MAIRA-2: Grounded Radiology Report Generation

0

Sign in to get full access
Overview
- This paper presents MAIRA-2, a new model for generating grounded radiology reports from medical images and clinical data.
- MAIRA-2 builds on the previous MAIRA-1 model by incorporating additional modalities and improving the model's ability to ground the generated reports in the input data.
- The paper compares MAIRA-2 to other state-of-the-art radiology report generation models and demonstrates its superior performance on several evaluation metrics.
Plain English Explanation
The paper describes a new artificial intelligence (AI) model called MAIRA-2 that can automatically generate detailed medical reports based on radiology images and patient data. This model builds upon an earlier version called MAIRA-1, which was also developed for this task.
The key idea behind MAIRA-2 is to create a more comprehensive and accurate system for generating radiology reports. It does this by incorporating additional types of data, such as clinical information about the patient, and improving the way the model ties the generated text back to the original image and other inputs.
By evaluating MAIRA-2 against other leading models in this area, the researchers show that their approach outperforms the competition on various metrics that measure the quality and accuracy of the generated reports. This suggests MAIRA-2 could be a valuable tool for radiologists and other medical professionals to help streamline the report writing process and ensure the reports are well-grounded in the relevant data.
Technical Explanation
The paper introduces MAIRA-2, a new model for generating grounded radiology reports from medical images and associated clinical data. MAIRA-2 builds upon the previous MAIRA-1 model by incorporating additional modalities and improving the model's ability to ground the generated reports in the input data.
The authors evaluate MAIRA-2 against other state-of-the-art radiology report generation models on several datasets and metrics. They demonstrate that MAIRA-2 outperforms the competition, suggesting it could be a valuable tool for radiologists and other medical professionals.
The key technical aspects of the MAIRA-2 model include:
- Multimodal Input: MAIRA-2 takes in both radiology images and associated clinical data as input, allowing it to generate more comprehensive reports.
- Grounding Mechanism: The model incorporates a grounding mechanism that explicitly ties the generated text back to the relevant parts of the input data, improving the coherence and accuracy of the reports.
- Architecture: MAIRA-2 uses a transformer-based architecture, which has been shown to be effective for deep learning-based radiology report generation tasks.
Critical Analysis
The paper provides a thorough evaluation of MAIRA-2 and demonstrates its superiority over other state-of-the-art models. However, the authors acknowledge several limitations and areas for further research:
- Dataset Bias: The model was trained and evaluated on datasets that may not fully represent the diversity of real-world radiology cases. This could lead to biases in the generated reports.
- Lack of Clinical Validation: While the authors show MAIRA-2 outperforms other models on various metrics, they do not provide any clinical validation to ensure the reports are actually useful and accurate from a medical perspective.
- Interpretability: As with many deep learning models, the inner workings of MAIRA-2 are not fully interpretable, which could make it difficult for medical professionals to understand and trust the model's decisions.
Additionally, the paper does not address the potential challenges of deploying an automated radiology report generation system in a real-world clinical setting, such as data privacy concerns, integration with existing workflows, and the need for ongoing monitoring and maintenance.
Conclusion
The MAIRA-2 model presented in this paper represents a significant advancement in the field of deep learning-based radiology report generation. By incorporating additional modalities and improving the grounding of the generated reports, MAIRA-2 has demonstrated superior performance compared to other state-of-the-art models.
If the model's limitations can be addressed, MAIRA-2 could become a valuable tool for radiologists and other medical professionals, helping to streamline the report writing process and ensure the reports are accurate and well-grounded in the relevant data. However, further clinical validation and research on the real-world deployment of such systems will be crucial to fully realize the potential benefits of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MAIRA-2: Grounded Radiology Report Generation
Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Anton Schwaighofer, Anja Thieme, Sam Bond-Taylor, Maximilian Ilse, Fernando P'erez-Garc'ia, Valentina Salvatelli, Harshita Sharma, Felix Meissen, Mercy Ranjit, Shaury Srivastav, Julia Gong, Noel C. F. Codella, Fabian Falck, Ozan Oktay, Matthew P. Lungren, Maria Teodora Wetscherek, Javier Alvarez-Valle, Stephanie L. Hyland
Radiology reporting is a complex task requiring detailed medical image understanding and precise language generation, for which generative multimodal models offer a promising solution. However, to impact clinical practice, models must achieve a high level of both verifiable performance and utility. We augment the utility of automated report generation by incorporating localisation of individual findings on the image - a task we call grounded report generation - and enhance performance by incorporating realistic reporting context as inputs. We design a novel evaluation framework (RadFact) leveraging the logical inference capabilities of large language models (LLMs) to quantify report correctness and completeness at the level of individual sentences, while supporting the new task of grounded reporting. We develop MAIRA-2, a large radiology-specific multimodal model designed to generate chest X-ray reports with and without grounding. MAIRA-2 achieves state of the art on existing report generation benchmarks and establishes the novel task of grounded report generation.
Read more9/23/2024

0
MAIRA-1: A specialised large multimodal model for radiology report generation
Stephanie L. Hyland, Shruthi Bannur, Kenza Bouzid, Daniel C. Castro, Mercy Ranjit, Anton Schwaighofer, Fernando P'erez-Garc'ia, Valentina Salvatelli, Shaury Srivastav, Anja Thieme, Noel Codella, Matthew P. Lungren, Maria Teodora Wetscherek, Ozan Oktay, Javier Alvarez-Valle
We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.
Read more4/29/2024
0
MedRG: Medical Report Grounding with Multi-modal Large Language Model
Ke Zou, Yang Bai, Zhihao Chen, Yang Zhou, Yidi Chen, Kai Ren, Meng Wang, Xuedong Yuan, Xiaojing Shen, Huazhu Fu
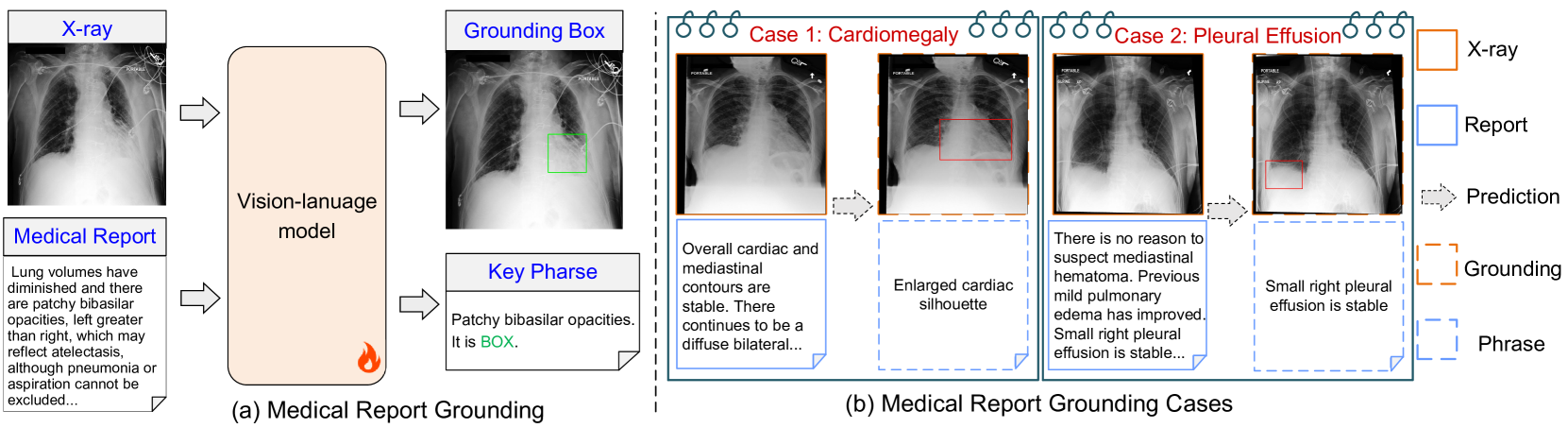
Medical Report Grounding is pivotal in identifying the most relevant regions in medical images based on a given phrase query, a critical aspect in medical image analysis and radiological diagnosis. However, prevailing visual grounding approaches necessitate the manual extraction of key phrases from medical reports, imposing substantial burdens on both system efficiency and physicians. In this paper, we introduce a novel framework, Medical Report Grounding (MedRG), an end-to-end solution for utilizing a multi-modal Large Language Model to predict key phrase by incorporating a unique token, BOX, into the vocabulary to serve as an embedding for unlocking detection capabilities. Subsequently, the vision encoder-decoder jointly decodes the hidden embedding and the input medical image, generating the corresponding grounding box. The experimental results validate the effectiveness of MedRG, surpassing the performance of the existing state-of-the-art medical phrase grounding methods. This study represents a pioneering exploration of the medical report grounding task, marking the first-ever endeavor in this domain.
Read more4/11/2024

0
Fact-Aware Multimodal Retrieval Augmentation for Accurate Medical Radiology Report Generation
Liwen Sun, James Zhao, Megan Han, Chenyan Xiong
Multimodal foundation models hold significant potential for automating radiology report generation, thereby assisting clinicians in diagnosing cardiac diseases. However, generated reports often suffer from serious factual inaccuracy. In this paper, we introduce a fact-aware multimodal retrieval-augmented pipeline in generating accurate radiology reports (FactMM-RAG). We first leverage RadGraph to mine factual report pairs, then integrate factual knowledge to train a universal multimodal retriever. Given a radiology image, our retriever can identify high-quality reference reports to augment multimodal foundation models, thus enhancing the factual completeness and correctness of report generation. Experiments on two benchmark datasets show that our multimodal retriever outperforms state-of-the-art retrievers on both language generation and radiology-specific metrics, up to 6.5% and 2% score in F1CheXbert and F1RadGraph. Further analysis indicates that employing our factually-informed training strategy imposes an effective supervision signal, without relying on explicit diagnostic label guidance, and successfully propagates fact-aware capabilities from the multimodal retriever to the multimodal foundation model in radiology report generation.
Read more7/23/2024