Step-aware Preference Optimization: Aligning Preference with Denoising Performance at Each Step
2406.04314
0
0

Abstract
Recently, Direct Preference Optimization (DPO) has extended its success from aligning large language models (LLMs) to aligning text-to-image diffusion models with human preferences. Unlike most existing DPO methods that assume all diffusion steps share a consistent preference order with the final generated images, we argue that this assumption neglects step-specific denoising performance and that preference labels should be tailored to each step's contribution. To address this limitation, we propose Step-aware Preference Optimization (SPO), a novel post-training approach that independently evaluates and adjusts the denoising performance at each step, using a step-aware preference model and a step-wise resampler to ensure accurate step-aware supervision. Specifically, at each denoising step, we sample a pool of images, find a suitable win-lose pair, and, most importantly, randomly select a single image from the pool to initialize the next denoising step. This step-wise resampler process ensures the next win-lose image pair comes from the same image, making the win-lose comparison independent of the previous step. To assess the preferences at each step, we train a separate step-aware preference model that can be applied to both noisy and clean images. Our experiments with Stable Diffusion v1.5 and SDXL demonstrate that SPO significantly outperforms the latest Diffusion-DPO in aligning generated images with complex, detailed prompts and enhancing aesthetics, while also achieving more than 20x times faster in training efficiency. Code and model: https://rockeycoss.github.io/spo.github.io/
Create account to get full access
Overview
- The paper proposes a new approach called "Step-aware Preference Optimization" (SAPO) that aims to align the preference of a language model with its denoising performance at each step during the optimization process.
- This is in contrast to previous approaches that only optimize for the final denoising performance, which can lead to misalignment between the model's preference and its actual denoising capabilities at intermediate steps.
- SAPO addresses this issue by explicitly optimizing the model's preference to match its step-wise denoising performance, leading to more effective and stable optimization.
Plain English Explanation
The paper introduces a new way to train language models that helps ensure the model's preferences (what it "likes" or "wants" to output) are well-aligned with how well it can actually denoise or clean up noisy text at each step of the training process. Previous methods only focused on optimizing the final denoising performance, which can cause a mismatch between what the model prefers to output and what it's actually good at doing during the training.
The new "Provably Robust DPO" approach, called "Step-aware Preference Optimization" (SAPO), directly optimizes the model's preferences to match its denoising capabilities at each individual training step. This helps keep the model's preferences and actual abilities in sync throughout the optimization, leading to more effective and stable training overall.
The key idea is that by aligning the model's preferences with its step-wise denoising performance, you can avoid situations where the model learns to prefer outputs that it's actually not very good at producing. This mismatch can hamper the model's ability to truly denoise text effectively. The "Curriculum Direct Preference Optimization" and "Soft Preference Optimization" approaches also aimed to address this issue, but the new SAPO method provides a more principled way to solve it.
Technical Explanation
The key innovation of the "Step-aware Preference Optimization" (SAPO) method is that it explicitly optimizes the language model's preferences to match its step-wise denoising performance, rather than just optimizing for the final denoising performance as in previous approaches like "Filtered Direct Preference Optimization" and "Mallows DPO".
The authors formulate this as a bi-level optimization problem, where the outer loop optimizes the model's preferences to align with its step-wise denoising capabilities, and the inner loop trains the model to actually perform the denoising task. This ensures that the model's preferences are well-matched to its abilities at each step of the optimization process, rather than just the final outcome.
Experiments on text denoising benchmarks show that SAPO outperforms previous preference optimization methods in terms of both denoising performance and preference alignment. The authors also provide theoretical analysis to demonstrate the benefits of the step-aware approach compared to optimizing only for the final denoising objective.
Critical Analysis
The paper makes a compelling case for the importance of aligning a language model's preferences with its step-wise denoising performance, and the SAPO method appears to be an effective way to achieve this. However, the authors acknowledge that the bi-level optimization process can be computationally expensive, which may limit the practical applicability of the approach, especially for large-scale language models.
Additionally, the paper focuses on the specific task of text denoising, and it's unclear how well the SAPO method would generalize to other preference alignment tasks or language model applications. Further research would be needed to explore the broader applicability of this approach.
Finally, the paper does not discuss potential negative societal impacts or ethical considerations that could arise from language models with carefully aligned preferences, which is an important area for future work in this field.
Conclusion
The "Step-aware Preference Optimization" (SAPO) method introduced in this paper represents an important advance in the field of language model optimization. By explicitly aligning the model's preferences with its step-wise denoising capabilities, SAPO can produce more effective and stable models that are better able to denoise text compared to previous approaches.
While the computational complexity of the bi-level optimization process may limit the immediate practical applicability of SAPO, the underlying principles of the method could inspire further research into preference alignment techniques that can be applied more broadly to a variety of language model tasks and applications. As the field of language modeling continues to evolve, approaches like SAPO will play a crucial role in ensuring that these powerful AI systems behave in ways that are well-aligned with their intended goals and capabilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, Jiaya Jia
0
0
Mathematical reasoning presents a significant challenge for Large Language Models (LLMs) due to the extensive and precise chain of reasoning required for accuracy. Ensuring the correctness of each reasoning step is critical. To address this, we aim to enhance the robustness and factuality of LLMs by learning from human feedback. However, Direct Preference Optimization (DPO) has shown limited benefits for long-chain mathematical reasoning, as models employing DPO struggle to identify detailed errors in incorrect answers. This limitation stems from a lack of fine-grained process supervision. We propose a simple, effective, and data-efficient method called Step-DPO, which treats individual reasoning steps as units for preference optimization rather than evaluating answers holistically. Additionally, we have developed a data construction pipeline for Step-DPO, enabling the creation of a high-quality dataset containing 10K step-wise preference pairs. We also observe that in DPO, self-generated data is more effective than data generated by humans or GPT-4, due to the latter's out-of-distribution nature. Our findings demonstrate that as few as 10K preference data pairs and fewer than 500 Step-DPO training steps can yield a nearly 3% gain in accuracy on MATH for models with over 70B parameters. Notably, Step-DPO, when applied to Qwen2-72B-Instruct, achieves scores of 70.8% and 94.0% on the test sets of MATH and GSM8K, respectively, surpassing a series of closed-source models, including GPT-4-1106, Claude-3-Opus, and Gemini-1.5-Pro. Our code, data, and models are available at https://github.com/dvlab-research/Step-DPO.
6/28/2024

Diffusion-RPO: Aligning Diffusion Models through Relative Preference Optimization
Yi Gu, Zhendong Wang, Yueqin Yin, Yujia Xie, Mingyuan Zhou
0
0
Aligning large language models with human preferences has emerged as a critical focus in language modeling research. Yet, integrating preference learning into Text-to-Image (T2I) generative models is still relatively uncharted territory. The Diffusion-DPO technique made initial strides by employing pairwise preference learning in diffusion models tailored for specific text prompts. We introduce Diffusion-RPO, a new method designed to align diffusion-based T2I models with human preferences more effectively. This approach leverages both prompt-image pairs with identical prompts and those with semantically related content across various modalities. Furthermore, we have developed a new evaluation metric, style alignment, aimed at overcoming the challenges of high costs, low reproducibility, and limited interpretability prevalent in current evaluations of human preference alignment. Our findings demonstrate that Diffusion-RPO outperforms established methods such as Supervised Fine-Tuning and Diffusion-DPO in tuning Stable Diffusion versions 1.5 and XL-1.0, achieving superior results in both automated evaluations of human preferences and style alignment. Our code is available at https://github.com/yigu1008/Diffusion-RPO
6/11/2024
🛠️
Margin-aware Preference Optimization for Aligning Diffusion Models without Reference
Jiwoo Hong, Sayak Paul, Noah Lee, Kashif Rasul, James Thorne, Jongheon Jeong
0
0
Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this reference mismatch is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods. Our code, models, and datasets are publicly available via https://mapo-t2i.github.io
6/11/2024
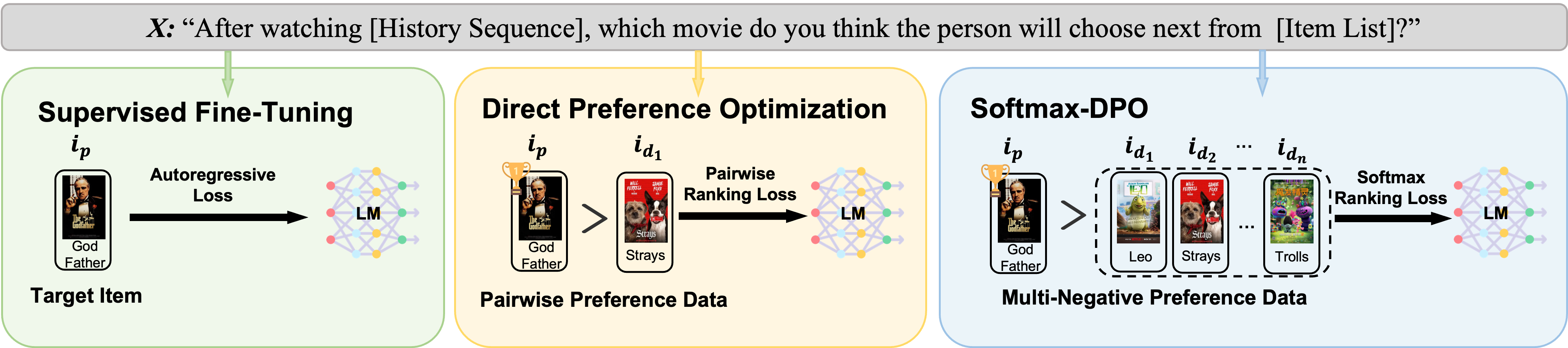
On Softmax Direct Preference Optimization for Recommendation
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, Tat-Seng Chua
0
0
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
6/17/2024