MagicDec: Breaking the Latency-Throughput Tradeoff for Long Context Generation with Speculative Decoding

0

Sign in to get full access
Overview
- The research paper presents MagicDec, a new approach for long context text generation that breaks the latency-throughput tradeoff.
- MagicDec uses speculative decoding, where the model generates multiple candidate tokens in parallel, to increase throughput without sacrificing latency.
- The paper evaluates MagicDec on various long-form text generation tasks and shows significant performance improvements over traditional decoding methods.
Plain English Explanation
The paper introduces a new technique called MagicDec that helps language models generate long passages of text more efficiently. Typically, there is a tradeoff between the speed (latency) and the amount of text generated per second (throughput) when using language models. MagicDec breaks this tradeoff by using a technique called speculative decoding.
In speculative decoding, the model generates multiple possible next tokens in parallel, instead of generating one token at a time sequentially. This allows the model to explore different continuations of the text simultaneously, which increases the overall throughput without significantly increasing the latency (the time it takes to generate each individual token).
The researchers evaluate MagicDec on several long-form text generation tasks, such as summarization and story generation, and show that it outperforms traditional decoding methods in both latency and throughput. This means the model can generate high-quality long-form text much faster than before.
Technical Explanation
The core idea behind MagicDec is to use speculative decoding to break the latency-throughput tradeoff in long-form text generation. In traditional decoding, the model generates one token at a time, sequentially. This results in a linear relationship between the length of the generated text and the total latency.
MagicDec instead generates multiple candidate tokens in parallel at each step, exploring different possible continuations of the text simultaneously. This is achieved by modifying the beam search algorithm, a common decoding method, to generate a wider beam of candidate tokens at each step. The model then selects the most promising candidate and continues generating from there, discarding the less promising ones.
The researchers show that this speculative approach significantly boosts the throughput (the amount of text generated per second) without drastically increasing the latency (the time to generate each individual token). They evaluate MagicDec on various long-form text generation tasks, including summarization, story generation, and open-ended dialogue, and demonstrate substantial performance improvements over traditional decoding methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the MagicDec approach, exploring its performance on a range of long-form text generation tasks. The results clearly demonstrate the benefits of speculative decoding in terms of breaking the latency-throughput tradeoff.
However, the paper does not delve into the potential limitations or caveats of the MagicDec approach. For example, it would be helpful to understand how the method might scale as the context length or the number of candidate tokens increases, and whether there are any scenarios where the performance gains might diminish.
Additionally, the paper does not discuss the potential impact of speculative decoding on the quality or coherence of the generated text. While the results show improved performance on standard metrics, it would be valuable to explore any potential trade-offs in terms of the semantic and linguistic properties of the generated text.
Conclusion
The MagicDec approach presented in this paper represents a significant advancement in the field of long-form text generation. By leveraging speculative decoding, the model is able to generate high-quality long passages of text much more efficiently than traditional methods, breaking the typical latency-throughput tradeoff.
The researchers have demonstrated the effectiveness of MagicDec across a variety of tasks, suggesting that the technique could have broad applications in areas such as summarization, storytelling, and interactive dialogue systems. As large language models continue to grow in size and complexity, techniques like MagicDec will become increasingly important for unlocking their full potential and enabling more seamless and natural interactions with these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MagicDec: Breaking the Latency-Throughput Tradeoff for Long Context Generation with Speculative Decoding
Jian Chen, Vashisth Tiwari, Ranajoy Sadhukhan, Zhuoming Chen, Jinyuan Shi, Ian En-Hsu Yen, Beidi Chen
Large Language Models (LLMs) have become more prevalent in long-context applications such as interactive chatbots, document analysis, and agent workflows, but it is challenging to serve long-context requests with low latency and high throughput. Speculative decoding (SD) is a widely used technique to reduce latency without sacrificing performance but the conventional wisdom suggests that its efficacy is limited to small batch sizes. In MagicDec, we show that surprisingly SD can achieve speedup even for a high throughput inference regime for moderate to long sequences. More interestingly, an intelligent drafting strategy can achieve better speedup with increasing batch size based on our rigorous analysis. MagicDec first identifies the bottleneck shifts with increasing batch size and sequence length, and uses these insights to deploy speculative decoding more effectively for high throughput inference. Then, it leverages draft models with sparse KV cache to address the KV bottleneck that scales with both sequence length and batch size. This finding underscores the broad applicability of speculative decoding in long-context serving, as it can enhance throughput and reduce latency without compromising accuracy. For moderate to long sequences, we demonstrate up to 2x speedup for LLaMA-2-7B-32K and 1.84x speedup for LLaMA-3.1-8B when serving batch sizes ranging from 32 to 256 on 8 NVIDIA A100 GPUs. The code is available at https://github.com/Infini-AI-Lab/MagicDec/.
Read more8/26/2024

0
Optimizing Speculative Decoding for Serving Large Language Models Using Goodput
Xiaoxuan Liu, Cade Daniel, Langxiang Hu, Woosuk Kwon, Zhuohan Li, Xiangxi Mo, Alvin Cheung, Zhijie Deng, Ion Stoica, Hao Zhang
Reducing the inference latency of large language models (LLMs) is crucial, and speculative decoding (SD) stands out as one of the most effective techniques. Rather than letting the LLM generate all tokens directly, speculative decoding employs effective proxies to predict potential outputs, which are then verified by the LLM without compromising the generation quality. Yet, deploying SD in real online LLM serving systems (with continuous batching) does not always yield improvement -- under higher request rates or low speculation accuracy, it paradoxically increases latency. Furthermore, there is no best speculation length work for all workloads under different system loads. Based on the observations, we develop a dynamic framework SmartSpec. SmartSpec dynamically determines the best speculation length for each request (from 0, i.e., no speculation, to many tokens) -- hence the associated speculative execution costs -- based on a new metric called goodput, which characterizes the current observed load of the entire system and the speculation accuracy. We show that SmartSpec consistently reduces average request latency by up to 3.2x compared to non-speculative decoding baselines across different sizes of target models, draft models, request rates, and datasets. Moreover, SmartSpec can be applied to different styles of speculative decoding, including traditional, model-based approaches as well as model-free methods like prompt lookup and tree-style decoding.
Read more6/27/2024
0
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
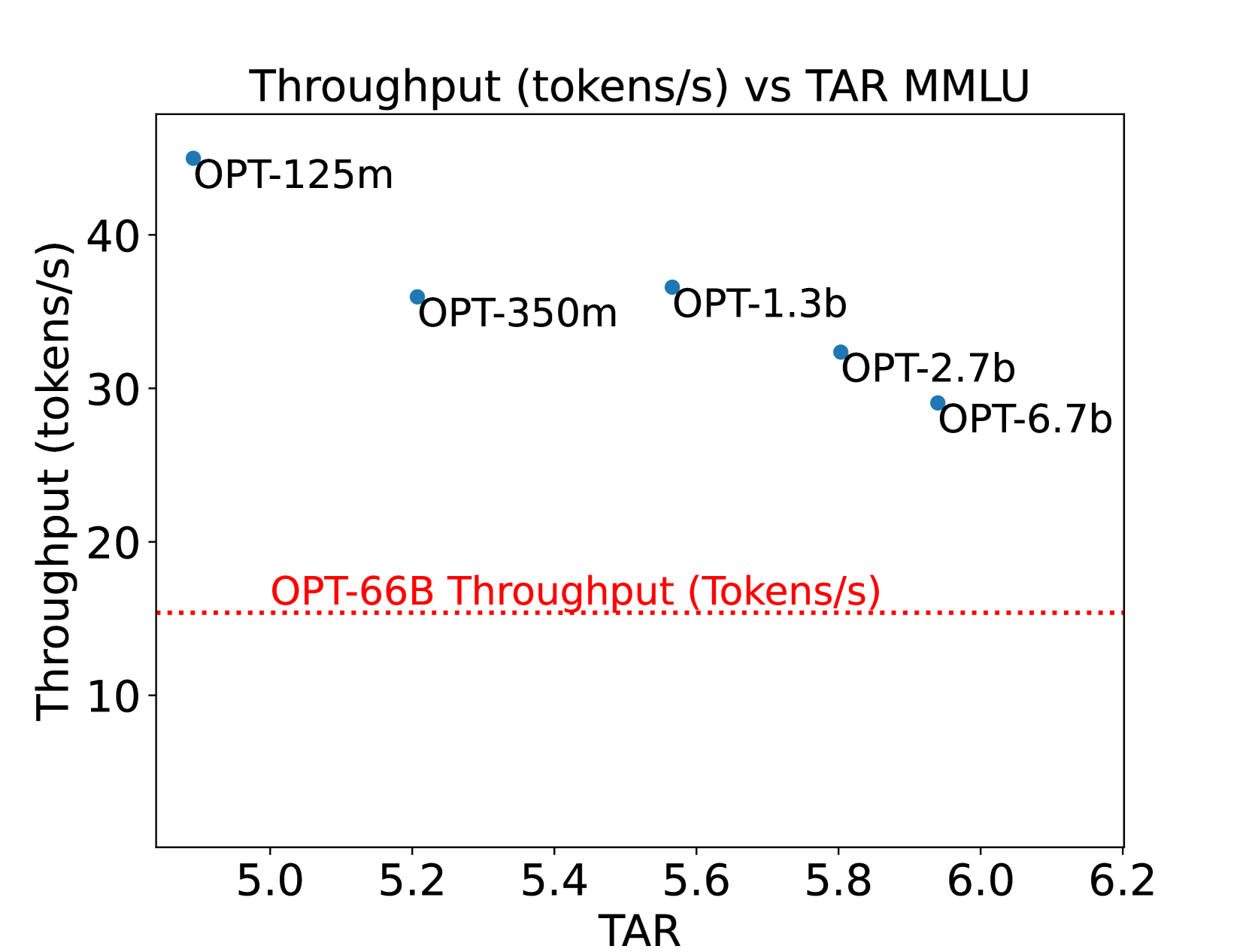
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 111% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
Read more8/13/2024
0
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
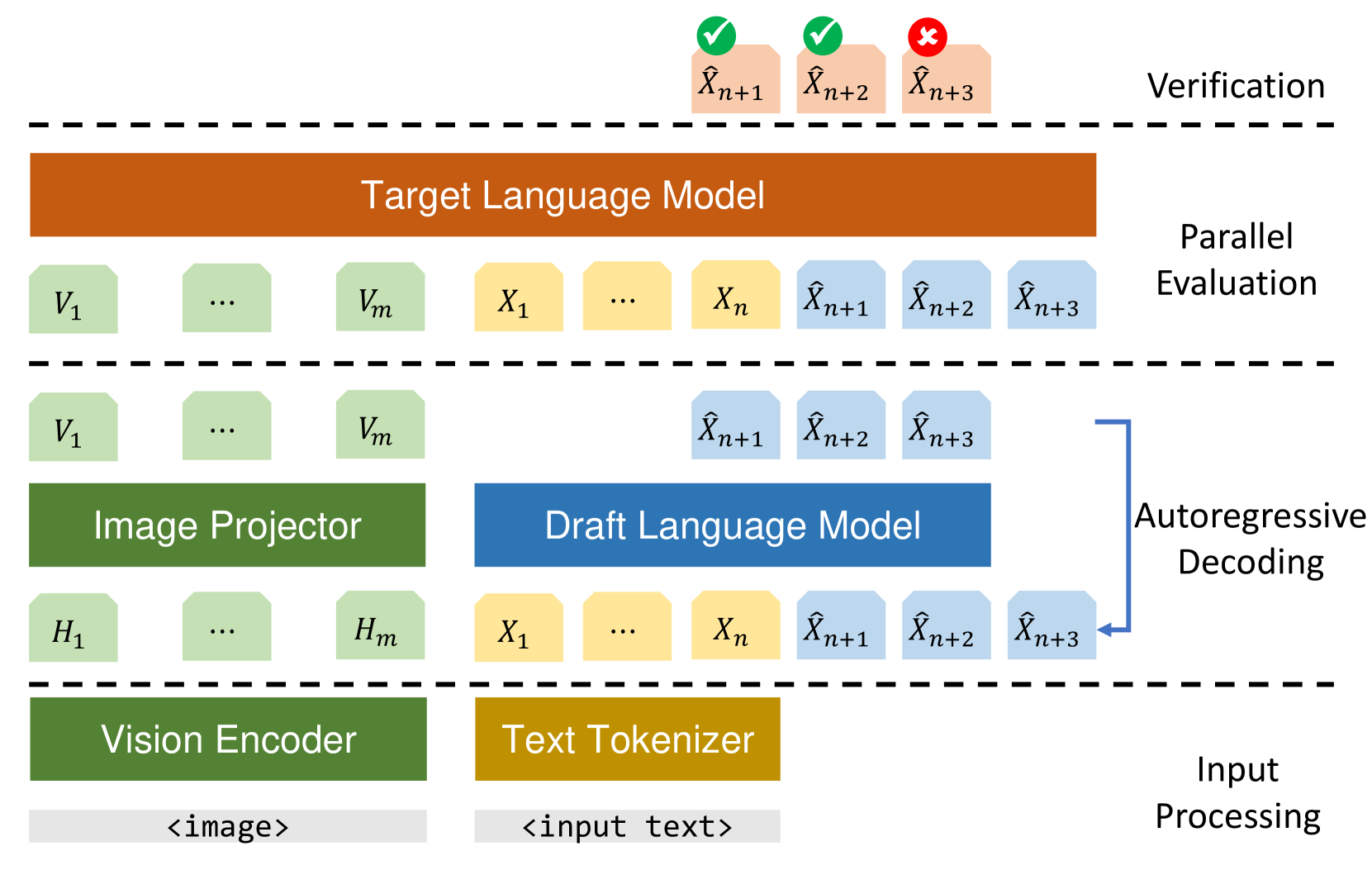
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Read more4/16/2024