Mamba-FETrack: Frame-Event Tracking via State Space Model

0
Sign in to get full access
Overview
- This paper introduces Mamba-FETrack, a state space model for frame-event visual tracking that combines data from event cameras and traditional frame-based cameras.
- Event cameras are novel sensors that capture changes in pixel intensity over time, providing high-speed and low-latency visual information compared to standard cameras.
- The authors propose a state space model that fuses the complementary information from event and frame data to enable robust and accurate long-term visual tracking.
Plain English Explanation
The paper describes a new approach called Mamba-FETrack for doing visual object tracking using a combination of event cameras and standard frame-based cameras. Event cameras are a type of camera that are different from normal cameras - instead of capturing full images like a normal camera, they only record changes in brightness at each pixel over time. This allows them to capture information much faster and with less delay than regular cameras.
The key idea in Mamba-FETrack is to fuse the data from both the event camera and the standard camera using a state space model. This allows the system to take advantage of the complementary strengths of the two types of cameras - the high speed and low latency of the event camera, and the richer visual information from the standard camera. By combining these sources of data in a principled way, the authors show that Mamba-FETrack can enable robust and accurate long-term visual object tracking.
Technical Explanation
The paper introduces Mamba-FETrack, a novel frame-event visual tracking approach that leverages a state space model to fuse information from event cameras and standard frame-based cameras.
The authors first provide an overview of related work on event-based vision and visual tracking. They highlight the advantages of event cameras, such as their high temporal resolution and low latency, as well as the challenges in integrating them with traditional computer vision systems.
To address these challenges, the authors propose a state space model that can effectively combine event and frame data. The model consists of three key components:
- An observation model that relates the event and frame data to the underlying object state.
- A state transition model that captures the temporal dynamics of the object's motion.
- A filtering algorithm that performs recursive state estimation to track the object over time.
The authors demonstrate the effectiveness of Mamba-FETrack through extensive experiments on public benchmarks. They show that their approach outperforms state-of-the-art frame-event tracking and RGB-event object detection methods, particularly in challenging long-term tracking scenarios.
The authors also present several Mamba-based models, including FusionMamba, which demonstrate the broader applicability of their state space modeling approach to other event-based vision tasks.
Critical Analysis
The Mamba-FETrack paper makes a compelling case for the benefits of using a state space model to fuse event and frame data for visual tracking. The authors have carefully designed their model and conducted thorough experiments to validate its performance.
One potential limitation of the work is the reliance on a Kalman filter-based state estimation approach, which may not be able to handle highly nonlinear or complex object motions. The authors acknowledge this and suggest that more advanced filtering techniques, such as particle filters or deep learning-based methods, could be explored in future work.
Additionally, the paper does not provide a detailed analysis of the computational complexity and real-time performance of Mamba-FETrack. As event-based vision systems are often targeting embedded and mobile applications, these practical considerations would be important to understand the feasibility of deploying the proposed approach in real-world scenarios.
Despite these minor caveats, the Mamba-FETrack paper represents a significant contribution to the field of event-based visual tracking. The authors' innovative use of state space modeling to fuse multimodal sensor data sets a strong foundation for further research and development in this area.
Conclusion
The Mamba-FETrack paper introduces a novel state space model-based approach for fusing event and frame data to enable robust and accurate long-term visual object tracking. By leveraging the complementary strengths of event cameras and standard cameras, the authors demonstrate impressive tracking performance on public benchmarks.
The work showcases the potential of event-based vision systems and the benefits of combining different sensor modalities through principled modeling techniques. The insights and methodologies presented in this paper can inspire further advancements in event-based computer vision and have broader implications for the development of versatile, high-performance tracking systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mamba-FETrack: Frame-Event Tracking via State Space Model
Ju Huang, Shiao Wang, Shuai Wang, Zhe Wu, Xiao Wang, Bo Jiang
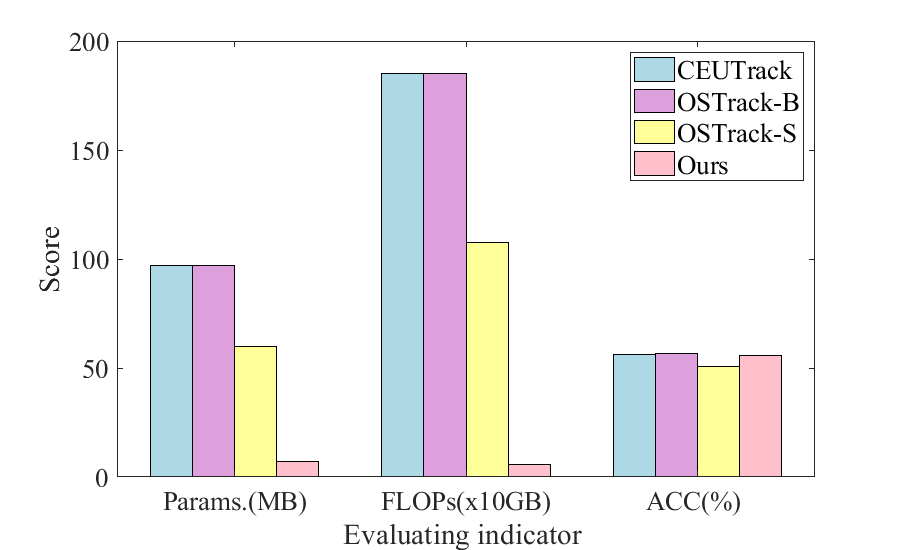
RGB-Event based tracking is an emerging research topic, focusing on how to effectively integrate heterogeneous multi-modal data (synchronized exposure video frames and asynchronous pulse Event stream). Existing works typically employ Transformer based networks to handle these modalities and achieve decent accuracy through input-level or feature-level fusion on multiple datasets. However, these trackers require significant memory consumption and computational complexity due to the use of self-attention mechanism. This paper proposes a novel RGB-Event tracking framework, Mamba-FETrack, based on the State Space Model (SSM) to achieve high-performance tracking while effectively reducing computational costs and realizing more efficient tracking. Specifically, we adopt two modality-specific Mamba backbone networks to extract the features of RGB frames and Event streams. Then, we also propose to boost the interactive learning between the RGB and Event features using the Mamba network. The fused features will be fed into the tracking head for target object localization. Extensive experiments on FELT and FE108 datasets fully validated the efficiency and effectiveness of our proposed tracker. Specifically, our Mamba-based tracker achieves 43.5/55.6 on the SR/PR metric, while the ViT-S based tracker (OSTrack) obtains 40.0/50.9. The GPU memory cost of ours and ViT-S based tracker is 13.98GB and 15.44GB, which decreased about $9.5%$. The FLOPs and parameters of ours/ViT-S based OSTrack are 59GB/1076GB and 7MB/60MB, which decreased about $94.5%$ and $88.3%$, respectively. We hope this work can bring some new insights to the tracking field and greatly promote the application of the Mamba architecture in tracking. The source code of this work will be released on url{https://github.com/Event-AHU/Mamba_FETrack}.
Read more4/30/2024

0
MambaEVT: Event Stream based Visual Object Tracking using State Space Model
Xiao Wang, Chao wang, Shiao Wang, Xixi Wang, Zhicheng Zhao, Lin Zhu, Bo Jiang
Event camera-based visual tracking has drawn more and more attention in recent years due to the unique imaging principle and advantages of low energy consumption, high dynamic range, and dense temporal resolution. Current event-based tracking algorithms are gradually hitting their performance bottlenecks, due to the utilization of vision Transformer and the static template for target object localization. In this paper, we propose a novel Mamba-based visual tracking framework that adopts the state space model with linear complexity as a backbone network. The search regions and target template are fed into the vision Mamba network for simultaneous feature extraction and interaction. The output tokens of search regions will be fed into the tracking head for target localization. More importantly, we consider introducing a dynamic template update strategy into the tracking framework using the Memory Mamba network. By considering the diversity of samples in the target template library and making appropriate adjustments to the template memory module, a more effective dynamic template can be integrated. The effective combination of dynamic and static templates allows our Mamba-based tracking algorithm to achieve a good balance between accuracy and computational cost on multiple large-scale datasets, including EventVOT, VisEvent, and FE240hz. The source code will be released on https://github.com/Event-AHU/MambaEVT
Read more8/21/2024

0
MambaVT: Spatio-Temporal Contextual Modeling for robust RGB-T Tracking
Simiao Lai, Chang Liu, Jiawen Zhu, Ben Kang, Yang Liu, Dong Wang, Huchuan Lu
Existing RGB-T tracking algorithms have made remarkable progress by leveraging the global interaction capability and extensive pre-trained models of the Transformer architecture. Nonetheless, these methods mainly adopt imagepair appearance matching and face challenges of the intrinsic high quadratic complexity of the attention mechanism, resulting in constrained exploitation of temporal information. Inspired by the recently emerged State Space Model Mamba, renowned for its impressive long sequence modeling capabilities and linear computational complexity, this work innovatively proposes a pure Mamba-based framework (MambaVT) to fully exploit spatio-temporal contextual modeling for robust visible-thermal tracking. Specifically, we devise the long-range cross-frame integration component to globally adapt to target appearance variations, and introduce short-term historical trajectory prompts to predict the subsequent target states based on local temporal location clues. Extensive experiments show the significant potential of vision Mamba for RGB-T tracking, with MambaVT achieving state-of-the-art performance on four mainstream benchmarks while requiring lower computational costs. We aim for this work to serve as a simple yet strong baseline, stimulating future research in this field. The code and pre-trained models will be made available.
Read more8/16/2024
0
Long-term Frame-Event Visual Tracking: Benchmark Dataset and Baseline
Xiao Wang, Ju Huang, Shiao Wang, Chuanming Tang, Bo Jiang, Yonghong Tian, Jin Tang, Bin Luo
Current event-/frame-event based trackers undergo evaluation on short-term tracking datasets, however, the tracking of real-world scenarios involves long-term tracking, and the performance of existing tracking algorithms in these scenarios remains unclear. In this paper, we first propose a new long-term and large-scale frame-event single object tracking dataset, termed FELT. It contains 742 videos and 1,594,474 RGB frames and event stream pairs and has become the largest frame-event tracking dataset to date. We re-train and evaluate 15 baseline trackers on our dataset for future works to compare. More importantly, we find that the RGB frames and event streams are naturally incomplete due to the influence of challenging factors and spatially sparse event flow. In response to this, we propose a novel associative memory Transformer network as a unified backbone by introducing modern Hopfield layers into multi-head self-attention blocks to fuse both RGB and event data. Extensive experiments on RGB-Event (FELT), RGB-Thermal (RGBT234, LasHeR), and RGB-Depth (DepthTrack) datasets fully validated the effectiveness of our model. The dataset and source code can be found at url{https://github.com/Event-AHU/FELT_SOT_Benchmark}.
Read more4/4/2024