The Manga Whisperer: Automatically Generating Transcriptions for Comics

0

Sign in to get full access
Overview
- The paper proposes a system called "The Manga Whisperer" that can automatically generate transcriptions for comics.
- It addresses the challenge of extracting text from comic panels, associating the text with the corresponding speech bubbles, and then transcribing the text.
- The system leverages a combination of computer vision and natural language processing techniques to tackle these tasks.
Plain English Explanation
The paper describes a system called "The Manga Whisperer" that can automatically generate text transcriptions for comics. Comics often contain a mixture of text and images, and extracting the text can be a challenging task. The Manga Whisperer system addresses this by using a combination of computer vision and natural language processing techniques.
First, the system detects and locates the text within the comic panels. It then associates the text with the corresponding speech bubbles or captions. Finally, it transcribes the text, converting the images of text into actual readable text. This allows the content of comics to be more accessible, especially for readers who may have difficulty with the visual aspects of the medium.
The key innovation of this system is its ability to automate the process of extracting and transcribing the text from comics, which can be a time-consuming and tedious task when done manually. By automating this process, the Manga Whisperer can make the content of comics more accessible and searchable, opening up new possibilities for how people interact with and consume this type of media.
Technical Explanation
The paper outlines a detection and association process to address the challenges of extracting text from comic panels and associating it with the corresponding speech bubbles or captions.
First, the system uses computer vision techniques to detect and localize the text within the comic panels. This involves identifying the regions of the image that contain text and delineating the boundaries of individual text elements.
Next, the system associates the detected text with the appropriate speech bubbles or captions using natural language processing techniques. This step involves understanding the semantic and spatial relationships between the text and the visual elements of the comic.
Finally, the system transcribes the text using optical character recognition (OCR) techniques, converting the images of text into machine-readable text that can be used for a variety of applications, such as character identification or text-to-speech conversion.
The paper presents the architecture and implementation details of the Manga Whisperer system, as well as the results of experiments demonstrating its effectiveness in accurately extracting and transcribing text from comic panels.
Critical Analysis
The paper acknowledges some limitations of the Manga Whisperer system, such as its reliance on high-quality comic scans and the potential for errors in the text detection and association steps. The authors also note that the system may struggle with more complex or unconventional comic layouts and styles.
Additionally, the paper does not address potential privacy or ethical concerns that may arise from the automated extraction and transcription of text from comics, which could contain sensitive or copyrighted material.
Further research could explore ways to improve the system's robustness to varying comic styles and layouts, as well as investigate methods for ensuring the privacy and ethical use of the transcribed content.
Conclusion
The Manga Whisperer system represents a significant step forward in automating the process of extracting and transcribing text from comics. By leveraging computer vision and natural language processing techniques, the system can make the content of comics more accessible and searchable, opening up new possibilities for how people interact with and consume this type of media.
The paper provides a detailed technical explanation of the system's architecture and implementation, as well as a critical analysis of its strengths and limitations. While the system has room for improvement, the Manga Whisperer demonstrates the potential for AI-powered tools to enhance the accessibility and usability of visual media like comics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Manga Whisperer: Automatically Generating Transcriptions for Comics
Ragav Sachdeva, Andrew Zisserman
In the past few decades, Japanese comics, commonly referred to as Manga, have transcended both cultural and linguistic boundaries to become a true worldwide sensation. Yet, the inherent reliance on visual cues and illustration within manga renders it largely inaccessible to individuals with visual impairments. In this work, we seek to address this substantial barrier, with the aim of ensuring that manga can be appreciated and actively engaged by everyone. Specifically, we tackle the problem of diarisation i.e. generating a transcription of who said what and when, in a fully automatic way. To this end, we make the following contributions: (1) we present a unified model, Magi, that is able to (a) detect panels, text boxes and character boxes, (b) cluster characters by identity (without knowing the number of clusters apriori), and (c) associate dialogues to their speakers; (2) we propose a novel approach that is able to sort the detected text boxes in their reading order and generate a dialogue transcript; (3) we annotate an evaluation benchmark for this task using publicly available [English] manga pages. The code, evaluation datasets and the pre-trained model can be found at: https://github.com/ragavsachdeva/magi.
Read more8/2/2024

0
Tails Tell Tales: Chapter-Wide Manga Transcriptions with Character Names
Ragav Sachdeva, Gyungin Shin, Andrew Zisserman
Enabling engagement of manga by visually impaired individuals presents a significant challenge due to its inherently visual nature. With the goal of fostering accessibility, this paper aims to generate a dialogue transcript of a complete manga chapter, entirely automatically, with a particular emphasis on ensuring narrative consistency. This entails identifying (i) what is being said, i.e., detecting the texts on each page and classifying them into essential vs non-essential, and (ii) who is saying it, i.e., attributing each dialogue to its speaker, while ensuring the same characters are named consistently throughout the chapter. To this end, we introduce: (i) Magiv2, a model that is capable of generating high-quality chapter-wide manga transcripts with named characters and significantly higher precision in speaker diarisation over prior works; (ii) an extension of the PopManga evaluation dataset, which now includes annotations for speech-bubble tail boxes, associations of text to corresponding tails, classifications of text as essential or non-essential, and the identity for each character box; and (iii) a new character bank dataset, which comprises over 11K characters from 76 manga series, featuring 11.5K exemplar character images in total, as well as a list of chapters in which they appear. The code, trained model, and both datasets can be found at: https://github.com/ragavsachdeva/magi
Read more8/2/2024
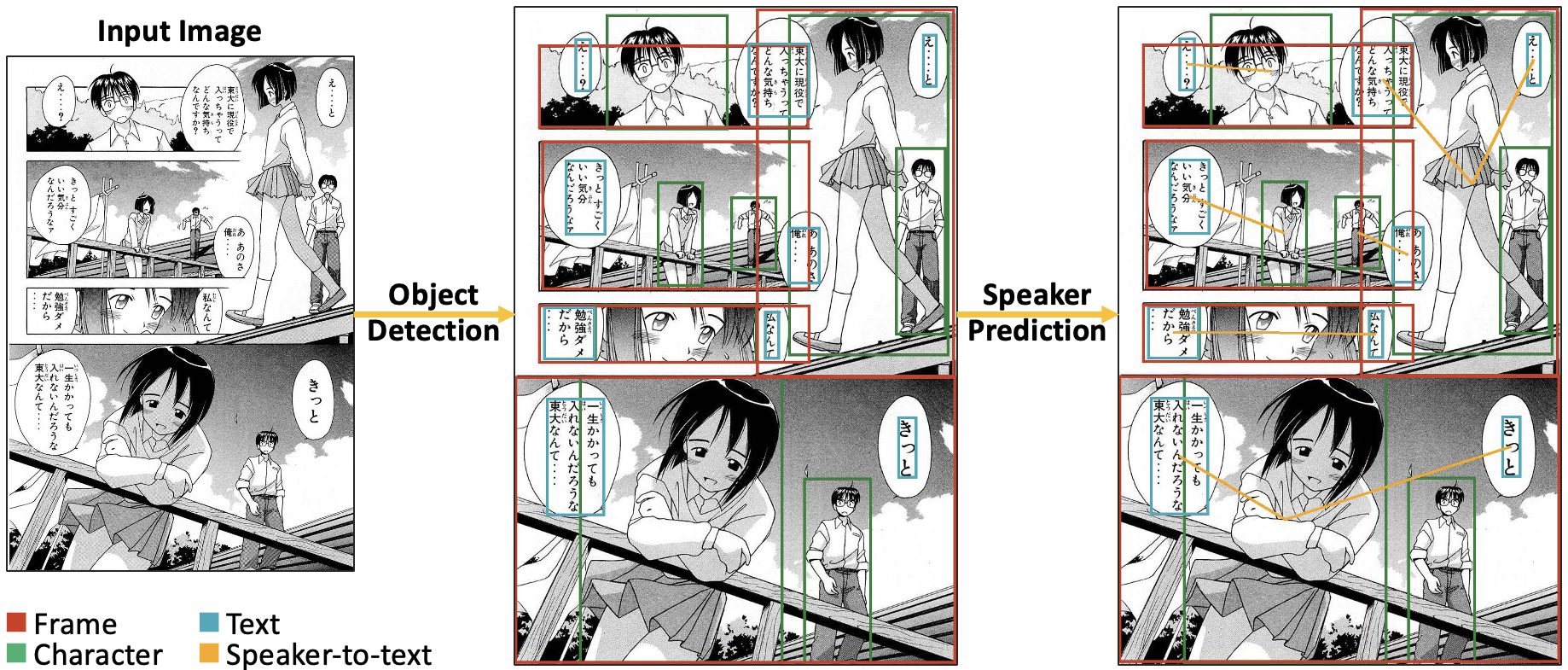
0
Manga109Dialog: A Large-scale Dialogue Dataset for Comics Speaker Detection
Yingxuan Li, Kiyoharu Aizawa, Yusuke Matsui
The expanding market for e-comics has spurred interest in the development of automated methods to analyze comics. For further understanding of comics, an automated approach is needed to link text in comics to characters speaking the words. Comics speaker detection research has practical applications, such as automatic character assignment for audiobooks, automatic translation according to characters' personalities, and inference of character relationships and stories. To deal with the problem of insufficient speaker-to-text annotations, we created a new annotation dataset Manga109Dialog based on Manga109. Manga109Dialog is the world's largest comics speaker annotation dataset, containing 132,692 speaker-to-text pairs. We further divided our dataset into different levels by prediction difficulties to evaluate speaker detection methods more appropriately. Unlike existing methods mainly based on distances, we propose a deep learning-based method using scene graph generation models. Due to the unique features of comics, we enhance the performance of our proposed model by considering the frame reading order. We conducted experiments using Manga109Dialog and other datasets. Experimental results demonstrate that our scene-graph-based approach outperforms existing methods, achieving a prediction accuracy of over 75%.
Read more4/23/2024
👀
0
Toward accessible comics for blind and low vision readers
Christophe Rigaud (L3I), Jean-Christophe Burie (L3I), Samuel Petit (Comix AI)
This work explores how to fine-tune large language models using prompt engineering techniques with contextual information for generating an accurate text description of the full story, ready to be forwarded to off-the-shelve speech synthesis tools. We propose to use existing computer vision and optical character recognition techniques to build a grounded context from the comic strip image content, such as panels, characters, text, reading order and the association of bubbles and characters. Then we infer character identification and generate comic book script with context-aware panel description including character's appearance, posture, mood, dialogues etc. We believe that such enriched content description can be easily used to produce audiobook and eBook with various voices for characters, captions and playing sound effects.
Read more9/11/2024