Make the Most of Your Data: Changing the Training Data Distribution to Improve In-distribution Generalization Performance
2404.17768
0
0

Abstract
Can we modify the training data distribution to encourage the underlying optimization method toward finding solutions with superior generalization performance on in-distribution data? In this work, we approach this question for the first time by comparing the inductive bias of gradient descent (GD) with that of sharpness-aware minimization (SAM). By studying a two-layer CNN, we prove that SAM learns easy and difficult features more uniformly, particularly in early epochs. That is, SAM is less susceptible to simplicity bias compared to GD. Based on this observation, we propose USEFUL, an algorithm that clusters examples based on the network output early in training and upsamples examples with no easy features to alleviate the pitfalls of the simplicity bias. We show empirically that modifying the training data distribution in this way effectively improves the generalization performance on the original data distribution when training with (S)GD by mimicking the training dynamics of SAM. Notably, we demonstrate that our method can be combined with SAM and existing data augmentation strategies to achieve, to the best of our knowledge, state-of-the-art performance for training ResNet18 on CIFAR10, STL10, CINIC10, Tiny-ImageNet; ResNet34 on CIFAR100; and VGG19 and DenseNet121 on CIFAR10.
Create account to get full access
Overview
- This paper investigates how changing the training data distribution can improve the in-distribution generalization performance of machine learning models.
- The authors explore techniques to modify the training data distribution, such as increasing fairness in classification for out-of-distribution data, addressing biases in ImageNet models, and improving generalization in segmentation foundation models.
- The paper aims to provide insights into how manipulating the training data distribution can lead to better in-distribution performance, in contrast to issues with mixture data training and generalization challenges in diffusion models.
Plain English Explanation
Machine learning models are trained on a set of data, called the training data. The distribution, or spread, of this training data can have a big impact on how well the model performs on new, unseen data that it wasn't trained on.
This paper explores ways to modify the training data distribution to improve the model's performance on data that is similar to the training data, known as in-distribution generalization. The authors look at techniques like increasing fairness in classification for out-of-distribution data, addressing biases in ImageNet models, and improving generalization in segmentation foundation models.
The key insight is that the way the training data is distributed, or spread out, can significantly impact how well the model performs on new, similar data. This is in contrast to issues that can arise when using a mixture of data types for training or the generalization challenges faced by diffusion models.
By carefully manipulating the training data distribution, the researchers aim to help machine learning practitioners get the most out of their available data and build models that generalize better to new, in-distribution examples.
Technical Explanation
The paper explores various techniques to modify the training data distribution in order to improve the in-distribution generalization performance of machine learning models. The authors investigate methods such as increasing fairness in classification for out-of-distribution data, addressing biases in ImageNet models, and improving generalization in segmentation foundation models.
The key insight is that the distribution, or spread, of the training data can have a significant impact on the model's performance on new, similar data. This is in contrast to issues that can arise when using a mixture of data types for training or the generalization challenges faced by diffusion models.
Through careful manipulation of the training data distribution, the researchers aim to help machine learning practitioners extract the maximum performance from their available data and build models that generalize better to new, in-distribution examples.
Critical Analysis
The paper provides a thorough exploration of how manipulating the training data distribution can improve in-distribution generalization performance. However, the authors acknowledge that their techniques may not be universally applicable and that there are potential limitations to their approach.
For example, the paper does not address how these techniques might perform on out-of-distribution data, which is also an important consideration for real-world machine learning applications. Additionally, the authors note that their methods may be computationally intensive or require significant domain expertise to implement effectively.
Further research could explore the trade-offs between in-distribution and out-of-distribution performance, as well as investigate more efficient or automated ways to adjust the training data distribution. It would also be valuable to see the proposed techniques applied and evaluated across a wider range of machine learning tasks and datasets.
Overall, the paper makes a compelling case for the importance of carefully considering the training data distribution and provides a solid foundation for future work in this area.
Conclusion
This paper highlights the significant impact that the training data distribution can have on the in-distribution generalization performance of machine learning models. By exploring techniques to manipulate the training data distribution, the authors demonstrate the potential to improve model performance on new, similar data.
The insights and methods presented in this paper could be valuable for machine learning practitioners who are looking to get the most out of their available data and build models that generalize well to real-world scenarios. While the approach may have some limitations, the paper provides a solid foundation for further research and development in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning
Jacob Mitchell Springer, Vaishnavh Nagarajan, Aditi Raghunathan
0
0
Sharpness-Aware Minimization (SAM) has emerged as a promising alternative optimizer to stochastic gradient descent (SGD). The originally-proposed motivation behind SAM was to bias neural networks towards flatter minima that are believed to generalize better. However, recent studies have shown conflicting evidence on the relationship between flatness and generalization, suggesting that flatness does fully explain SAM's success. Sidestepping this debate, we identify an orthogonal effect of SAM that is beneficial out-of-distribution: we argue that SAM implicitly balances the quality of diverse features. SAM achieves this effect by adaptively suppressing well-learned features which gives remaining features opportunity to be learned. We show that this mechanism is beneficial in datasets that contain redundant or spurious features where SGD falls for the simplicity bias and would not otherwise learn all available features. Our insights are supported by experiments on real data: we demonstrate that SAM improves the quality of features in datasets containing redundant or spurious features, including CelebA, Waterbirds, CIFAR-MNIST, and DomainBed.
6/3/2024
🏷️
Increasing Fairness in Classification of Out of Distribution Data for Facial Recognition
Gianluca Barone, Aashrit Cunchala, Rudy Nunez
0
0
Standard classification theory assumes that the distribution of images in the test and training sets are identical. Unfortunately, real-life scenarios typically feature unseen data (out-of-distribution data) which is different from data in the training distribution(in-distribution). This issue is most prevalent in social justice problems where data from under-represented groups may appear in the test data without representing an equal proportion of the training data. This may result in a model returning confidently wrong decisions and predictions. We are interested in the following question: Can the performance of a neural network improve on facial images of out-of-distribution data when it is trained simultaneously on multiple datasets of in-distribution data? We approach this problem by incorporating the Outlier Exposure model and investigate how the model's performance changes when other datasets of facial images were implemented. We observe that the accuracy and other metrics of the model can be increased by applying Outlier Exposure, incorporating a trainable weight parameter to increase the machine's emphasis on outlier images, and by re-weighting the importance of different class labels. We also experimented with whether sorting the images and determining outliers via image features would have more of an effect on the metrics than sorting by average pixel value. Our goal was to make models not only more accurate but also more fair by scanning a more expanded range of images. We also tested the datasets in reverse order to see whether a more fair dataset with balanced features has an effect on the model's accuracy.
6/26/2024
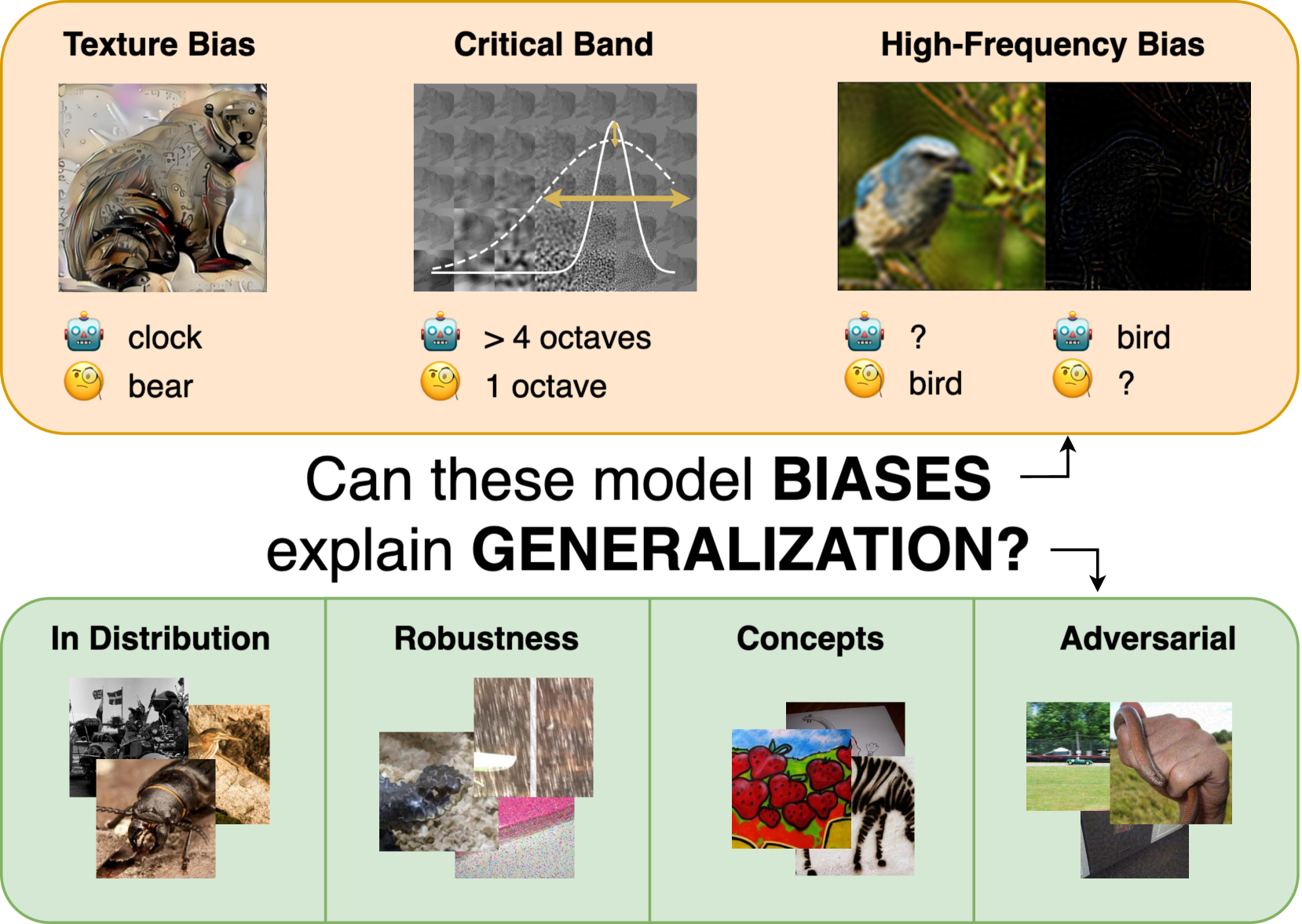
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024
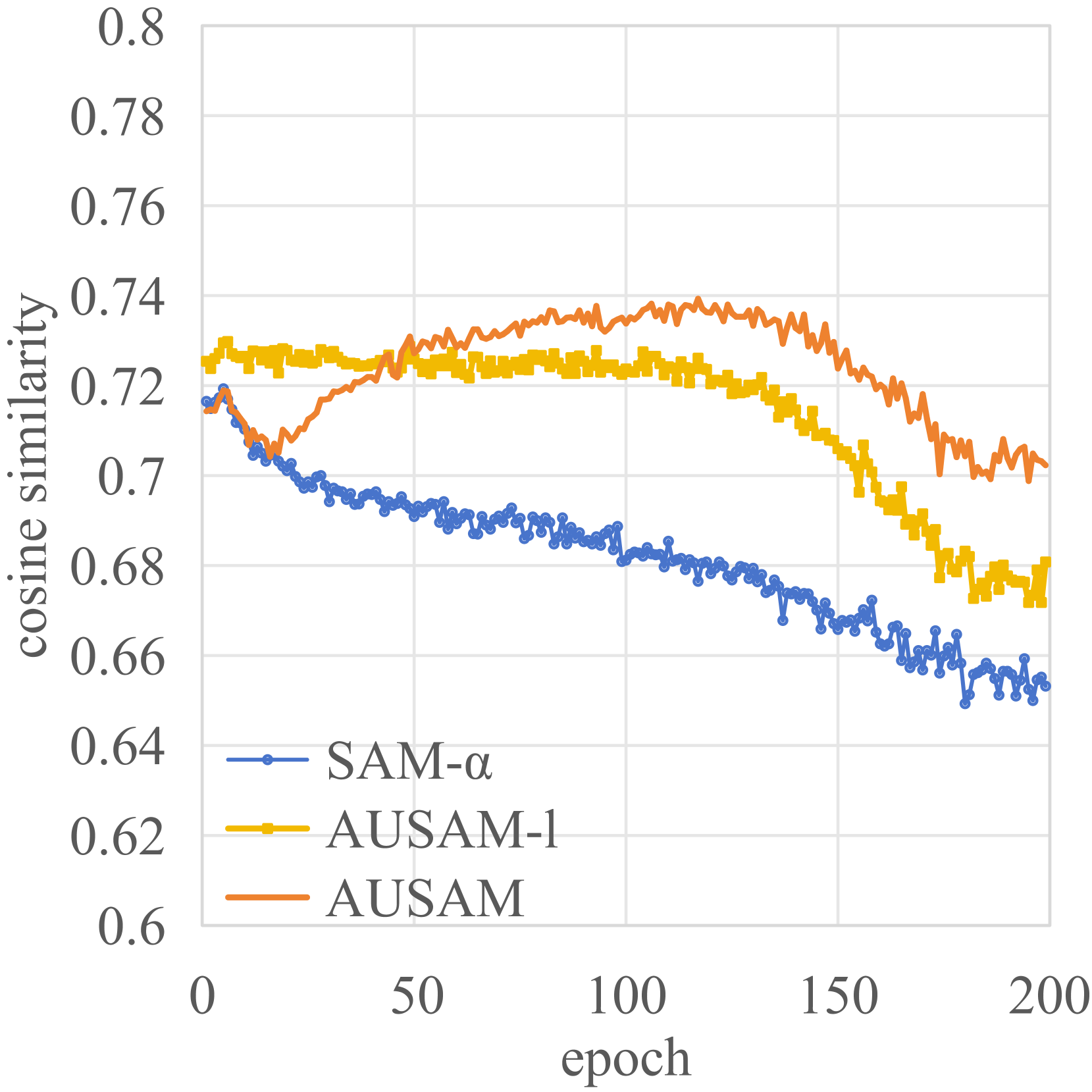
Asymptotic Unbiased Sample Sampling to Speed Up Sharpness-Aware Minimization
Jiaxin Deng, Junbiao Pang, Baochang Zhang
0
0
Sharpness-Aware Minimization (SAM) has emerged as a promising approach for effectively reducing the generalization error. However, SAM incurs twice the computational cost compared to base optimizer (e.g., SGD). We propose Asymptotic Unbiased Sampling with respect to iterations to accelerate SAM (AUSAM), which maintains the model's generalization capacity while significantly enhancing computational efficiency. Concretely, we probabilistically sample a subset of data points beneficial for SAM optimization based on a theoretically guaranteed criterion, i.e., the Gradient Norm of each Sample (GNS). We further approximate the GNS by the difference in loss values before and after perturbation in SAM. As a plug-and-play, architecture-agnostic method, our approach consistently accelerates SAM across a range of tasks and networks, i.e., classification, human pose estimation and network quantization. On CIFAR10/100 and Tiny-ImageNet, AUSAM achieves results comparable to SAM while providing a speedup of over 70%. Compared to recent dynamic data pruning methods, AUSAM is better suited for SAM and excels in maintaining performance. Additionally, AUSAM accelerates optimization in human pose estimation and model quantization without sacrificing performance, demonstrating its broad practicality.
6/13/2024