Made to Order: Discovering monotonic temporal changes via self-supervised video ordering

0
↗️
Sign in to get full access
Overview
- The paper aims to discover and localize monotonic temporal changes in a sequence of images.
- It uses a proxy task of ordering a shuffled image sequence, with 'time' serving as a supervisory signal.
- The paper introduces a flexible transformer-based model for ordering image sequences of arbitrary length, with built-in attribution maps.
- The model can successfully discover and localize monotonic changes while ignoring cyclic and stochastic ones.
- The model is demonstrated in multiple video settings, discovering both object-level and environmental changes.
- The attention-based attribution maps function as effective prompts for segmenting the changing regions.
- The learned representations can be used for downstream applications.
- The model achieves state-of-the-art performance on standard benchmarks for ordering a set of images.
Plain English Explanation
The researchers wanted to find and pinpoint changes that happen gradually over time in a series of images. To do this, they used a simple trick: they scrambled the order of the images and asked the model to put them back in the right order. Since only changes that happen gradually with time would help the model figure out the right order, the model ended up discovering and highlighting those changes.
They developed a flexible transformer-based model that can order image sequences of any length, and it also provides 'attention maps' that show which parts of the images are changing.
The model was tested on different types of video data, and it was able to find both changes in objects and changes in the environment. The attention maps proved useful for identifying the specific regions that were changing. The representations learned by the model could also be used for other downstream tasks.
Importantly, the model outperformed existing methods on standard benchmarks for ordering a set of images. So this approach seems to be an effective way to discover and understand gradual changes in visual data.
Technical Explanation
The paper presents a novel approach to discover and localize monotonic temporal changes in a sequence of images. The key idea is to exploit a simple proxy task of ordering a shuffled image sequence, with 'time' serving as a supervisory signal. Since only changes that are monotonic with time can give rise to the correct ordering, this task encourages the model to focus on such changes.
The researchers introduce a flexible transformer-based model for general-purpose ordering of image sequences of arbitrary length. This model has built-in attribution maps that indicate which parts of the images are driving the ordering decisions.
After training, the model is able to successfully discover and localize monotonic changes in the image sequence, while ignoring cyclic and stochastic changes. The paper demonstrates applications of the model in multiple video settings, covering different scene and object types. The model is able to discover both object-level and environmental changes in unseen sequences.
An interesting aspect is that the attention-based attribution maps function as effective prompts for segmenting the changing regions. The learned representations from the model can also be leveraged for downstream applications. Finally, the paper shows that the model achieves state-of-the-art performance on standard benchmarks for ordering a set of images.
Critical Analysis
The paper presents a novel and effective approach for discovering and localizing monotonic temporal changes in visual data. By framing the problem as a proxy task of ordering shuffled image sequences, the model is able to focus on the relevant changes while ignoring irrelevant ones.
One potential limitation is that the approach may struggle with more complex types of changes, such as those that are non-monotonic or occur at multiple scales. The paper acknowledges this and suggests that future work could explore ways to handle a broader range of temporal changes.
Additionally, the paper does not provide a detailed analysis of the model's performance on a wider range of datasets and settings. While the results on the tested applications are promising, further validation on a more diverse set of scenarios would help strengthen the claims about the model's general applicability.
It would also be interesting to see how the model's performance compares to other approaches for change detection and video understanding. A more comprehensive benchmarking against state-of-the-art methods would help situate the contributions of this work within the broader context of the field.
Overall, the paper presents a compelling and innovative approach to a challenging problem in computer vision. The ability to discover and localize monotonic changes has numerous potential applications, and the flexible transformer-based model with its interpretable attribution maps is a promising direction for further research.
Conclusion
This paper introduces a novel approach to discover and localize monotonic temporal changes in sequences of images. By formulating the problem as a proxy task of ordering shuffled image sequences, the researchers have developed a flexible transformer-based model that can effectively identify and highlight the relevant changes.
The model's strong performance on standard benchmarks, as well as its ability to handle diverse video settings, demonstrates its potential for practical applications. The interpretable attribution maps provide valuable insights into the model's decision-making process and can be leveraged for tasks like change segmentation.
While the current approach has some limitations in handling more complex types of changes, the paper lays the groundwork for further advancements in this area. Exploring ways to expand the model's capabilities and testing it on a wider range of scenarios could lead to even more impactful applications in fields like video analysis, change detection, and environmental monitoring.
Overall, this research represents an important step forward in understanding and exploiting the temporal dynamics of visual data, with promising implications for both computer vision and the broader scientific community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
0
Made to Order: Discovering monotonic temporal changes via self-supervised video ordering
Charig Yang, Weidi Xie, Andrew Zisserman
Our objective is to discover and localize monotonic temporal changes in a sequence of images. To achieve this, we exploit a simple proxy task of ordering a shuffled image sequence, with `time' serving as a supervisory signal, since only changes that are monotonic with time can give rise to the correct ordering. We also introduce a transformer-based model for ordering of image sequences of arbitrary length with built-in attribution maps. After training, the model successfully discovers and localizes monotonic changes while ignoring cyclic and stochastic ones. We demonstrate applications of the model in multiple domains covering different scene and object types, discovering both object-level and environmental changes in unseen sequences. We also demonstrate that the attention-based attribution maps function as effective prompts for segmenting the changing regions, and that the learned representations can be used for downstream applications. Finally, we show that the model achieves the state-of-the-art on standard benchmarks for image ordering.
Read more8/14/2024

0
Self-Supervised Contrastive Learning for Videos using Differentiable Local Alignment
Keyne Oei, Amr Gomaa, Anna Maria Feit, Jo~ao Belo
Robust frame-wise embeddings are essential to perform video analysis and understanding tasks. We present a self-supervised method for representation learning based on aligning temporal video sequences. Our framework uses a transformer-based encoder to extract frame-level features and leverages them to find the optimal alignment path between video sequences. We introduce the novel Local-Alignment Contrastive (LAC) loss, which combines a differentiable local alignment loss to capture local temporal dependencies with a contrastive loss to enhance discriminative learning. Prior works on video alignment have focused on using global temporal ordering across sequence pairs, whereas our loss encourages identifying the best-scoring subsequence alignment. LAC uses the differentiable Smith-Waterman (SW) affine method, which features a flexible parameterization learned through the training phase, enabling the model to adjust the temporal gap penalty length dynamically. Evaluations show that our learned representations outperform existing state-of-the-art approaches on action recognition tasks.
Read more9/10/2024

0
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Kelian Baert, Shrisha Bharadwaj, Fabien Castan, Benoit Maujean, Marc Christie, Victoria Abrevaya, Adnane Boukhayma
Feedforward monocular face capture methods seek to reconstruct posed faces from a single image of a person. Current state of the art approaches have the ability to regress parametric 3D face models in real-time across a wide range of identities, lighting conditions and poses by leveraging large image datasets of human faces. These methods however suffer from clear limitations in that the underlying parametric face model only provides a coarse estimation of the face shape, thereby limiting their practical applicability in tasks that require precise 3D reconstruction (aging, face swapping, digital make-up, ...). In this paper, we propose a method for high-precision 3D face capture taking advantage of a collection of unconstrained videos of a subject as prior information. Our proposal builds on a two stage approach. We start with the reconstruction of a detailed 3D face avatar of the person, capturing both precise geometry and appearance from a collection of videos. We then use the encoder from a pre-trained monocular face reconstruction method, substituting its decoder with our personalized model, and proceed with transfer learning on the video collection. Using our pre-estimated image formation model, we obtain a more precise self-supervision objective, enabling improved expression and pose alignment. This results in a trained encoder capable of efficiently regressing pose and expression parameters in real-time from previously unseen images, which combined with our personalized geometry model yields more accurate and high fidelity mesh inference. Through extensive qualitative and quantitative evaluation, we showcase the superiority of our final model as compared to state-of-the-art baselines, and demonstrate its generalization ability to unseen pose, expression and lighting.
Read more9/14/2024
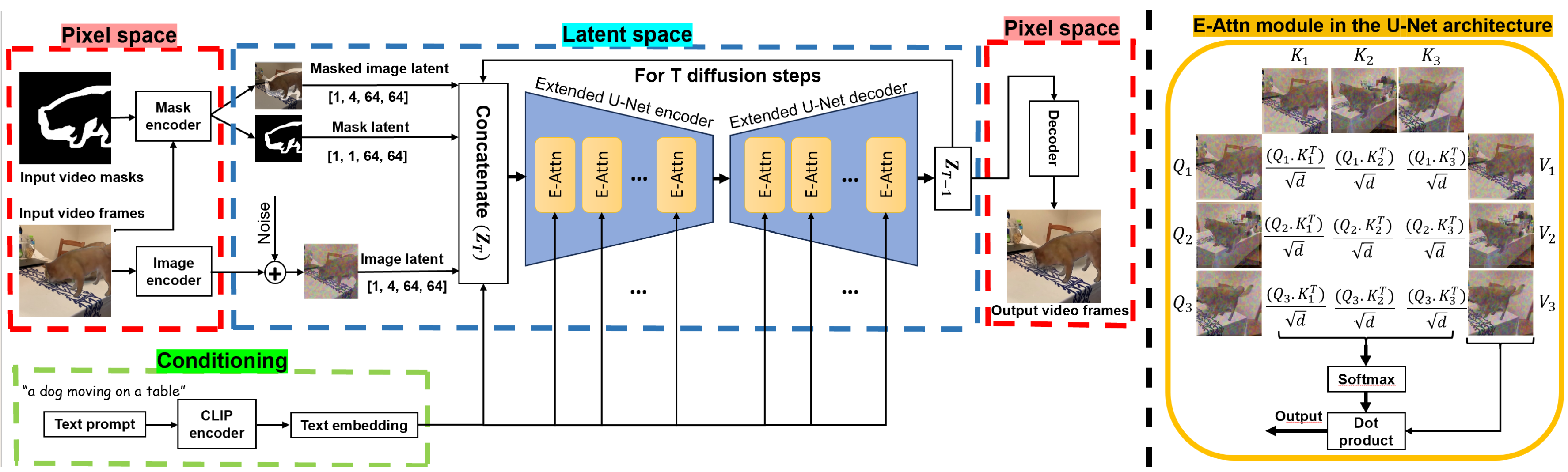
0
Temporally Consistent Object Editing in Videos using Extended Attention
AmirHossein Zamani, Amir G. Aghdam, Tiberiu Popa, Eugene Belilovsky
Image generation and editing have seen a great deal of advancements with the rise of large-scale diffusion models that allow user control of different modalities such as text, mask, depth maps, etc. However, controlled editing of videos still lags behind. Prior work in this area has focused on using 2D diffusion models to globally change the style of an existing video. On the other hand, in many practical applications, editing localized parts of the video is critical. In this work, we propose a method to edit videos using a pre-trained inpainting image diffusion model. We systematically redesign the forward path of the model by replacing the self-attention modules with an extended version of attention modules that creates frame-level dependencies. In this way, we ensure that the edited information will be consistent across all the video frames no matter what the shape and position of the masked area is. We qualitatively compare our results with state-of-the-art in terms of accuracy on several video editing tasks like object retargeting, object replacement, and object removal tasks. Simulations demonstrate the superior performance of the proposed strategy.
Read more6/4/2024