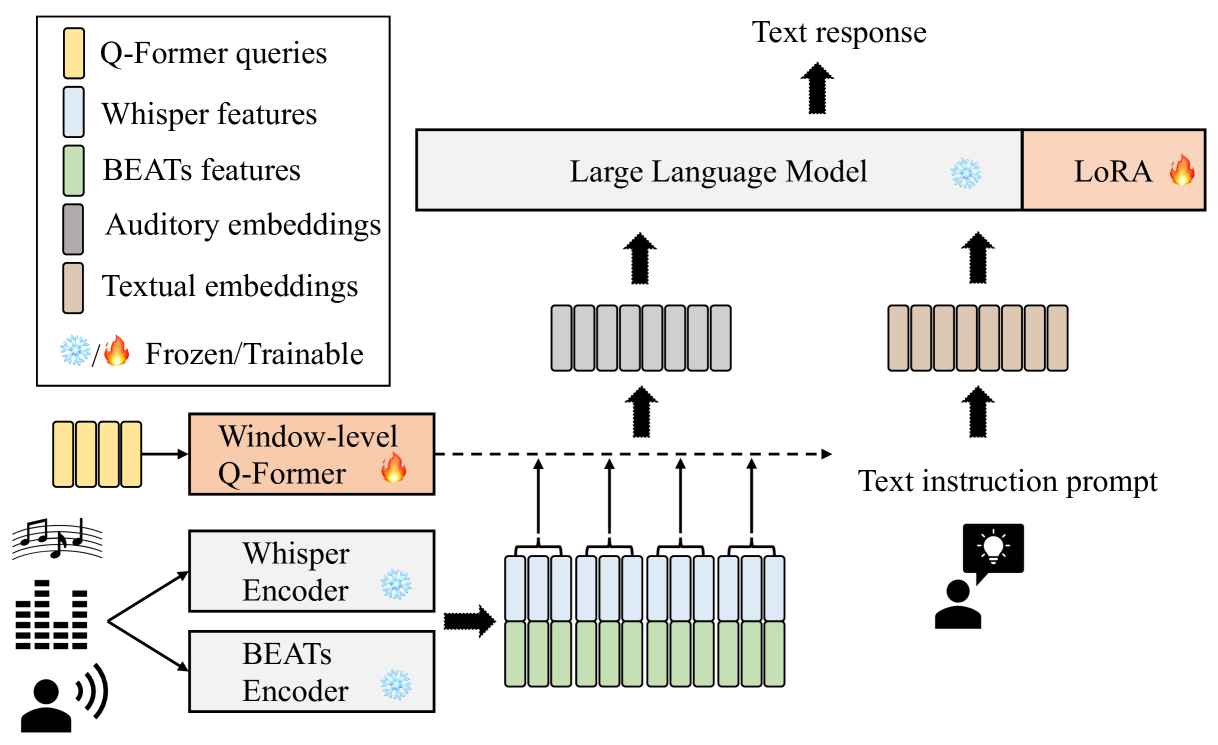
Hearing is arguably an essential ability of artificial intelligence (AI) agents in the physical world, which refers to the perception and understanding of general auditory information consisting of at least three types of sounds: speech, audio events, and music. In this paper, we propose SALMONN, a speech audio language music open neural network, built by integrating a pre-trained text-based large language model (LLM) with speech and audio encoders into a single multimodal model. SALMONN enables the LLM to directly process and understand general audio inputs and achieve competitive performances on a number of speech and audio tasks used in training, such as automatic speech recognition and translation, auditory-information-based question answering, emotion recognition, speaker verification, and music and audio captioning etc. SALMONN also has a diverse set of emergent abilities unseen in the training, which includes but is not limited to speech translation to untrained languages, speech-based slot filling, spoken-query-based question answering, audio-based storytelling, and speech audio co-reasoning etc. The presence of cross-modal emergent abilities is studied, and a novel few-shot activation tuning approach is proposed to activate such abilities. To our knowledge, SALMONN is the first model of its type and can be regarded as a step towards AI with generic hearing abilities. The source code, model checkpoints and data are available at https://github.com/bytedance/SALMONN.
Read more4/9/2024