GeoEval: Benchmark for Evaluating LLMs and Multi-Modal Models on Geometry Problem-Solving
2402.10104
0
0
⚙️
Abstract
Recent advancements in large language models (LLMs) and multi-modal models (MMs) have demonstrated their remarkable capabilities in problem-solving. Yet, their proficiency in tackling geometry math problems, which necessitates an integrated understanding of both textual and visual information, has not been thoroughly evaluated. To address this gap, we introduce the GeoEval benchmark, a comprehensive collection that includes a main subset of 2,000 problems, a 750 problems subset focusing on backward reasoning, an augmented subset of 2,000 problems, and a hard subset of 300 problems. This benchmark facilitates a deeper investigation into the performance of LLMs and MMs in solving geometry math problems. Our evaluation of ten LLMs and MMs across these varied subsets reveals that the WizardMath model excels, achieving a 55.67% accuracy rate on the main subset but only a 6.00% accuracy on the hard subset. This highlights the critical need for testing models against datasets on which they have not been pre-trained. Additionally, our findings indicate that GPT-series models perform more effectively on problems they have rephrased, suggesting a promising method for enhancing model capabilities.
Create account to get full access
Overview
- This research paper examines the ability of large language models (LLMs) and multi-modal models (MMs) to solve geometry math problems, which require integrating textual and visual information.
- The authors introduce the GeoEval benchmark, a comprehensive dataset to evaluate model performance on geometry problems.
- The evaluation of ten LLMs and MMs across different subsets of the GeoEval benchmark reveals that the WizardMath model performs best, but struggles on harder problems.
- The findings suggest that GPT-series models are more effective on problems they have rephrased, pointing to a potential method for enhancing model capabilities.
Plain English Explanation
Large language models (LLMs) and multi-modal models (MMs) have shown impressive problem-solving abilities, but their proficiency in tackling geometry math problems has not been thoroughly tested. Geometry problems require understanding both text and visual information, which can be challenging for AI systems.
To address this gap, the researchers created the GeoEval benchmark, a collection of geometry math problems of varying difficulty levels. They then evaluated ten different LLMs and MMs on this benchmark.
The results showed that the WizardMath model performed the best overall, achieving a 55.67% accuracy rate on the main subset of the benchmark. However, its accuracy dropped to only 6% on the harder problems, suggesting that these models still struggle with more complex geometry problems.
Interestingly, the researchers found that GPT-series models tended to perform better on problems that they had rephrased or rewritten. This suggests that a strategy of having the models rephrase the problems could be a way to improve their geometry problem-solving abilities.
Overall, this research highlights the need for more comprehensive testing of LLMs and MMs on tasks that require integrating textual and visual information, such as geometry math problems. The GeoEval benchmark provides a valuable tool for this purpose.
Technical Explanation
The paper introduces the GeoEval benchmark, a comprehensive dataset designed to evaluate the performance of LLMs and MMs on geometry math problems. The benchmark includes a main subset of 2,000 problems, a 750-problem subset focused on backward reasoning, an augmented subset of 2,000 problems, and a hard subset of 300 problems.
The researchers evaluated ten LLMs and MMs, including GPT-3, GPT-J, and VisualWebBench, on these varied subsets. The results showed that the WizardMath model achieved the highest accuracy of 55.67% on the main subset, but its performance dropped to only 6.00% on the hard subset.
The findings suggest that while LLMs and MMs have made significant advancements in problem-solving, they still struggle with more complex geometry problems that require an integrated understanding of textual and visual information. The researchers also observed that GPT-series models tended to perform better on problems they had rephrased, indicating a potential method for enhancing model capabilities.
Critical Analysis
The paper provides a comprehensive evaluation of LLMs and MMs on geometry math problems, but it also acknowledges several limitations and areas for further research.
One key limitation is the relatively small size of the hard subset (300 problems) compared to the main subset (2,000 problems). It would be valuable to expand the hard subset to better understand the models' performance on the most challenging geometry problems.
Additionally, the paper does not explore the specific strategies or reasoning processes used by the different models to solve the geometry problems. Understanding these mechanisms could provide valuable insights for improving model performance.
Further research could also investigate the impact of pre-training data and model architectures on geometry problem-solving abilities. Exploring VisionGraph or other multi-modal approaches may yield additional insights on integrating textual and visual information for geometry tasks.
Overall, this research makes an important contribution to the understanding of LLM and MM capabilities in the domain of geometry math problems. The GeoEval benchmark provides a valuable tool for further exploration and advancement in this area.
Conclusion
This paper investigates the performance of large language models (LLMs) and multi-modal models (MMs) in solving geometry math problems, which require an integrated understanding of textual and visual information. The authors introduce the GeoEval benchmark, a comprehensive dataset for evaluating model capabilities in this domain.
The evaluation of ten LLMs and MMs reveals that the WizardMath model achieves the highest accuracy on the main subset of the benchmark, but struggles on more challenging problems. The findings also suggest that GPT-series models perform better on problems they have rephrased, pointing to a potential method for enhancing model capabilities.
This research highlights the need for more comprehensive testing of LLMs and MMs on tasks that require multimodal reasoning, such as geometry math problems. The GeoEval benchmark provides a valuable tool for advancing our understanding of model capabilities in this domain and driving further progress in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Advancing Geometric Problem Solving: A Comprehensive Benchmark for Multimodal Model Evaluation
Kai Sun, Yushi Bai, Ji Qi, Lei Hou, Juanzi Li
0
0
To advance the evaluation of multimodal math reasoning in large multimodal models (LMMs), this paper introduces a novel benchmark, MM-MATH. MM-MATH consists of 5,929 open-ended middle school math problems with visual contexts, with fine-grained classification across difficulty, grade level, and knowledge points. Unlike existing benchmarks relying on binary answer comparison, MM-MATH incorporates both outcome and process evaluations. Process evaluation employs LMM-as-a-judge to automatically analyze solution steps, identifying and categorizing errors into specific error types. Extensive evaluation of ten models on MM-MATH reveals significant challenges for existing LMMs, highlighting their limited utilization of visual information and struggles with higher-difficulty problems. The best-performing model achieves only 31% accuracy on MM-MATH, compared to 82% for humans. This highlights the challenging nature of our benchmark for existing models and the significant gap between the multimodal reasoning capabilities of current models and humans. Our process evaluation reveals that diagram misinterpretation is the most common error, accounting for more than half of the total error cases, underscoring the need for improved image comprehension in multimodal reasoning.
6/28/2024
Mathify: Evaluating Large Language Models on Mathematical Problem Solving Tasks
Avinash Anand, Mohit Gupta, Kritarth Prasad, Navya Singla, Sanjana Sanjeev, Jatin Kumar, Adarsh Raj Shivam, Rajiv Ratn Shah
0
0
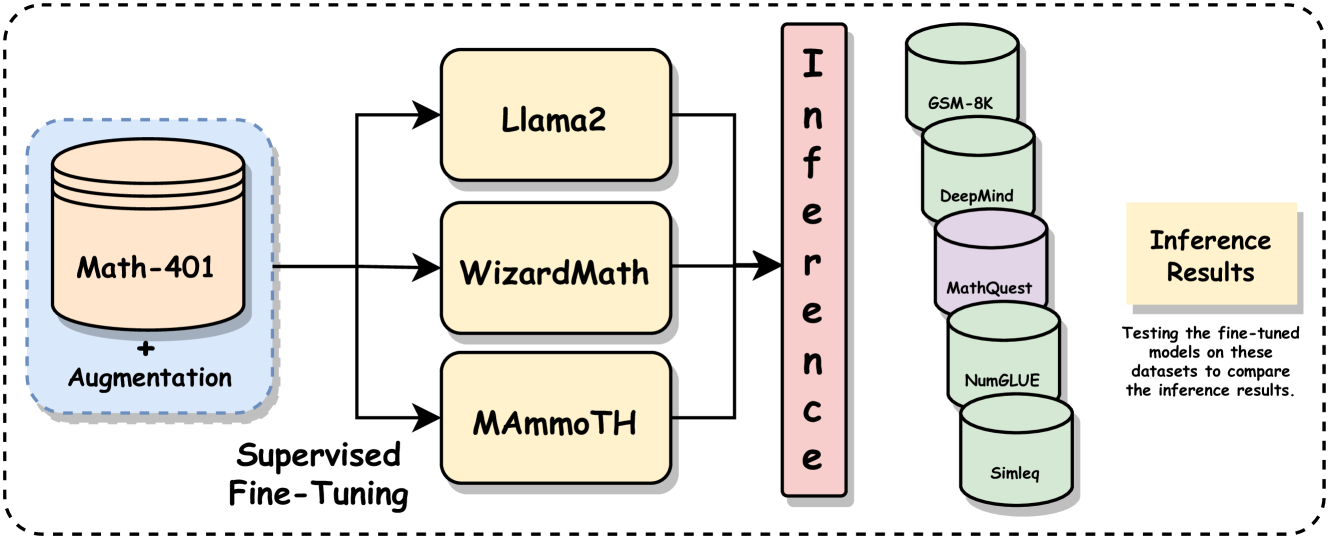
The rapid progress in the field of natural language processing (NLP) systems and the expansion of large language models (LLMs) have opened up numerous opportunities in the field of education and instructional methods. These advancements offer the potential for tailored learning experiences and immediate feedback, all delivered through accessible and cost-effective services. One notable application area for this technological advancement is in the realm of solving mathematical problems. Mathematical problem-solving not only requires the ability to decipher complex problem statements but also the skill to perform precise arithmetic calculations at each step of the problem-solving process. However, the evaluation of the arithmetic capabilities of large language models remains an area that has received relatively little attention. In response, we introduce an extensive mathematics dataset called MathQuest sourced from the 11th and 12th standard Mathematics NCERT textbooks. This dataset encompasses mathematical challenges of varying complexity and covers a wide range of mathematical concepts. Utilizing this dataset, we conduct fine-tuning experiments with three prominent LLMs: LLaMA-2, WizardMath, and MAmmoTH. These fine-tuned models serve as benchmarks for evaluating their performance on our dataset. Our experiments reveal that among the three models, MAmmoTH-13B emerges as the most proficient, achieving the highest level of competence in solving the presented mathematical problems. Consequently, MAmmoTH-13B establishes itself as a robust and dependable benchmark for addressing NCERT mathematics problems.
4/23/2024

LLMs Are Not Intelligent Thinkers: Introducing Mathematical Topic Tree Benchmark for Comprehensive Evaluation of LLMs
Arash Gholami Davoodi, Seyed Pouyan Mousavi Davoudi, Pouya Pezeshkpour
0
0
Large language models (LLMs) demonstrate impressive capabilities in mathematical reasoning. However, despite these achievements, current evaluations are mostly limited to specific mathematical topics, and it remains unclear whether LLMs are genuinely engaging in reasoning. To address these gaps, we present the Mathematical Topics Tree (MaTT) benchmark, a challenging and structured benchmark that offers 1,958 questions across a wide array of mathematical subjects, each paired with a detailed hierarchical chain of topics. Upon assessing different LLMs using the MaTT benchmark, we find that the most advanced model, GPT-4, achieved a mere 54% accuracy in a multiple-choice scenario. Interestingly, even when employing Chain-of-Thought prompting, we observe mostly no notable improvement. Moreover, LLMs accuracy dramatically reduced by up to 24.2 percentage point when the questions were presented without providing choices. Further detailed analysis of the LLMs' performance across a range of topics showed significant discrepancy even for closely related subtopics within the same general mathematical area. In an effort to pinpoint the reasons behind LLMs performances, we conducted a manual evaluation of the completeness and correctness of the explanations generated by GPT-4 when choices were available. Surprisingly, we find that in only 53.3% of the instances where the model provided a correct answer, the accompanying explanations were deemed complete and accurate, i.e., the model engaged in genuine reasoning.
6/11/2024

MARIO Eval: Evaluate Your Math LLM with your Math LLM--A mathematical dataset evaluation toolkit
Boning Zhang, Chengxi Li, Kai Fan
0
0
Large language models (LLMs) have been explored in a variety of reasoning tasks including solving of mathematical problems. Each math dataset typically includes its own specially designed evaluation script, which, while suitable for its intended use, lacks generalizability across different datasets. Consequently, updates and adaptations to these evaluation tools tend to occur without being systematically reported, leading to inconsistencies and obstacles to fair comparison across studies. To bridge this gap, we introduce a comprehensive mathematical evaluation toolkit that not only utilizes a python computer algebra system (CAS) for its numerical accuracy, but also integrates an optional LLM, known for its considerable natural language processing capabilities. To validate the effectiveness of our toolkit, we manually annotated two distinct datasets. Our experiments demonstrate that the toolkit yields more robust evaluation results compared to prior works, even without an LLM. Furthermore, when an LLM is incorporated, there is a notable enhancement. The code for our method will be made available at url{https://github.com/MARIO-Math-Reasoning/math_evaluation}.
4/23/2024