An Investigation of Incorporating Mamba for Speech Enhancement
2405.06573
0
0
🗣️
Abstract
This work aims to study a scalable state-space model (SSM), Mamba, for the speech enhancement (SE) task. We exploit a Mamba-based regression model to characterize speech signals and build an SE system upon Mamba, termed SEMamba. We explore the properties of Mamba by integrating it as the core model in both basic and advanced SE systems, along with utilizing signal-level distances as well as metric-oriented loss functions. SEMamba demonstrates promising results and attains a PESQ score of 3.55 on the VoiceBank-DEMAND dataset. When combined with the perceptual contrast stretching technique, the proposed SEMamba yields a new state-of-the-art PESQ score of 3.69.
Create account to get full access
Overview
- This paper explores a scalable state-space model (SSM) called Mamba for speech enhancement (SE) tasks.
- The researchers develop an SE system called SEMamba that uses a Mamba-based regression model to characterize speech signals.
- SEMamba demonstrates promising results, achieving a PESQ score of 3.55 on the VoiceBank-DEMAND dataset.
- When combined with the perceptual contrast stretching technique, SEMamba achieves a new state-of-the-art PESQ score of 3.69.
Plain English Explanation
The researchers in this paper have developed a new way to improve the quality of recorded speech. They use a machine learning model called Mamba, which is a type of state-space model. State-space models are good at representing complex, dynamic systems like speech.
The researchers built an entire speech enhancement system called SEMamba around the Mamba model. SEMamba takes in noisy speech recordings and tries to remove the background noise, making the speech sound clearer and more natural.
When tested on a standard speech dataset, SEMamba was able to achieve a PESQ score of 3.55. PESQ is a measure of how good the enhanced speech sounds to human listeners, with a higher score being better. The researchers also found that combining SEMamba with another technique called perceptual contrast stretching led to an even better PESQ score of 3.69, which is a new state-of-the-art result.
Overall, this research shows that the Mamba state-space model can be very effective for improving the quality of recorded speech, with potential applications in areas like voice assistants, teleconferencing, and hearing aids.
Technical Explanation
The researchers in this paper explore the use of a scalable state-space model (SSM) called Mamba for the task of speech enhancement (SE). They develop an SE system called SEMamba that uses a Mamba-based regression model to characterize the speech signals.
To assess the properties of Mamba, the researchers integrate it as the core model in both basic and advanced SE systems. They utilize signal-level distances as well as metric-oriented loss functions to train and evaluate the models.
The results show that SEMamba achieves a PESQ score of 3.55 on the VoiceBank-DEMAND dataset, which is a promising performance for an SE system. Furthermore, when SEMamba is combined with the perceptual contrast stretching technique, it yields a new state-of-the-art PESQ score of 3.69.
The researchers' use of the Mamba model allows them to effectively capture the complex and dynamic nature of speech signals, leading to the improved speech enhancement performance. The versatility of Mamba enables its integration into both basic and advanced SE systems, demonstrating its potential as a scalable and effective tool for this task.
Critical Analysis
The paper provides a thorough exploration of the Mamba state-space model for speech enhancement, and the results are promising. However, the researchers do not delve into the specific architectural details or the training process of the SEMamba system, which could be useful for replicating the work or understanding its inner workings.
Additionally, the paper does not discuss the computational complexity or efficiency of the Mamba-based approach compared to other SE models. This information would be helpful in assessing the scalability and real-world applicability of the proposed system.
Furthermore, the paper does not address potential limitations or edge cases of the SEMamba system, such as its performance on different types of background noise or its robustness to varying speech characteristics. Exploring these aspects could provide a more comprehensive understanding of the model's capabilities and limitations.
Despite these minor shortcomings, the paper presents a valuable contribution to the field of speech enhancement by demonstrating the effectiveness of the Mamba state-space model in this task. The researchers have laid the groundwork for further exploration and refinement of this approach.
Conclusion
This paper introduces a scalable state-space model called Mamba and its application to the task of speech enhancement. The researchers develop an SE system called SEMamba that uses a Mamba-based regression model to characterize speech signals, leading to promising results on the VoiceBank-DEMAND dataset.
The key takeaway from this work is that the Mamba model can be a powerful tool for speech enhancement, as it is able to effectively capture the complex and dynamic nature of speech signals. The researchers' integration of Mamba into both basic and advanced SE systems demonstrates its versatility and potential for further advancements in this field.
The state-of-the-art PESQ score achieved by SEMamba when combined with perceptual contrast stretching highlights the significant improvements in speech quality that can be attained through this approach. This research has implications for a wide range of applications, from voice assistants and teleconferencing to hearing aids, where high-quality speech is essential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Exploring the Capability of Mamba in Speech Applications
Koichi Miyazaki, Yoshiki Masuyama, Masato Murata
0
0
This paper explores the capability of Mamba, a recently proposed architecture based on state space models (SSMs), as a competitive alternative to Transformer-based models. In the speech domain, well-designed Transformer-based models, such as the Conformer and E-Branchformer, have become the de facto standards. Extensive evaluations have demonstrated the effectiveness of these Transformer-based models across a wide range of speech tasks. In contrast, the evaluation of SSMs has been limited to a few tasks, such as automatic speech recognition (ASR) and speech synthesis. In this paper, we compared Mamba with state-of-the-art Transformer variants for various speech applications, including ASR, text-to-speech, spoken language understanding, and speech summarization. Experimental evaluations revealed that Mamba achieves comparable or better performance than Transformer-based models, and demonstrated its efficiency in long-form speech processing.
6/26/2024
🤯
Mamba in Speech: Towards an Alternative to Self-Attention
Xiangyu Zhang, Qiquan Zhang, Hexin Liu, Tianyi Xiao, Xinyuan Qian, Beena Ahmed, Eliathamby Ambikairajah, Haizhou Li, Julien Epps
0
0
Transformer and its derivatives have achieved success in diverse tasks across computer vision, natural language processing, and speech processing. To reduce the complexity of computations within the multi-head self-attention mechanism in Transformer, Selective State Space Models (i.e., Mamba) were proposed as an alternative. Mamba exhibited its effectiveness in natural language processing and computer vision tasks, but its superiority has rarely been investigated in speech signal processing. This paper explores solutions for applying Mamba to speech processing using two typical speech processing tasks: speech recognition, which requires semantic and sequential information, and speech enhancement, which focuses primarily on sequential patterns. The experimental results exhibit the superiority of bidirectional Mamba (BiMamba) for speech processing to vanilla Mamba. Moreover, experiments demonstrate the effectiveness of BiMamba as an alternative to the self-attention module in Transformer and its derivates, particularly for the semantic-aware task. The crucial technologies for transferring Mamba to speech are then summarized in ablation studies and the discussion section to offer insights for future research.
5/27/2024

SSAMBA: Self-Supervised Audio Representation Learning with Mamba State Space Model
Siavash Shams, Sukru Samet Dindar, Xilin Jiang, Nima Mesgarani
0
0
Transformers have revolutionized deep learning across various tasks, including audio representation learning, due to their powerful modeling capabilities. However, they often suffer from quadratic complexity in both GPU memory usage and computational inference time, affecting their efficiency. Recently, state space models (SSMs) like Mamba have emerged as a promising alternative, offering a more efficient approach by avoiding these complexities. Given these advantages, we explore the potential of SSM-based models in audio tasks. In this paper, we introduce Self-Supervised Audio Mamba (SSAMBA), the first self-supervised, attention-free, and SSM-based model for audio representation learning. SSAMBA leverages the bidirectional Mamba to capture complex audio patterns effectively. We incorporate a self-supervised pretraining framework that optimizes both discriminative and generative objectives, enabling the model to learn robust audio representations from large-scale, unlabeled datasets. We evaluated SSAMBA on various tasks such as audio classification, keyword spotting, and speaker identification. Our results demonstrate that SSAMBA outperforms the Self-Supervised Audio Spectrogram Transformer (SSAST) in most tasks. Notably, SSAMBA is approximately 92.7% faster in batch inference speed and 95.4% more memory-efficient than SSAST for the tiny model size with an input token size of 22k. These efficiency gains, combined with superior performance, underscore the effectiveness of SSAMBA's architectural innovation, making it a compelling choice for a wide range of audio processing applications.
5/21/2024
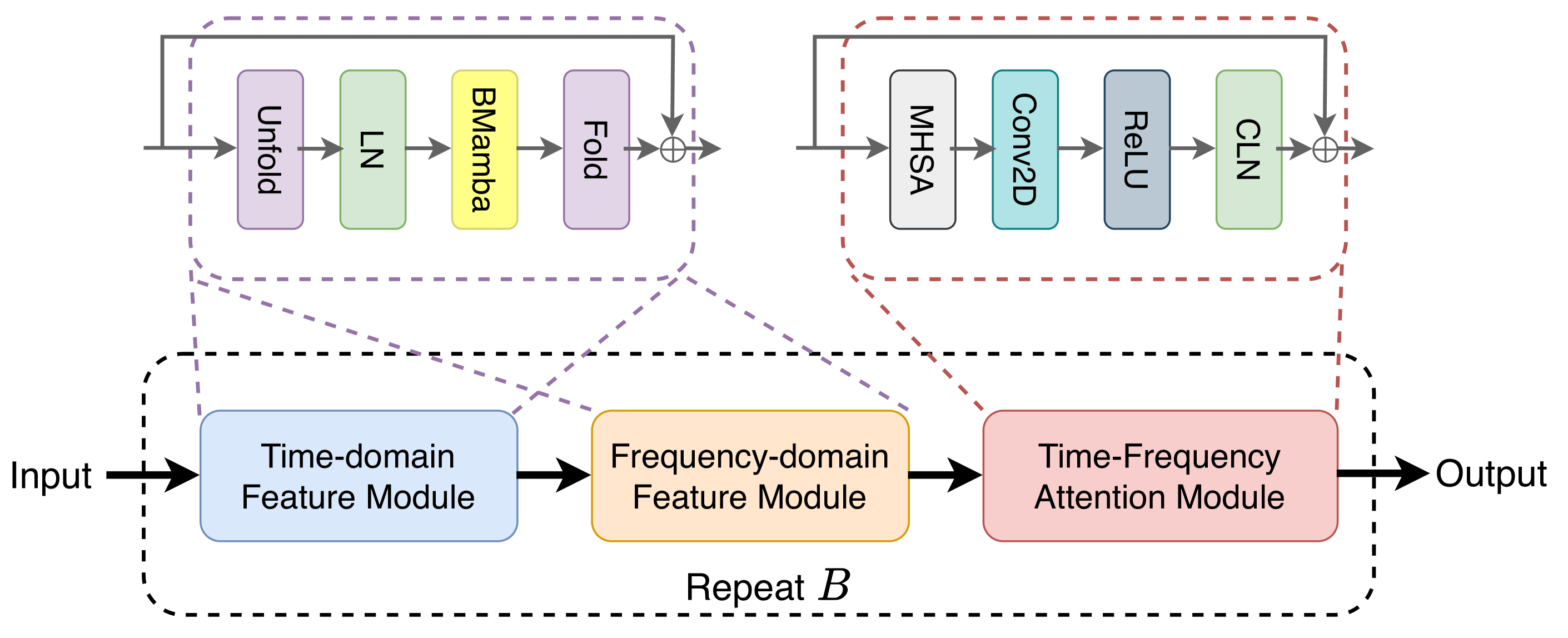
SPMamba: State-space model is all you need in speech separation
Kai Li, Guo Chen
0
0
In speech separation, both CNN- and Transformer-based models have demonstrated robust separation capabilities, garnering significant attention within the research community. However, CNN-based methods have limited modelling capability for long-sequence audio, leading to suboptimal separation performance. Conversely, Transformer-based methods are limited in practical applications due to their high computational complexity. Notably, within computer vision, Mamba-based methods have been celebrated for their formidable performance and reduced computational requirements. In this paper, we propose a network architecture for speech separation using a state-space model, namely SPMamba. We adopt the TF-GridNet model as the foundational framework and substitute its Transformer component with a bidirectional Mamba module, aiming to capture a broader range of contextual information. Our experimental results reveal an important role in the performance aspects of Mamba-based models. SPMamba demonstrates superior performance with a significant advantage over existing separation models in a dataset built on Librispeech. Notably, SPMamba achieves a substantial improvement in separation quality, with a 2.42 dB enhancement in SI-SNRi compared to the TF-GridNet. The source code for SPMamba is publicly accessible at https://github.com/JusperLee/SPMamba .
4/3/2024