Optimizing Speculative Decoding for Serving Large Language Models Using Goodput

0

Sign in to get full access
Overview
- This paper explores techniques to optimize the performance of large language models by improving the efficiency of speculative decoding, a process used to speed up model inference.
- The authors propose a new approach called "goodput" that aims to maximize the useful work performed by the model during speculative decoding, rather than just raw throughput.
- The researchers evaluate their technique on a variety of large language models and find significant performance improvements compared to existing methods.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have become increasingly powerful and capable of generating human-like text. However, running these models can be computationally intensive and time-consuming, which can be a challenge for real-time applications like chatbots or virtual assistants.
One technique used to speed up inference for large language models is called speculative decoding. This involves generating multiple potential outputs in parallel and then selecting the most likely one. While this can improve overall throughput, the authors argue that it may not maximize the useful work performed by the model.
The researchers in this paper introduce a new metric called "goodput" that aims to measure the efficiency of speculative decoding. Goodput focuses on the quality and relevance of the model's outputs, rather than just raw speed. The authors develop a new technique that optimizes for goodput, allowing the model to generate more useful outputs during the speculative decoding process.
Through experimentation on several large language models, the researchers demonstrate that their goodput-based approach can significantly improve performance compared to traditional speculative decoding methods. This could lead to more efficient and responsive large language model-powered applications in the real world.
Technical Explanation
The paper begins by discussing the challenge of serving large language models in real-time applications, where low latency is critical. One technique used to address this is speculative decoding, which involves generating multiple potential outputs in parallel and then selecting the most likely one.
However, the authors argue that traditional speculative decoding approaches may not necessarily maximize the useful work performed by the model. To address this, they introduce a new metric called "goodput" that combines the latency, throughput, and relevance of the model's outputs. The goal is to optimize for the overall utility of the speculative decoding process, rather than just raw speed.
The paper then presents the authors' proposed technique, called "Optimized Speculative Decoding" (OSD), which aims to maximize goodput. OSD uses a combination of techniques, including dynamic speculation, lookahead, and adaptive candidate selection, to generate the most relevant and useful outputs during speculative decoding.
The researchers evaluate OSD on a range of large language models, including GPT-3, BERT, and T5, and find significant performance improvements compared to traditional speculative decoding approaches. The results demonstrate the effectiveness of the goodput-based optimization approach in unlocking the efficiency of large language model inference.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed goodput-based speculative decoding approach. The authors provide a clear and convincing rationale for why traditional throughput-focused techniques may not be optimal, and their introduction of the goodput metric is a valuable contribution to the field.
One potential limitation of the research is that it focuses primarily on the server-side performance of large language models, without considering the implications for end-users. While the goodput-based approach may improve the efficiency of model inference, it's unclear how this would translate to the user experience, particularly in interactive applications where latency and responsiveness are critical.
Additionally, the paper does not delve into the potential trade-offs or challenges that may arise when deploying the OSD technique in real-world scenarios. For example, the impact on energy consumption, memory usage, or the ability to adapt to changing workloads are not discussed in depth.
Further research could explore the online speculative decoding of large language models, which would be more representative of how these models are typically used in production environments. Investigating the impact of goodput-based optimization on end-user experiences, as well as potential system-level trade-offs, would also be valuable areas for future study.
Conclusion
This paper presents a novel approach to optimizing the performance of large language models by focusing on the concept of "goodput" – the quality and relevance of the model's outputs during speculative decoding, rather than just raw throughput. The researchers' Optimized Speculative Decoding (OSD) technique demonstrates significant improvements in efficiency compared to traditional methods, which could lead to more responsive and effective real-world applications of these powerful language models.
While the paper provides a strong technical foundation, further research is needed to fully understand the implications and potential limitations of the goodput-based approach, particularly in terms of end-user experiences and system-level tradeoffs. Nevertheless, this work represents an important step forward in the ongoing efforts to unlock the efficiency of large language model inference and make these advanced AI systems more practical and accessible for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Speculative Decoding for Serving Large Language Models Using Goodput
Xiaoxuan Liu, Cade Daniel, Langxiang Hu, Woosuk Kwon, Zhuohan Li, Xiangxi Mo, Alvin Cheung, Zhijie Deng, Ion Stoica, Hao Zhang
Reducing the inference latency of large language models (LLMs) is crucial, and speculative decoding (SD) stands out as one of the most effective techniques. Rather than letting the LLM generate all tokens directly, speculative decoding employs effective proxies to predict potential outputs, which are then verified by the LLM without compromising the generation quality. Yet, deploying SD in real online LLM serving systems (with continuous batching) does not always yield improvement -- under higher request rates or low speculation accuracy, it paradoxically increases latency. Furthermore, there is no best speculation length work for all workloads under different system loads. Based on the observations, we develop a dynamic framework SmartSpec. SmartSpec dynamically determines the best speculation length for each request (from 0, i.e., no speculation, to many tokens) -- hence the associated speculative execution costs -- based on a new metric called goodput, which characterizes the current observed load of the entire system and the speculation accuracy. We show that SmartSpec consistently reduces average request latency by up to 3.2x compared to non-speculative decoding baselines across different sizes of target models, draft models, request rates, and datasets. Moreover, SmartSpec can be applied to different styles of speculative decoding, including traditional, model-based approaches as well as model-free methods like prompt lookup and tree-style decoding.
Read more6/27/2024
👀
0
Accelerating Speculative Decoding using Dynamic Speculation Length
Jonathan Mamou, Oren Pereg, Daniel Korat, Moshe Berchansky, Nadav Timor, Moshe Wasserblat, Roy Schwartz
Speculative decoding is commonly used for reducing the inference latency of large language models. Its effectiveness depends highly on the speculation lookahead (SL)-the number of tokens generated by the draft model at each iteration. In this work we show that the common practice of using the same SL for all iterations (static SL) is suboptimal. We introduce DISCO (DynamIc SpeCulation lookahead Optimization), a novel method for dynamically selecting the SL. Our experiments with four datasets show that DISCO reaches an average speedup of 10% compared to the best static SL baseline, while generating the exact same text.
Read more6/26/2024
0
Decoding Speculative Decoding
Minghao Yan, Saurabh Agarwal, Shivaram Venkataraman
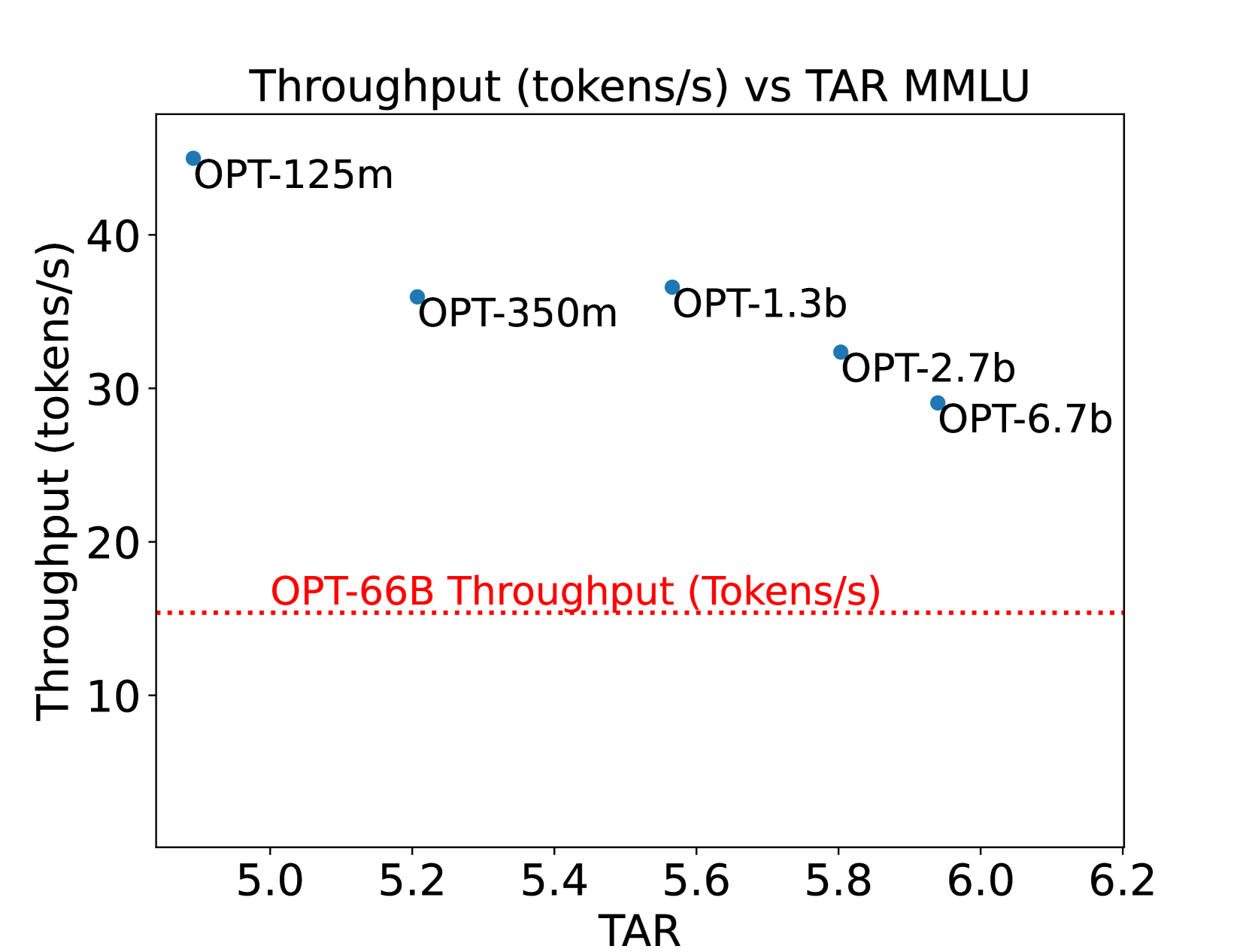
Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without sacrificing quality. When performing inference, speculative decoding uses a smaller draft model to generate speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. In this work, we perform a detailed study comprising over 350 experiments with LLaMA-65B and OPT-66B using speculative decoding and delineate the factors that affect the performance gain provided by speculative decoding. Our experiments indicate that the performance of speculative decoding depends heavily on the latency of the draft model, and the draft model's capability in language modeling does not correlate strongly with its performance in speculative decoding. Based on these insights we explore a new design space for draft models and design hardware-efficient draft models for speculative decoding. Our newly designed draft model for LLaMA-65B can provide 111% higher throughput than existing draft models and can generalize further to the LLaMA-2 model family and supervised fine-tuned models.
Read more8/13/2024

0
MagicDec: Breaking the Latency-Throughput Tradeoff for Long Context Generation with Speculative Decoding
Jian Chen, Vashisth Tiwari, Ranajoy Sadhukhan, Zhuoming Chen, Jinyuan Shi, Ian En-Hsu Yen, Beidi Chen
Large Language Models (LLMs) have become more prevalent in long-context applications such as interactive chatbots, document analysis, and agent workflows, but it is challenging to serve long-context requests with low latency and high throughput. Speculative decoding (SD) is a widely used technique to reduce latency without sacrificing performance but the conventional wisdom suggests that its efficacy is limited to small batch sizes. In MagicDec, we show that surprisingly SD can achieve speedup even for a high throughput inference regime for moderate to long sequences. More interestingly, an intelligent drafting strategy can achieve better speedup with increasing batch size based on our rigorous analysis. MagicDec first identifies the bottleneck shifts with increasing batch size and sequence length, and uses these insights to deploy speculative decoding more effectively for high throughput inference. Then, it leverages draft models with sparse KV cache to address the KV bottleneck that scales with both sequence length and batch size. This finding underscores the broad applicability of speculative decoding in long-context serving, as it can enhance throughput and reduce latency without compromising accuracy. For moderate to long sequences, we demonstrate up to 2x speedup for LLaMA-2-7B-32K and 1.84x speedup for LLaMA-3.1-8B when serving batch sizes ranging from 32 to 256 on 8 NVIDIA A100 GPUs. The code is available at https://github.com/Infini-AI-Lab/MagicDec/.
Read more8/26/2024