Mapping Social Choice Theory to RLHF
2404.13038
0
0
🔎
Abstract
Recent work on the limitations of using reinforcement learning from human feedback (RLHF) to incorporate human preferences into model behavior often raises social choice theory as a reference point. Social choice theory's analysis of settings such as voting mechanisms provides technical infrastructure that can inform how to aggregate human preferences amid disagreement. We analyze the problem settings of social choice and RLHF, identify key differences between them, and discuss how these differences may affect the RLHF interpretation of well-known technical results in social choice.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the connections between social choice theory and reinforcement learning from human feedback (RLHF), a technique used to align AI systems with human preferences.
- It examines how principles from social choice theory, such as voting rules and preference modeling, can be applied to the challenge of preference learning in RLHF.
- The paper provides a framework for understanding the relationship between these two fields and highlights potential avenues for further research at their intersection.
Plain English Explanation
Social choice theory is a branch of mathematics that studies how to make collective decisions based on individual preferences. This paper explores how the concepts from social choice theory can be applied to the problem of training AI systems to behave in alignment with human preferences.
The key idea is that when we train an AI system using reinforcement learning from human feedback (RLHF), we are essentially trying to aggregate the preferences of many different humans into a single coherent set of preferences that the AI can learn. This is similar to the problem of voting and social choice, where we need to combine the preferences of many individuals into a collective decision.
By drawing parallels between preference modeling in RLHF and social choice theory, the paper provides a framework for understanding how to effectively align AI systems with diverse human preferences. It also highlights important considerations, such as the influence of the reward function and the difficulty of eliciting accurate preference information from humans.
The paper suggests that further research at the intersection of social choice theory and RLHF could yield valuable insights for efficiently modeling human preferences and aligning AI systems with them.
Technical Explanation
The paper starts by outlining the connections between preference modeling in RLHF and the problems studied in social choice theory. It argues that the challenge of aggregating diverse human preferences into a single reward function for an AI system is analogous to the problem of defining a voting rule in social choice theory.
The authors then dive deeper into the specific learning problems involved in RLHF, namely preference modeling and social choice. They discuss how the choice of voting rule (or preference modeling approach) can have a significant impact on the resulting preferences learned by the AI system.
The paper explores the implications of different voting rules, such as majority rule, Borda count, and ranked-choice voting, and how they might be applied in the context of RLHF. It also considers the role of the reward function and how it can influence the preference learning process.
Furthermore, the paper highlights the importance of accurately eliciting human preferences and the potential pitfalls, such as the impact of the reward margin on the learned preferences.
The technical explanation concludes by discussing potential avenues for leveraging domain knowledge and efficient reward modeling techniques to improve the RLHF process.
Critical Analysis
The paper provides a valuable conceptual framework for understanding the challenges of aligning AI systems with diverse human preferences through the lens of social choice theory. However, it is important to note that the practical implementation and empirical validation of these ideas are not fully explored in the paper.
One potential limitation is the reliance on simplistic voting rules, such as majority rule, which may not adequately capture the nuances of human preferences in complex real-world scenarios. The paper acknowledges this and suggests the need for further research into more sophisticated preference modeling techniques.
Additionally, the paper does not delve deeply into the potential biases and limitations of using human feedback as the basis for preference learning. There may be challenges related to the reliability and representativeness of the human feedback data, which could impact the AI's alignment with broader societal preferences.
Finally, the paper focuses primarily on the theoretical and conceptual aspects of the problem, without providing extensive empirical evidence or practical guidelines for implementing these ideas in real-world AI systems. Further research and validation in this direction would be valuable for practitioners in the field.
Conclusion
This paper establishes an important connection between the fields of social choice theory and reinforcement learning from human feedback (RLHF), which are both concerned with the challenge of aligning AI systems with human preferences.
By drawing these parallels, the paper provides a conceptual framework for understanding the complex task of preference modeling and social choice in the context of AI alignment. It suggests that further research at this intersection could yield valuable insights for efficiently and effectively aligning AI systems with diverse human preferences.
The paper highlights the importance of considering voting rules, reward functions, and preference elicitation in the RLHF process, while also acknowledging the potential limitations and avenues for further research. As the field of AI continues to evolve, this work provides a foundation for exploring new approaches to leveraging domain knowledge and efficient reward modeling techniques in the pursuit of AI alignment with human values.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
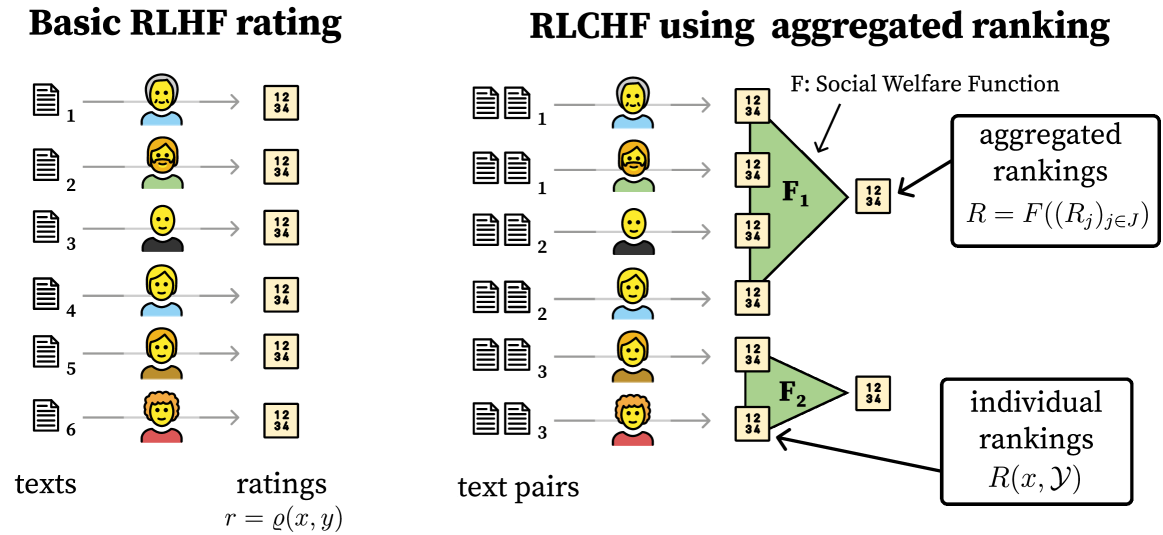
Social Choice for AI Alignment: Dealing with Diverse Human Feedback
Vincent Conitzer, Rachel Freedman, Jobst Heitzig, Wesley H. Holliday, Bob M. Jacobs, Nathan Lambert, Milan Moss'e, Eric Pacuit, Stuart Russell, Hailey Schoelkopf, Emanuel Tewolde, William S. Zwicker
0
0
Foundation models such as GPT-4 are fine-tuned to avoid unsafe or otherwise problematic behavior, so that, for example, they refuse to comply with requests for help with committing crimes or with producing racist text. One approach to fine-tuning, called reinforcement learning from human feedback, learns from humans' expressed preferences over multiple outputs. Another approach is constitutional AI, in which the input from humans is a list of high-level principles. But how do we deal with potentially diverging input from humans? How can we aggregate the input into consistent data about ''collective'' preferences or otherwise use it to make collective choices about model behavior? In this paper, we argue that the field of social choice is well positioned to address these questions, and we discuss ways forward for this agenda, drawing on discussions in a recent workshop on Social Choice for AI Ethics and Safety held in Berkeley, CA, USA in December 2023.
4/17/2024
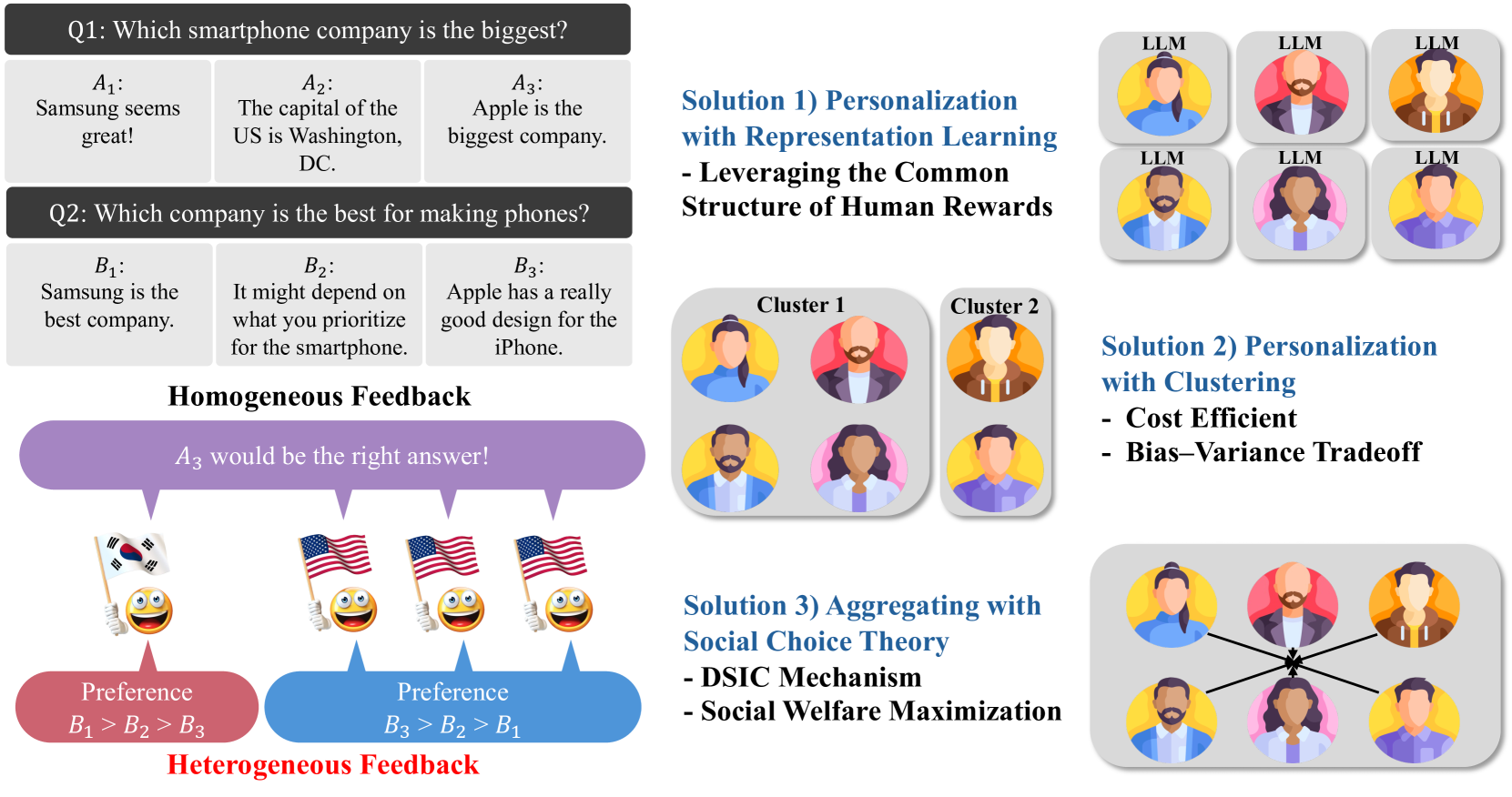
Principled RLHF from Heterogeneous Feedback via Personalization and Preference Aggregation
Chanwoo Park, Mingyang Liu, Kaiqing Zhang, Asuman Ozdaglar
0
0
Reinforcement learning from human feedback (RLHF) has been an effective technique for aligning AI systems with human values, with remarkable successes in fine-tuning large-language models recently. Most existing RLHF paradigms make the underlying assumption that human preferences are relatively homogeneous, and can be encoded by a single reward model. In this paper, we focus on addressing the issues due to the inherent heterogeneity in human preferences, as well as their potential strategic behavior in providing feedback. Specifically, we propose two frameworks to address heterogeneous human feedback in principled ways: personalization-based one and aggregation-based one. For the former, we propose two approaches based on representation learning and clustering, respectively, for learning multiple reward models that trades off the bias (due to preference heterogeneity) and variance (due to the use of fewer data for learning each model by personalization). We then establish sample complexity guarantees for both approaches. For the latter, we aim to adhere to the single-model framework, as already deployed in the current RLHF paradigm, by carefully aggregating diverse and truthful preferences from humans. We propose two approaches based on reward and preference aggregation, respectively: the former utilizes both utilitarianism and Leximin approaches to aggregate individual reward models, with sample complexity guarantees; the latter directly aggregates the human feedback in the form of probabilistic opinions. Under the probabilistic-opinion-feedback model, we also develop an approach to handle strategic human labelers who may bias and manipulate the aggregated preferences with untruthful feedback. Based on the ideas in mechanism design, our approach ensures truthful preference reporting, with the induced aggregation rule maximizing social welfare functions.
5/2/2024
🏅
A Survey of Reinforcement Learning from Human Feedback
Timo Kaufmann, Paul Weng, Viktor Bengs, Eyke Hullermeier
0
0
Reinforcement learning from human feedback (RLHF) is a variant of reinforcement learning (RL) that learns from human feedback instead of relying on an engineered reward function. Building on prior work on the related setting of preference-based reinforcement learning (PbRL), it stands at the intersection of artificial intelligence and human-computer interaction. This positioning offers a promising avenue to enhance the performance and adaptability of intelligent systems while also improving the alignment of their objectives with human values. The training of large language models (LLMs) has impressively demonstrated this potential in recent years, where RLHF played a decisive role in directing the model's capabilities toward human objectives. This article provides a comprehensive overview of the fundamentals of RLHF, exploring the intricate dynamics between RL agents and human input. While recent focus has been on RLHF for LLMs, our survey adopts a broader perspective, examining the diverse applications and wide-ranging impact of the technique. We delve into the core principles that underpin RLHF, shedding light on the symbiotic relationship between algorithms and human feedback, and discuss the main research trends in the field. By synthesizing the current landscape of RLHF research, this article aims to provide researchers as well as practitioners with a comprehensive understanding of this rapidly growing field of research.
5/1/2024
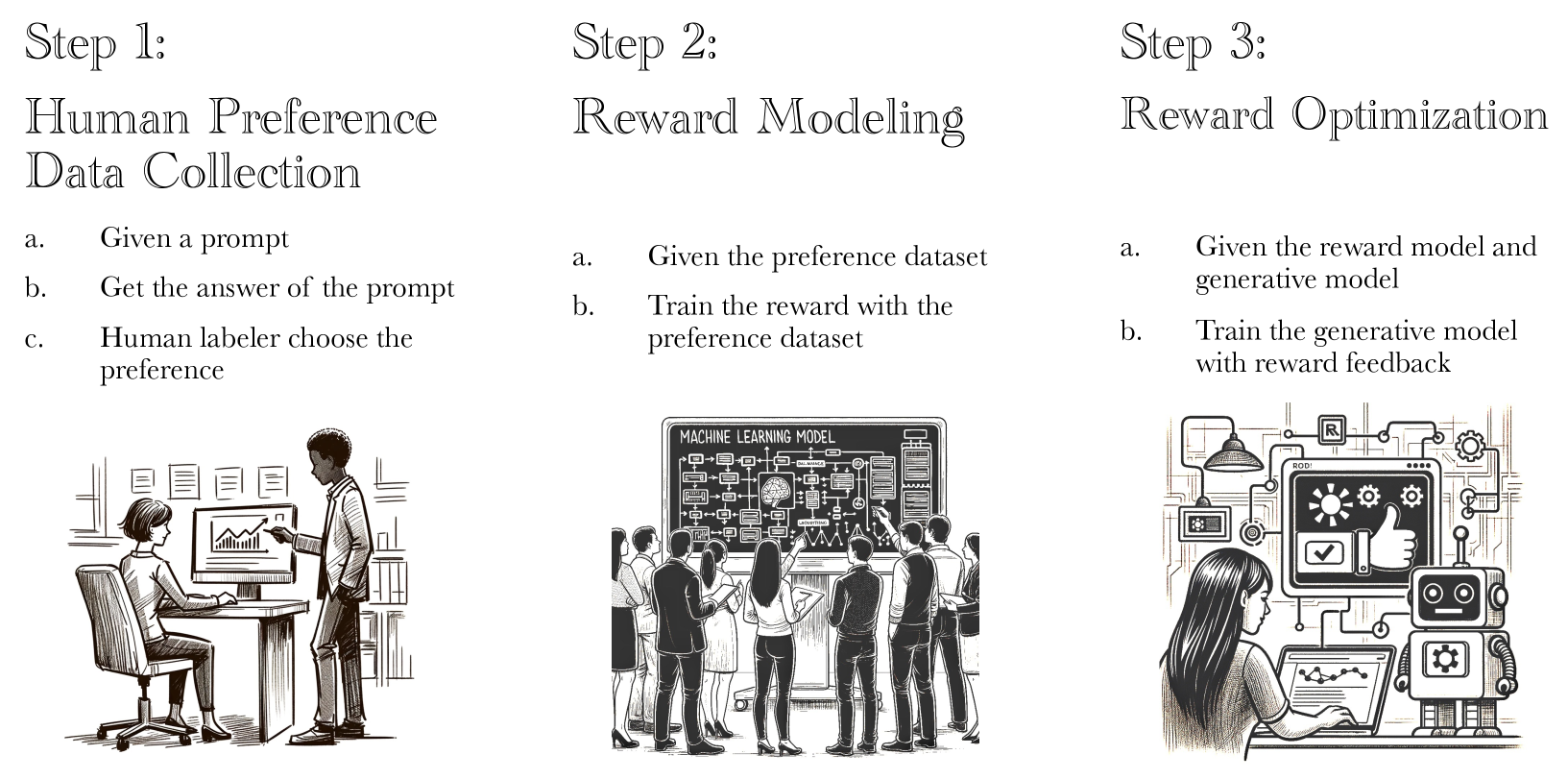
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024