MambaPupil: Bidirectional Selective Recurrent model for Event-based Eye tracking

0
Sign in to get full access
Overview
- This paper introduces MambaPupil, a novel bidirectional selective recurrent model for event-based eye tracking.
- The model aims to accurately predict eye gaze from event-based vision sensors, which capture visual information as a stream of discrete events rather than frame-based images.
- MambaPupil combines a selective attention mechanism with a bidirectional recurrent neural network to efficiently process the event-based data.
Plain English Explanation
Event-based vision sensors, like the human eye, capture visual information as a series of discrete events rather than traditional frame-based images. This presents unique challenges for eye tracking, as the data is inherently time-series and sparse.
The MambaPupil model tackles this problem by using a bidirectional recurrent neural network to process the event data. The bidirectional nature allows the model to consider both past and future events when predicting eye gaze, which is important for accurately tracking rapid eye movements.
Additionally, MambaPupil incorporates a selective attention mechanism that focuses the model's processing on the most relevant events. This helps it efficiently extract the key information needed for gaze estimation, rather than getting bogged down in irrelevant details.
The core innovation of this work is adapting deep learning techniques originally designed for frame-based images to the event-based domain. By doing so, the authors demonstrate the potential of event-based eye tracking to provide high-speed, power-efficient gaze estimation.
Technical Explanation
The MambaPupil model uses a bidirectional selective recurrent neural network to process event-based visual data for eye tracking. The bidirectional nature allows it to consider both past and future events when predicting gaze, while the selective attention mechanism focuses the model's processing on the most relevant information.
Specifically, MambaPupil takes in a sequence of events from an event-based vision sensor. Each event is characterized by its location, time, and polarity (indicating whether the pixel brightness increased or decreased). The model then uses a series of recurrent layers to encode the temporal dynamics of the event stream.
Crucially, MambaPupil incorporates a selective attention module that identifies which events are most important for estimating the current gaze position. This allows the model to efficiently process the sparse, event-based data without getting distracted by irrelevant information.
The output of the attention-weighted recurrent layers is then passed through additional fully-connected layers to produce the final gaze prediction. The model is trained end-to-end on datasets of event-based eye tracking data, using a loss function that penalizes errors in the estimated gaze position.
Critical Analysis
The MambaPupil paper makes a compelling case for the use of event-based vision and recurrent neural networks in eye tracking applications. By adapting deep learning techniques to the event-based domain, the authors demonstrate the potential for high-speed, power-efficient gaze estimation.
That said, the paper does not extensively explore the limitations of the approach. For example, the model's performance on different types of eye movements (e.g. saccades vs. smooth pursuit) is not discussed. Additionally, the robustness of the selective attention mechanism to noisy or incomplete event data is not evaluated.
Further research would be needed to fully understand the strengths and weaknesses of the MambaPupil model, especially in comparison to other event-based eye tracking approaches and traditional frame-based methods. Potential future work could also explore ways to make the model more interpretable, allowing for better understanding of the key factors driving its gaze predictions.
Overall, the MambaPupil paper represents an important step forward in event-based vision and deep learning for eye tracking applications. While additional research is needed, the authors have demonstrated the promise of this approach and opened up new avenues for exploration in this field.
Conclusion
The MambaPupil paper introduces a novel bidirectional selective recurrent model for event-based eye tracking. By adapting deep learning techniques to the event-based domain, the authors show the potential for high-speed, power-efficient gaze estimation using sparse visual data.
The key innovations of the MambaPupil model are its use of a bidirectional recurrent architecture to capture temporal dynamics, and a selective attention mechanism to focus processing on the most relevant events. These techniques allow the model to accurately predict eye gaze from event-based vision sensors, which could have important applications in areas like human-computer interaction, virtual/augmented reality, and cognitive neuroscience.
While further research is needed to fully understand the strengths and limitations of this approach, the MambaPupil paper represents an important step forward in the field of event-based vision and deep learning for eye tracking. The authors have opened up new avenues for exploration that could lead to significant advancements in this rapidly evolving area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MambaPupil: Bidirectional Selective Recurrent model for Event-based Eye tracking
Zhong Wang, Zengyu Wan, Han Han, Bohao Liao, Yuliang Wu, Wei Zhai, Yang Cao, Zheng-jun Zha
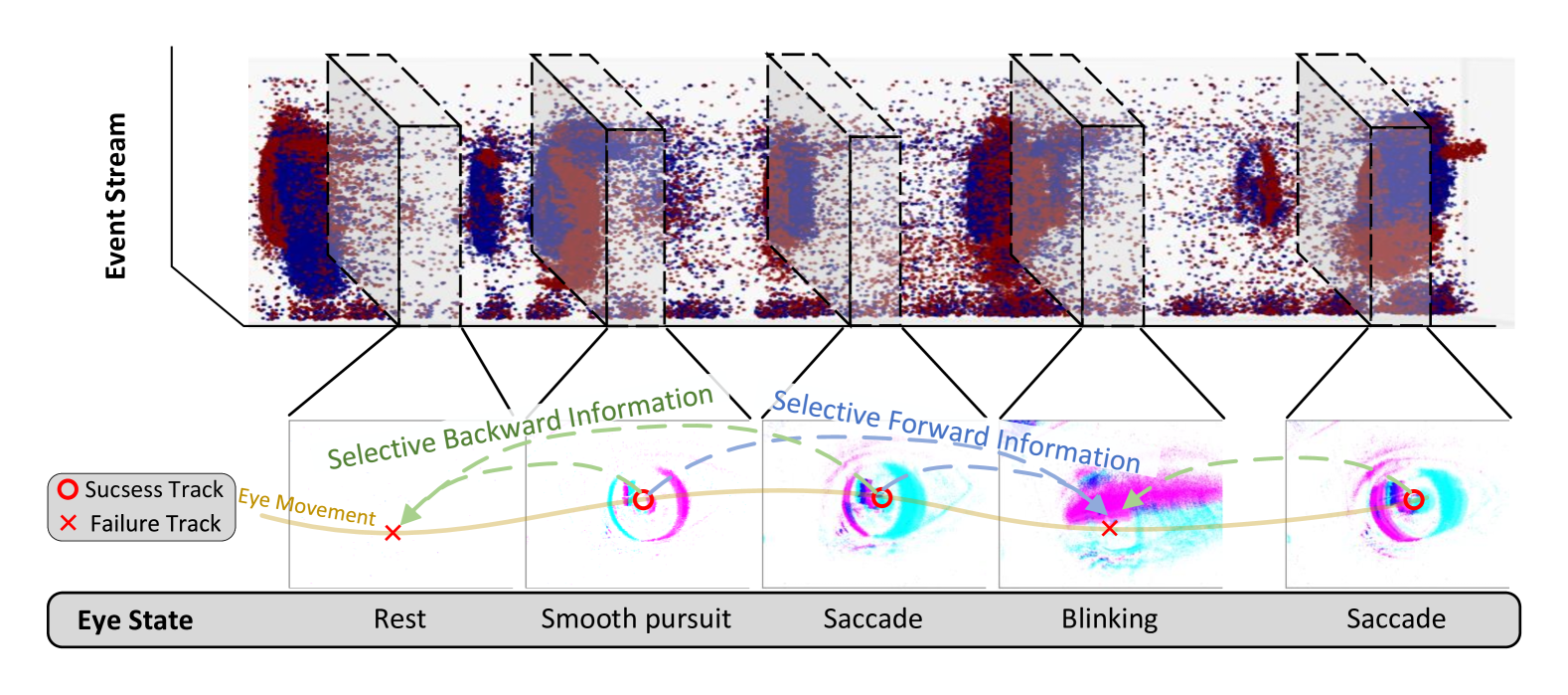
Event-based eye tracking has shown great promise with the high temporal resolution and low redundancy provided by the event camera. However, the diversity and abruptness of eye movement patterns, including blinking, fixating, saccades, and smooth pursuit, pose significant challenges for eye localization. To achieve a stable event-based eye-tracking system, this paper proposes a bidirectional long-term sequence modeling and time-varying state selection mechanism to fully utilize contextual temporal information in response to the variability of eye movements. Specifically, the MambaPupil network is proposed, which consists of the multi-layer convolutional encoder to extract features from the event representations, a bidirectional Gated Recurrent Unit (GRU), and a Linear Time-Varying State Space Module (LTV-SSM), to selectively capture contextual correlation from the forward and backward temporal relationship. Furthermore, the Bina-rep is utilized as a compact event representation, and the tailor-made data augmentation, called as Event-Cutout, is proposed to enhance the model's robustness by applying spatial random masking to the event image. The evaluation on the ThreeET-plus benchmark shows the superior performance of the MambaPupil, which secured the 1st place in CVPR'2024 AIS Event-based Eye Tracking challenge.
Read more5/1/2024

0
MambaEVT: Event Stream based Visual Object Tracking using State Space Model
Xiao Wang, Chao wang, Shiao Wang, Xixi Wang, Zhicheng Zhao, Lin Zhu, Bo Jiang
Event camera-based visual tracking has drawn more and more attention in recent years due to the unique imaging principle and advantages of low energy consumption, high dynamic range, and dense temporal resolution. Current event-based tracking algorithms are gradually hitting their performance bottlenecks, due to the utilization of vision Transformer and the static template for target object localization. In this paper, we propose a novel Mamba-based visual tracking framework that adopts the state space model with linear complexity as a backbone network. The search regions and target template are fed into the vision Mamba network for simultaneous feature extraction and interaction. The output tokens of search regions will be fed into the tracking head for target localization. More importantly, we consider introducing a dynamic template update strategy into the tracking framework using the Memory Mamba network. By considering the diversity of samples in the target template library and making appropriate adjustments to the template memory module, a more effective dynamic template can be integrated. The effective combination of dynamic and static templates allows our Mamba-based tracking algorithm to achieve a good balance between accuracy and computational cost on multiple large-scale datasets, including EventVOT, VisEvent, and FE240hz. The source code will be released on https://github.com/Event-AHU/MambaEVT
Read more8/21/2024
0
Mamba-FETrack: Frame-Event Tracking via State Space Model
Ju Huang, Shiao Wang, Shuai Wang, Zhe Wu, Xiao Wang, Bo Jiang
RGB-Event based tracking is an emerging research topic, focusing on how to effectively integrate heterogeneous multi-modal data (synchronized exposure video frames and asynchronous pulse Event stream). Existing works typically employ Transformer based networks to handle these modalities and achieve decent accuracy through input-level or feature-level fusion on multiple datasets. However, these trackers require significant memory consumption and computational complexity due to the use of self-attention mechanism. This paper proposes a novel RGB-Event tracking framework, Mamba-FETrack, based on the State Space Model (SSM) to achieve high-performance tracking while effectively reducing computational costs and realizing more efficient tracking. Specifically, we adopt two modality-specific Mamba backbone networks to extract the features of RGB frames and Event streams. Then, we also propose to boost the interactive learning between the RGB and Event features using the Mamba network. The fused features will be fed into the tracking head for target object localization. Extensive experiments on FELT and FE108 datasets fully validated the efficiency and effectiveness of our proposed tracker. Specifically, our Mamba-based tracker achieves 43.5/55.6 on the SR/PR metric, while the ViT-S based tracker (OSTrack) obtains 40.0/50.9. The GPU memory cost of ours and ViT-S based tracker is 13.98GB and 15.44GB, which decreased about $9.5%$. The FLOPs and parameters of ours/ViT-S based OSTrack are 59GB/1076GB and 7MB/60MB, which decreased about $94.5%$ and $88.3%$, respectively. We hope this work can bring some new insights to the tracking field and greatly promote the application of the Mamba architecture in tracking. The source code of this work will be released on url{https://github.com/Event-AHU/Mamba_FETrack}.
Read more4/30/2024

0
Co-designing a Sub-millisecond Latency Event-based Eye Tracking System with Submanifold Sparse CNN
Baoheng Zhang, Yizhao Gao, Jingyuan Li, Hayden Kwok-Hay So
Eye-tracking technology is integral to numerous consumer electronics applications, particularly in the realm of virtual and augmented reality (VR/AR). These applications demand solutions that excel in three crucial aspects: low-latency, low-power consumption, and precision. Yet, achieving optimal performance across all these fronts presents a formidable challenge, necessitating a balance between sophisticated algorithms and efficient backend hardware implementations. In this study, we tackle this challenge through a synergistic software/hardware co-design of the system with an event camera. Leveraging the inherent sparsity of event-based input data, we integrate a novel sparse FPGA dataflow accelerator customized for submanifold sparse convolution neural networks (SCNN). The SCNN implemented on the accelerator can efficiently extract the embedding feature vector from each representation of event slices by only processing the non-zero activations. Subsequently, these vectors undergo further processing by a gated recurrent unit (GRU) and a fully connected layer on the host CPU to generate the eye centers. Deployment and evaluation of our system reveal outstanding performance metrics. On the Event-based Eye-Tracking-AIS2024 dataset, our system achieves 81% p5 accuracy, 99.5% p10 accuracy, and 3.71 Mean Euclidean Distance with 0.7 ms latency while only consuming 2.29 mJ per inference. Notably, our solution opens up opportunities for future eye-tracking systems. Code is available at https://github.com/CASR-HKU/ESDA/tree/eye_tracking.
Read more4/23/2024