Margin-aware Preference Optimization for Aligning Diffusion Models without Reference
2406.06424
0
0
🛠️
Abstract
Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this reference mismatch is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods. Our code, models, and datasets are publicly available via https://mapo-t2i.github.io
Create account to get full access
Overview
- This paper focuses on addressing the challenge of aligning recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), with human preferences.
- Conventional alignment techniques like RLHF and DPO can be limited when there is a clear distributional discrepancy between the preference data and the reference model.
- The authors propose a novel method called Margin-Aware Preference Optimization (MaPO) that does not rely on a reference model and jointly maximizes the likelihood margin between preferred and dispreferred image sets, while also learning general stylistic features and preferences.
Plain English Explanation
Diffusion models, like Stable Diffusion XL, are powerful AI systems that can generate images from text descriptions. However, aligning these models with human preferences can be challenging, especially when there is a mismatch between the reference model and the preference data.
Conventional approaches, such as Reinforcement Learning from Human Feedback (RLHF) and Divergent Policy Optimization (DPO), often rely on a reference model to guide the alignment process. But this can be limiting when the reference model and the preference data have very different distributions, like when users prefer a particular artistic style that the reference model doesn't capture well.
To address this issue, the researchers propose a new method called Margin-Aware Preference Optimization (MaPO). Instead of using a reference model, MaPO jointly optimizes the likelihood margin between preferred and dispreferred image sets, while also learning the general stylistic features and preferences. This allows the model to be more flexible and better aligned with human preferences, even when there is a clear distributional mismatch.
The researchers also introduce two new datasets, Pick-Style and Pick-Safety, which simulate diverse scenarios of reference mismatch. Their experiments show that MaPO can significantly improve alignment on these datasets and outperform other existing methods when used with the Pick-a-Pic v2 dataset.
Technical Explanation
The paper focuses on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), with human preferences. Conventional alignment techniques like RLHF and DPO often rely on divergence regularization relative to a reference model to ensure training stability. However, this approach can limit the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model.
To address this challenge, the authors propose a novel and memory-friendly preference alignment method for diffusion models called Margin-Aware Preference Optimization (MaPO). MaPO does not depend on any reference model and instead jointly maximizes the likelihood margin between the preferred and dispreferred image sets, while also learning general stylistic features and preferences.
For evaluation, the researchers introduce two new pairwise preference datasets, Pick-Style and Pick-Safety, which simulate diverse scenarios of reference mismatch. Their experiments show that MaPO can significantly improve alignment on these datasets and outperform other existing methods when used with the Pick-a-Pic v2 dataset.
Critical Analysis
The paper presents a compelling solution to the challenge of aligning diffusion models with human preferences, especially when there is a clear distributional discrepancy between the preference data and the reference model. The authors' proposed MaPO method, which doesn't rely on a reference model, is a promising approach that could have broader applications beyond text-to-image generation.
However, the paper does not extensively discuss the potential limitations or caveats of the MaPO method. For instance, it would be interesting to understand how well MaPO performs in scenarios where the preferred and dispreferred image sets are not well-defined or have significant overlap. Additionally, the paper could have explored the potential computational and memory trade-offs of the MaPO approach compared to reference-based methods.
Furthermore, the paper's introduction of the Pick-Style and Pick-Safety datasets is a valuable contribution, as it provides a way to evaluate alignment methods in more realistic scenarios. However, it would be helpful to understand how these datasets were constructed and how they relate to real-world preference alignment challenges.
Overall, the paper presents a well-designed and effective solution to a significant problem in the field of AI alignment. By encouraging readers to think critically about the research and its potential limitations, the authors could further strengthen the impact of their work and inspire future research in this important area.
Conclusion
This paper addresses the challenge of aligning recent text-to-image diffusion models, such as Stable Diffusion XL, with human preferences. The authors propose a novel method called Margin-Aware Preference Optimization (MaPO) that does not rely on a reference model, but instead jointly maximizes the likelihood margin between preferred and dispreferred image sets, while also learning general stylistic features and preferences.
The researchers' experiments demonstrate that MaPO can significantly improve alignment on their newly introduced Pick-Style and Pick-Safety datasets, which simulate diverse scenarios of reference mismatch. When used with the Pick-a-Pic v2 dataset, MaPO also outperforms other existing alignment methods.
This work represents an important step forward in the field of AI alignment, as it addresses a key limitation of conventional approaches and introduces a more flexible and effective way to align diffusion models with human preferences. The insights and techniques presented in this paper could inspire further research and development in this critical area, ultimately leading to AI systems that are better aligned with human values and priorities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffusion-RPO: Aligning Diffusion Models through Relative Preference Optimization
Yi Gu, Zhendong Wang, Yueqin Yin, Yujia Xie, Mingyuan Zhou
0
0
Aligning large language models with human preferences has emerged as a critical focus in language modeling research. Yet, integrating preference learning into Text-to-Image (T2I) generative models is still relatively uncharted territory. The Diffusion-DPO technique made initial strides by employing pairwise preference learning in diffusion models tailored for specific text prompts. We introduce Diffusion-RPO, a new method designed to align diffusion-based T2I models with human preferences more effectively. This approach leverages both prompt-image pairs with identical prompts and those with semantically related content across various modalities. Furthermore, we have developed a new evaluation metric, style alignment, aimed at overcoming the challenges of high costs, low reproducibility, and limited interpretability prevalent in current evaluations of human preference alignment. Our findings demonstrate that Diffusion-RPO outperforms established methods such as Supervised Fine-Tuning and Diffusion-DPO in tuning Stable Diffusion versions 1.5 and XL-1.0, achieving superior results in both automated evaluations of human preferences and style alignment. Our code is available at https://github.com/yigu1008/Diffusion-RPO
6/11/2024

Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step
Zhanhao Liang, Yuhui Yuan, Shuyang Gu, Bohan Chen, Tiankai Hang, Ji Li, Liang Zheng
0
0
Recently, Direct Preference Optimization (DPO) has extended its success from aligning large language models (LLMs) to aligning text-to-image diffusion models with human preferences. Unlike most existing DPO methods that assume all diffusion steps share a consistent preference order with the final generated images, we argue that this assumption neglects step-specific denoising performance and that preference labels should be tailored to each step's contribution. To address this limitation, we propose Step-aware Preference Optimization (SPO), a novel post-training approach that independently evaluates and adjusts the denoising performance at each step, using a step-aware preference model and a step-wise resampler to ensure accurate step-aware supervision. Specifically, at each denoising step, we sample a pool of images, find a suitable win-lose pair, and, most importantly, randomly select a single image from the pool to initialize the next denoising step. This step-wise resampler process ensures the next win-lose image pair comes from the same image, making the win-lose comparison independent of the previous step. To assess the preferences at each step, we train a separate step-aware preference model that can be applied to both noisy and clean images. Our experiments with Stable Diffusion v1.5 and SDXL demonstrate that SPO significantly outperforms the latest Diffusion-DPO in aligning generated images with complex, detailed prompts and enhancing aesthetics, while also achieving more than 20x times faster in training efficiency. Code and model: https://rockeycoss.github.io/spo.github.io/
6/7/2024
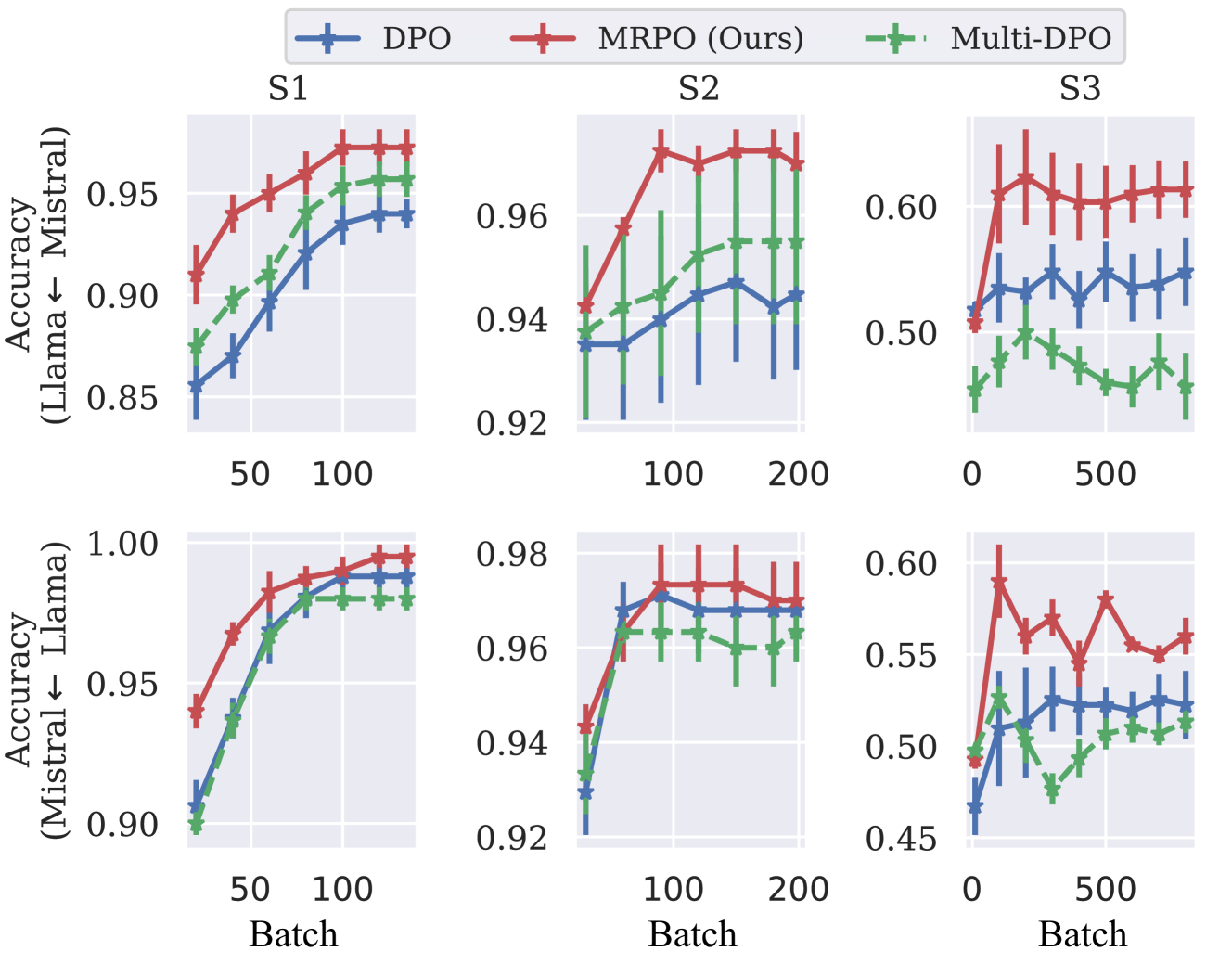
Multi-Reference Preference Optimization for Large Language Models
Hung Le, Quan Tran, Dung Nguyen, Kien Do, Saloni Mittal, Kelechi Ogueji, Svetha Venkatesh
0
0
How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
5/28/2024

mDPO: Conditional Preference Optimization for Multimodal Large Language Models
Fei Wang, Wenxuan Zhou, James Y. Huang, Nan Xu, Sheng Zhang, Hoifung Poon, Muhao Chen
0
0
Direct preference optimization (DPO) has shown to be an effective method for large language model (LLM) alignment. Recent works have attempted to apply DPO to multimodal scenarios but have found it challenging to achieve consistent improvement. Through a comparative experiment, we identify the unconditional preference problem in multimodal preference optimization, where the model overlooks the image condition. To address this problem, we propose mDPO, a multimodal DPO objective that prevents the over-prioritization of language-only preferences by also optimizing image preference. Moreover, we introduce a reward anchor that forces the reward to be positive for chosen responses, thereby avoiding the decrease in their likelihood -- an intrinsic problem of relative preference optimization. Experiments on two multimodal LLMs of different sizes and three widely used benchmarks demonstrate that mDPO effectively addresses the unconditional preference problem in multimodal preference optimization and significantly improves model performance, particularly in reducing hallucination.
6/18/2024