RoHM: Robust Human Motion Reconstruction via Diffusion
2401.08570
0
1
🧠
Abstract
We propose RoHM, an approach for robust 3D human motion reconstruction from monocular RGB(-D) videos in the presence of noise and occlusions. Most previous approaches either train neural networks to directly regress motion in 3D or learn data-driven motion priors and combine them with optimization at test time. The former do not recover globally coherent motion and fail under occlusions; the latter are time-consuming, prone to local minima, and require manual tuning. To overcome these shortcomings, we exploit the iterative, denoising nature of diffusion models. RoHM is a novel diffusion-based motion model that, conditioned on noisy and occluded input data, reconstructs complete, plausible motions in consistent global coordinates. Given the complexity of the problem -- requiring one to address different tasks (denoising and infilling) in different solution spaces (local and global motion) -- we decompose it into two sub-tasks and learn two models, one for global trajectory and one for local motion. To capture the correlations between the two, we then introduce a novel conditioning module, combining it with an iterative inference scheme. We apply RoHM to a variety of tasks -- from motion reconstruction and denoising to spatial and temporal infilling. Extensive experiments on three popular datasets show that our method outperforms state-of-the-art approaches qualitatively and quantitatively, while being faster at test time. The code is available at https://sanweiliti.github.io/ROHM/ROHM.html.
Create account to get full access
Overview
- Proposes RoHM, a new approach for robust 3D human motion reconstruction from monocular RGB(-D) videos
- Addresses challenges with previous methods, such as lack of globally coherent motion and failure under occlusions
- Leverages the iterative, denoising nature of diffusion models to reconstruct complete, plausible motions
Plain English Explanation
RoHM is a new method for reconstructing 3D human motion from videos captured by a single camera. Many existing techniques either directly predict the 3D motion using neural networks or use optimization-based approaches to combine data-driven motion priors with the input data. However, these methods have limitations - the neural network-based ones may not produce coherent global motion, and the optimization-based ones can be slow and prone to getting stuck in local minima.
To overcome these issues, RoHM uses a diffusion model, which is a type of machine learning model that can denoise and fill in missing information in a step-by-step, iterative manner. RoHM has two separate models - one for reconstructing the overall 3D trajectory of the motion, and one for reconstructing the local details of the motion. These two models are then combined using a novel conditioning module to capture the relationship between the global and local motion.
The key innovation of RoHM is its ability to reconstruct complete, plausible human motions even when the input data is noisy or has occlusions (parts of the body are hidden from the camera). This makes it a robust and versatile tool for human motion analysis in a variety of real-world scenarios.
Technical Explanation
RoHM is a novel diffusion-based motion model that reconstructs complete, plausible 3D human motions from monocular RGB(-D) video inputs, even in the presence of noise and occlusions. The authors identify two key challenges in this problem: 1) recovering globally coherent motion, and 2) handling occlusions and noise in the input data.
To address these challenges, RoHM decomposes the problem into two sub-tasks: reconstructing the global 3D trajectory of the motion, and reconstructing the local details of the motion. The authors train two separate diffusion models, one for each sub-task, and then introduce a novel conditioning module to capture the correlations between the global and local motion.
The global trajectory model takes noisy and occluded input data and iteratively reconstructs the overall 3D path of the motion. The local motion model then takes the global trajectory as input and iteratively reconstructs the detailed joint positions and orientations. By combining these two models, RoHM is able to produce complete, plausible motions that are coherent in both the global and local sense.
Extensive experiments on several popular human motion datasets show that RoHM outperforms state-of-the-art approaches in both qualitative and quantitative metrics, while also being faster at test time.
Critical Analysis
The paper provides a comprehensive evaluation of RoHM's performance on a variety of tasks, including motion reconstruction, denoising, and spatial and temporal infilling. The authors demonstrate that RoHM can effectively handle noisy and occluded input data, a significant improvement over previous methods.
One potential limitation of RoHM is that it requires training two separate models, which may increase the overall complexity and computational cost of the system. It would be interesting to explore ways to further integrate the global and local motion models, perhaps through a more tightly coupled architecture.
Additionally, the paper does not provide a detailed analysis of the failure cases or the types of motions that RoHM may struggle with. Understanding the limitations of the approach and identifying potential areas for improvement would be valuable for advancing the state of the art in this field.
Overall, RoHM represents a promising approach to the challenging problem of robust 3D human motion reconstruction from monocular video. The use of diffusion models to address the issues of global coherence and handling of occlusions is a novel and impactful contribution to the field of human motion analysis.
Conclusion
The RoHM method presented in this paper addresses key limitations of previous approaches to 3D human motion reconstruction from monocular RGB(-D) videos. By leveraging the iterative, denoising capabilities of diffusion models, RoHM is able to reconstruct complete, plausible motions even in the presence of noise and occlusions.
The decomposition of the problem into global trajectory and local motion reconstruction, along with the novel conditioning module, allows RoHM to capture the complex correlations between these different aspects of human movement. The demonstrated improvements over state-of-the-art methods, both qualitatively and quantitatively, suggest that RoHM is a significant step forward in robust human motion analysis.
As the field of computer vision and machine learning continues to advance, techniques like RoHM will play an increasingly important role in enabling a wide range of applications, from animation and virtual reality to healthcare and human-robot interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation
Guanxing Lu, Zifeng Gao, Tianxing Chen, Wenxun Dai, Ziwei Wang, Yansong Tang
0
0
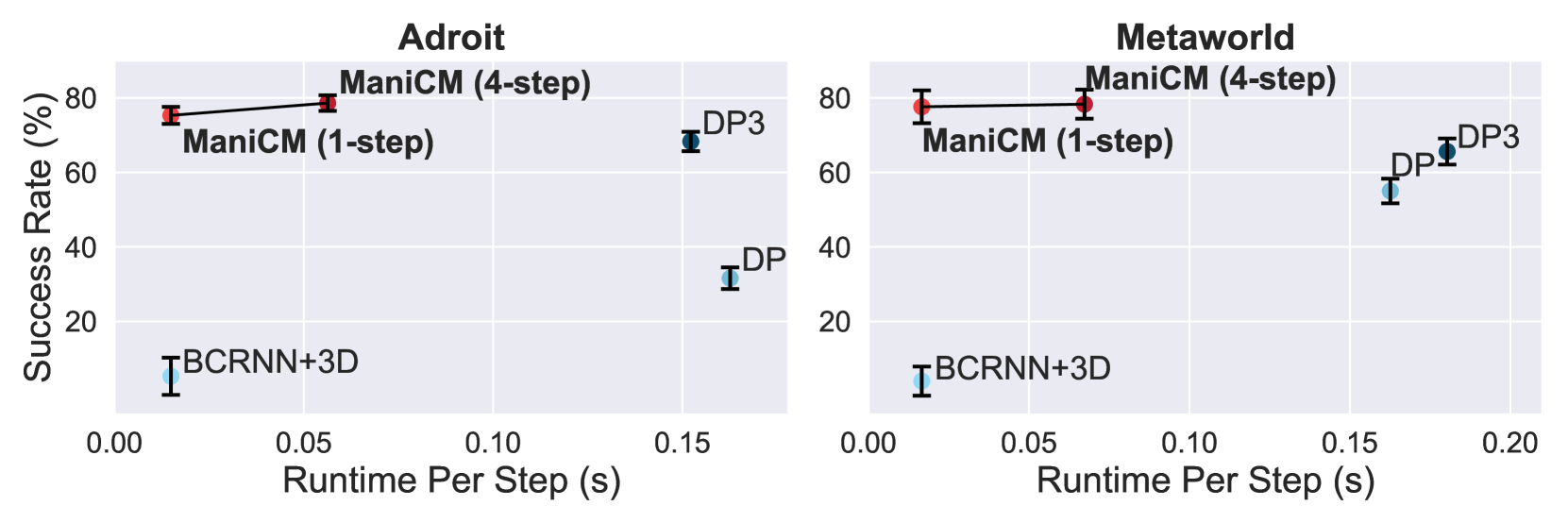
Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference. Specifically, we formulate a consistent diffusion process in the robot action space conditioned on the point cloud input, where the original action is required to be directly denoised from any point along the ODE trajectory. To model this process, we design a consistency distillation technique to predict the action sample directly instead of predicting the noise within the vision community for fast convergence in the low-dimensional action manifold. We evaluate ManiCM on 31 robotic manipulation tasks from Adroit and Metaworld, and the results demonstrate that our approach accelerates the state-of-the-art method by 10 times in average inference speed while maintaining competitive average success rate.
6/4/2024

RecMoDiffuse: Recurrent Flow Diffusion for Human Motion Generation
Mirgahney Mohamed, Harry Jake Cunningham, Marc P. Deisenroth, Lourdes Agapito
0
0
Human motion generation has paramount importance in computer animation. It is a challenging generative temporal modelling task due to the vast possibilities of human motion, high human sensitivity to motion coherence and the difficulty of accurately generating fine-grained motions. Recently, diffusion methods have been proposed for human motion generation due to their high sample quality and expressiveness. However, generated sequences still suffer from motion incoherence, and are limited to short duration, and simpler motion and take considerable time during inference. To address these limitations, we propose textit{RecMoDiffuse: Recurrent Flow Diffusion}, a new recurrent diffusion formulation for temporal modelling. Unlike previous work, which applies diffusion to the whole sequence without any temporal dependency, an approach that inherently makes temporal consistency hard to achieve. Our method explicitly enforces temporal constraints with the means of normalizing flow models in the diffusion process and thereby extends diffusion to the temporal dimension. We demonstrate the effectiveness of RecMoDiffuse in the temporal modelling of human motion. Our experiments show that RecMoDiffuse achieves comparable results with state-of-the-art methods while generating coherent motion sequences and reducing the computational overhead in the inference stage.
6/12/2024
🛸
StableMoFusion: Towards Robust and Efficient Diffusion-based Motion Generation Framework
Yiheng Huang, Hui Yang, Chuanchen Luo, Yuxi Wang, Shibiao Xu, Zhaoxiang Zhang, Man Zhang, Junran Peng
0
0
Thanks to the powerful generative capacity of diffusion models, recent years have witnessed rapid progress in human motion generation. Existing diffusion-based methods employ disparate network architectures and training strategies. The effect of the design of each component is still unclear. In addition, the iterative denoising process consumes considerable computational overhead, which is prohibitive for real-time scenarios such as virtual characters and humanoid robots. For this reason, we first conduct a comprehensive investigation into network architectures, training strategies, and inference processs. Based on the profound analysis, we tailor each component for efficient high-quality human motion generation. Despite the promising performance, the tailored model still suffers from foot skating which is an ubiquitous issue in diffusion-based solutions. To eliminate footskate, we identify foot-ground contact and correct foot motions along the denoising process. By organically combining these well-designed components together, we present StableMoFusion, a robust and efficient framework for human motion generation. Extensive experimental results show that our StableMoFusion performs favorably against current state-of-the-art methods. Project page: https://h-y1heng.github.io/StableMoFusion-page/
5/10/2024
👀
DPHMs: Diffusion Parametric Head Models for Depth-based Tracking
Jiapeng Tang, Angela Dai, Yinyu Nie, Lev Markhasin, Justus Thies, Matthias Niessner
0
0
We introduce Diffusion Parametric Head Models (DPHMs), a generative model that enables robust volumetric head reconstruction and tracking from monocular depth sequences. While recent volumetric head models, such as NPHMs, can now excel in representing high-fidelity head geometries, tracking and reconstructing heads from real-world single-view depth sequences remains very challenging, as the fitting to partial and noisy observations is underconstrained. To tackle these challenges, we propose a latent diffusion-based prior to regularize volumetric head reconstruction and tracking. This prior-based regularizer effectively constrains the identity and expression codes to lie on the underlying latent manifold which represents plausible head shapes. To evaluate the effectiveness of the diffusion-based prior, we collect a dataset of monocular Kinect sequences consisting of various complex facial expression motions and rapid transitions. We compare our method to state-of-the-art tracking methods and demonstrate improved head identity reconstruction as well as robust expression tracking.
4/9/2024