Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation

0
🌀
Sign in to get full access
Overview
- This paper proposes a new method called Consistency Policy to enable faster inference of visuomotor robot control policies compared to the state-of-the-art Diffusion Policy.
- Consistency Policy is designed to work on resource-constrained robotic systems that cannot use high-end GPUs for policy inference due to size, weight, and power constraints.
- The key idea is to distill a faster Consistency Policy from a pre-trained Diffusion Policy by enforcing self-consistency along the Diffusion Policy's learned trajectories.
Plain English Explanation
Robots like mobile manipulators and quadrotors often lack the ability to run advanced computer vision and control algorithms because they don't have the powerful graphics processors (GPUs) required. This prevents them from taking advantage of recent breakthroughs in visuomotor policy architectures that require high-end GPUs to work quickly.
To address this, the researchers developed a new approach called Consistency Policy that can run much faster than the state-of-the-art Diffusion Policy on resource-constrained robots. The key insight is to take the knowledge learned by the powerful Diffusion Policy and distill it into a simpler, faster Consistency Policy.
This is done by enforcing the Consistency Policy to make similar decisions as the Diffusion Policy along the trajectories the Diffusion Policy has learned. This allows the Consistency Policy to maintain the Diffusion Policy's strong performance while running much faster, enabling low-latency decision-making on robots without powerful GPUs.
The researchers show that Consistency Policy outperforms other speed-up methods by an order of magnitude across a variety of simulation and real-world tasks, while still achieving success rates competitive with the original Diffusion Policy.
Technical Explanation
The paper introduces Consistency Policy, a new approach to distilling a faster and similarly powerful visuomotor policy from a pre-trained Diffusion Policy.
The key innovations are:
- Consistency Objective: The Consistency Policy is trained to make similar decisions as the Diffusion Policy along the trajectories the Diffusion Policy has learned, enforcing self-consistency.
- Reduced Initial Sample Variance: The researchers use a smaller initial set of samples to condition the Consistency Policy, reducing the computational complexity.
- Preset Chaining Steps: The number of chaining steps used to generate samples is preset, avoiding the need for expensive planning steps.
The paper evaluates Consistency Policy across 6 simulation tasks and 2 real-world tasks, showing it can speed up inference by an order of magnitude compared to other speed-up methods while maintaining competitive success rates. This makes it suitable for deployment on resource-constrained robotic systems.
The researchers also demonstrate that the Consistency Policy training procedure is robust to the quality of the pre-trained Diffusion Policy, which is a useful property for practitioners.
Critical Analysis
The paper presents a compelling approach to enable advanced visuomotor policies on resource-constrained robotic systems. The key strengths are the significant speed improvements while maintaining strong performance, as well as the robustness to the quality of the pre-trained Diffusion Policy.
However, the paper does not extensively explore the limitations of the Consistency Policy approach. For example, it is unclear how the method would scale to more complex tasks or handle situations where the Diffusion Policy's learned trajectories are suboptimal. Additionally, the real-world experiments are limited in scope, and more extensive deployment on diverse robotic platforms would be helpful to fully assess the practical implications.
Further research could investigate ways to adapt the Consistency Policy training to be even more efficient, such as by leveraging reinforcement learning techniques to directly optimize for fast inference. Exploring other distillation approaches beyond trajectory-level consistency could also lead to additional performance gains.
Conclusion
This paper presents an innovative method called Consistency Policy that enables faster inference of visuomotor control policies on resource-constrained robotic systems. By distilling a simpler policy from a more powerful pre-trained Diffusion Policy, the researchers demonstrate significant speed improvements while maintaining competitive performance across a variety of simulation and real-world tasks.
The key technical contributions, including the consistency objective, reduced initial sample variance, and preset chaining steps, highlight the researchers' thoughtful approach to tackling the challenges of deploying advanced computer vision and control algorithms on space, weight, and power-limited robotic platforms. This work represents an important step forward in making these capabilities more accessible to a wider range of robotic systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
0
Consistency Policy: Accelerated Visuomotor Policies via Consistency Distillation
Aaditya Prasad, Kevin Lin, Jimmy Wu, Linqi Zhou, Jeannette Bohg
Many robotic systems, such as mobile manipulators or quadrotors, cannot be equipped with high-end GPUs due to space, weight, and power constraints. These constraints prevent these systems from leveraging recent developments in visuomotor policy architectures that require high-end GPUs to achieve fast policy inference. In this paper, we propose Consistency Policy, a faster and similarly powerful alternative to Diffusion Policy for learning visuomotor robot control. By virtue of its fast inference speed, Consistency Policy can enable low latency decision making in resource-constrained robotic setups. A Consistency Policy is distilled from a pretrained Diffusion Policy by enforcing self-consistency along the Diffusion Policy's learned trajectories. We compare Consistency Policy with Diffusion Policy and other related speed-up methods across 6 simulation tasks as well as three real-world tasks where we demonstrate inference on a laptop GPU. For all these tasks, Consistency Policy speeds up inference by an order of magnitude compared to the fastest alternative method and maintains competitive success rates. We also show that the Conistency Policy training procedure is robust to the pretrained Diffusion Policy's quality, a useful result that helps practioners avoid extensive testing of the pretrained model. Key design decisions that enabled this performance are the choice of consistency objective, reduced initial sample variance, and the choice of preset chaining steps.
Read more7/2/2024
0
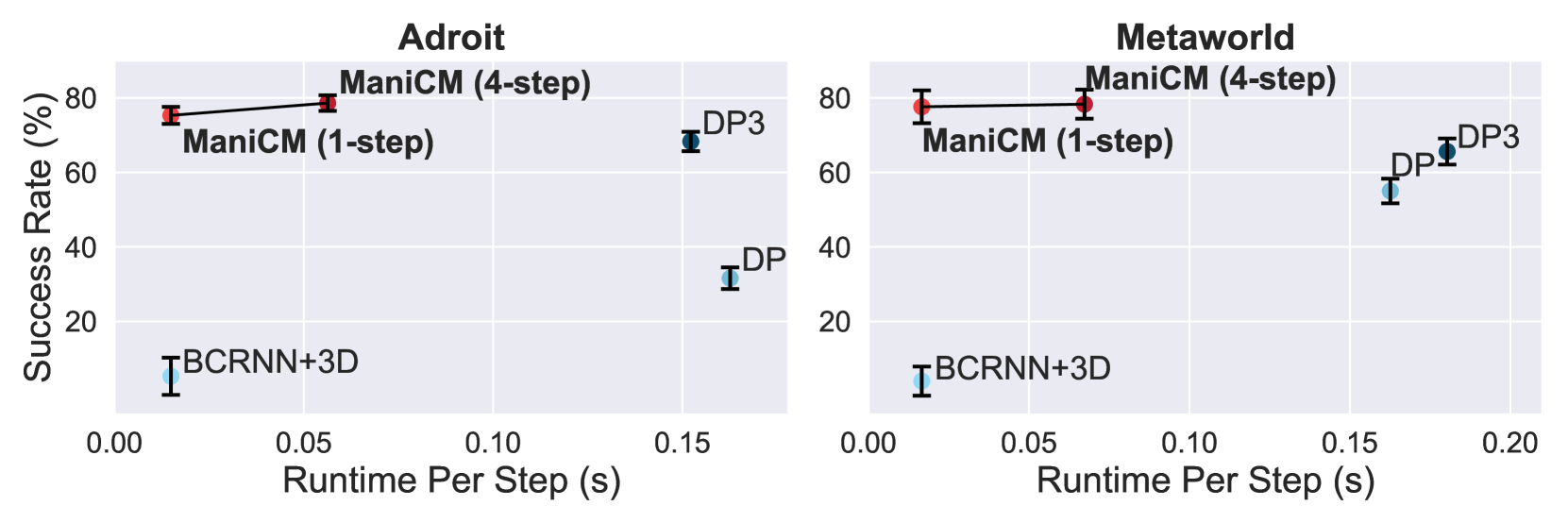
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation
Guanxing Lu, Zifeng Gao, Tianxing Chen, Wenxun Dai, Ziwei Wang, Yansong Tang
Diffusion models have been verified to be effective in generating complex distributions from natural images to motion trajectories. Recent diffusion-based methods show impressive performance in 3D robotic manipulation tasks, whereas they suffer from severe runtime inefficiency due to multiple denoising steps, especially with high-dimensional observations. To this end, we propose a real-time robotic manipulation model named ManiCM that imposes the consistency constraint to the diffusion process, so that the model can generate robot actions in only one-step inference. Specifically, we formulate a consistent diffusion process in the robot action space conditioned on the point cloud input, where the original action is required to be directly denoised from any point along the ODE trajectory. To model this process, we design a consistency distillation technique to predict the action sample directly instead of predicting the noise within the vision community for fast convergence in the low-dimensional action manifold. We evaluate ManiCM on 31 robotic manipulation tasks from Adroit and Metaworld, and the results demonstrate that our approach accelerates the state-of-the-art method by 10 times in average inference speed while maintaining competitive average success rate.
Read more6/4/2024
👁️
0
New!Discrete Policy: Learning Disentangled Action Space for Multi-Task Robotic Manipulation
Kun Wu, Yichen Zhu, Jinming Li, Junjie Wen, Ning Liu, Zhiyuan Xu, Qinru Qiu, Jian Tang
Learning visuomotor policy for multi-task robotic manipulation has been a long-standing challenge for the robotics community. The difficulty lies in the diversity of action space: typically, a goal can be accomplished in multiple ways, resulting in a multimodal action distribution for a single task. The complexity of action distribution escalates as the number of tasks increases. In this work, we propose textbf{Discrete Policy}, a robot learning method for training universal agents capable of multi-task manipulation skills. Discrete Policy employs vector quantization to map action sequences into a discrete latent space, facilitating the learning of task-specific codes. These codes are then reconstructed into the action space conditioned on observations and language instruction. We evaluate our method on both simulation and multiple real-world embodiments, including both single-arm and bimanual robot settings. We demonstrate that our proposed Discrete Policy outperforms a well-established Diffusion Policy baseline and many state-of-the-art approaches, including ACT, Octo, and OpenVLA. For example, in a real-world multi-task training setting with five tasks, Discrete Policy achieves an average success rate that is 26% higher than Diffusion Policy and 15% higher than OpenVLA. As the number of tasks increases to 12, the performance gap between Discrete Policy and Diffusion Policy widens to 32.5%, further showcasing the advantages of our approach. Our work empirically demonstrates that learning multi-task policies within the latent space is a vital step toward achieving general-purpose agents.
Read more9/30/2024

0
Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation
Minjie Zhu, Yichen Zhu, Jinming Li, Junjie Wen, Zhiyuan Xu, Ning Liu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, Jian Tang
Diffusion Policy is a powerful technique tool for learning end-to-end visuomotor robot control. It is expected that Diffusion Policy possesses scalability, a key attribute for deep neural networks, typically suggesting that increasing model size would lead to enhanced performance. However, our observations indicate that Diffusion Policy in transformer architecture (DP) struggles to scale effectively; even minor additions of layers can deteriorate training outcomes. To address this issue, we introduce Scalable Diffusion Transformer Policy for visuomotor learning. Our proposed method, namely textbf{methodname}, introduces two modules that improve the training dynamic of Diffusion Policy and allow the network to better handle multimodal action distribution. First, we identify that DP~suffers from large gradient issues, making the optimization of Diffusion Policy unstable. To resolve this issue, we factorize the feature embedding of observation into multiple affine layers, and integrate it into the transformer blocks. Additionally, our utilize non-causal attention which allows the policy network to enquote{see} future actions during prediction, helping to reduce compounding errors. We demonstrate that our proposed method successfully scales the Diffusion Policy from 10 million to 1 billion parameters. This new model, named methodname, can effectively scale up the model size with improved performance and generalization. We benchmark methodname~across 50 different tasks from MetaWorld and find that our largest methodname~outperforms DP~with an average improvement of 21.6%. Across 7 real-world robot tasks, our ScaleDP demonstrates an average improvement of 36.25% over DP-T on four single-arm tasks and 75% on three bimanual tasks. We believe our work paves the way for scaling up models for visuomotor learning. The project page is available at scaling-diffusion-policy.github.io.
Read more9/24/2024