Mask-guided cross-image attention for zero-shot in-silico histopathologic image generation with a diffusion model

0

Sign in to get full access
Overview
- This paper presents a novel diffusion model-based approach for zero-shot in-silico histopathologic image generation.
- The key idea is to use a "mask-guided cross-image attention" mechanism to enable the diffusion model to generate target images based on a reference image and a segmentation mask.
- This allows the model to generate diverse, anatomically-plausible histopathologic images without the need for paired training data.
Plain English Explanation
The researchers have developed a new way to generate artificial medical images, specifically histopathologic images, using a diffusion model. Diffusion models are a type of AI model that can create new images by learning from existing ones.
The novel aspect of this work is the "mask-guided cross-image attention" mechanism. This allows the diffusion model to generate a target image by looking at a reference image and a segmentation mask. The segmentation mask tells the model which parts of the reference image to focus on.
This "zero-shot" approach means the model can generate new histopathologic images without needing a large dataset of paired training images. It can essentially learn to create new images on the fly, just by looking at a reference image and a mask.
This is significant because acquiring large, diverse datasets of medical images can be very challenging. The ability to generate synthetic yet realistic medical images could be very helpful for tasks like medical image segmentation and disease diagnosis.
Technical Explanation
The core of the proposed approach is a diffusion model that can generate target histopathologic images conditioned on a reference image and a segmentation mask. The segmentation mask guides the diffusion process, allowing the model to focus on generating the desired anatomical structures.
Specifically, the model uses a "mask-guided cross-image attention" mechanism to attend to relevant regions of the reference image when generating the target image. This cross-image attention enables the model to learn the necessary spatial and semantic relationships between the reference image and the target, without requiring paired training data.
The researchers evaluate their approach on the task of generating diverse, anatomically-plausible histopathologic images of the prostate gland. They show that their method can generate visually compelling images that capture the relevant histological structures, even when the reference image and target image come from different anatomical locations.
Critical Analysis
The researchers acknowledge that their approach has some limitations. For example, the generated images may not fully capture the nuanced visual characteristics of real histopathologic samples, as the model is limited by the reference images and segmentation masks provided.
Additionally, the researchers note that their approach currently requires the reference image and target image to come from the same broad anatomical region (e.g., prostate). Extending the method to generate images of completely different anatomical structures would likely require additional architectural modifications or a larger and more diverse dataset of reference images.
While the results are promising, further research is needed to fully understand the capabilities and limitations of this mask-guided diffusion-based approach for zero-shot medical image generation. Potential areas for future work include expanding the model to handle more diverse anatomical regions, improving the realism and fidelity of the generated images, and [exploring applications in downstream tasks like medical image segmentation and disease diagnosis.
Conclusion
This paper presents a novel diffusion model-based approach for zero-shot in-silico histopathologic image generation. The key innovation is the use of a "mask-guided cross-image attention" mechanism, which allows the model to generate target images based on a reference image and a segmentation mask, without requiring paired training data.
The ability to generate diverse, anatomically-plausible medical images without large datasets could have significant implications for tasks like medical image analysis and disease diagnosis. While the current approach has some limitations, the researchers have demonstrated the potential of this mask-guided diffusion-based framework for zero-shot medical image generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mask-guided cross-image attention for zero-shot in-silico histopathologic image generation with a diffusion model
Dominik Winter, Nicolas Triltsch, Marco Rosati, Anatoliy Shumilov, Ziya Kokaragac, Yuri Popov, Thomas Padel, Laura Sebastian Monasor, Ross Hill, Markus Schick, Nicolas Brieu
Creating in-silico data with generative AI promises a cost-effective alternative to staining, imaging, and annotating whole slide images in computational pathology. Diffusion models are the state-of-the-art solution for generating in-silico images, offering unparalleled fidelity and realism. Using appearance transfer diffusion models allows for zero-shot image generation, facilitating fast application and making model training unnecessary. However current appearance transfer diffusion models are designed for natural images, where the main task is to transfer the foreground object from an origin to a target domain, while the background is of insignificant importance. In computational pathology, specifically in oncology, it is however not straightforward to define which objects in an image should be classified as foreground and background, as all objects in an image may be of critical importance for the detailed understanding the tumor micro-environment. We contribute to the applicability of appearance transfer diffusion models to immunohistochemistry-stained images by modifying the appearance transfer guidance to alternate between class-specific AdaIN feature statistics matchings using existing segmentation masks. The performance of the proposed method is demonstrated on the downstream task of supervised epithelium segmentation, showing that the number of manual annotations required for model training can be reduced by 75%, outperforming the baseline approach. Additionally, we consulted with a certified pathologist to investigate future improvements. We anticipate this work to inspire the application of zero-shot diffusion models in computational pathology, providing an efficient method to generate in-silico images with unmatched fidelity and realism, which prove meaningful for downstream tasks, such as training existing deep learning models or finetuning foundation models.
Read more7/17/2024
🖼️
0
GenSelfDiff-HIS: Generative Self-Supervision Using Diffusion for Histopathological Image Segmentation
Vishnuvardhan Purma, Suhas Srinath, Seshan Srirangarajan, Aanchal Kakkar, Prathosh A. P
Histopathological image segmentation is a laborious and time-intensive task, often requiring analysis from experienced pathologists for accurate examinations. To reduce this burden, supervised machine-learning approaches have been adopted using large-scale annotated datasets for histopathological image analysis. However, in several scenarios, the availability of large-scale annotated data is a bottleneck while training such models. Self-supervised learning (SSL) is an alternative paradigm that provides some respite by constructing models utilizing only the unannotated data which is often abundant. The basic idea of SSL is to train a network to perform one or many pseudo or pretext tasks on unannotated data and use it subsequently as the basis for a variety of downstream tasks. It is seen that the success of SSL depends critically on the considered pretext task. While there have been many efforts in designing pretext tasks for classification problems, there haven't been many attempts on SSL for histopathological segmentation. Motivated by this, we propose an SSL approach for segmenting histopathological images via generative diffusion models in this paper. Our method is based on the observation that diffusion models effectively solve an image-to-image translation task akin to a segmentation task. Hence, we propose generative diffusion as the pretext task for histopathological image segmentation. We also propose a multi-loss function-based fine-tuning for the downstream task. We validate our method using several metrics on two publically available datasets along with a newly proposed head and neck (HN) cancer dataset containing hematoxylin and eosin (H&E) stained images along with annotations. Codes will be made public at https://github.com/suhas-srinath/GenSelfDiff-HIS.
Read more9/12/2024

0
Diffusion based Zero-shot Medical Image-to-Image Translation for Cross Modality Segmentation
Zihao Wang, Yingyu Yang, Yuzhou Chen, Tingting Yuan, Maxime Sermesant, Herve Delingette, Ona Wu
Cross-modality image segmentation aims to segment the target modalities using a method designed in the source modality. Deep generative models can translate the target modality images into the source modality, thus enabling cross-modality segmentation. However, a vast body of existing cross-modality image translation methods relies on supervised learning. In this work, we aim to address the challenge of zero-shot learning-based image translation tasks (extreme scenarios in the target modality is unseen in the training phase). To leverage generative learning for zero-shot cross-modality image segmentation, we propose a novel unsupervised image translation method. The framework learns to translate the unseen source image to the target modality for image segmentation by leveraging the inherent statistical consistency between different modalities for diffusion guidance. Our framework captures identical cross-modality features in the statistical domain, offering diffusion guidance without relying on direct mappings between the source and target domains. This advantage allows our method to adapt to changing source domains without the need for retraining, making it highly practical when sufficient labeled source domain data is not available. The proposed framework is validated in zero-shot cross-modality image segmentation tasks through empirical comparisons with influential generative models, including adversarial-based and diffusion-based models.
Read more4/11/2024
0
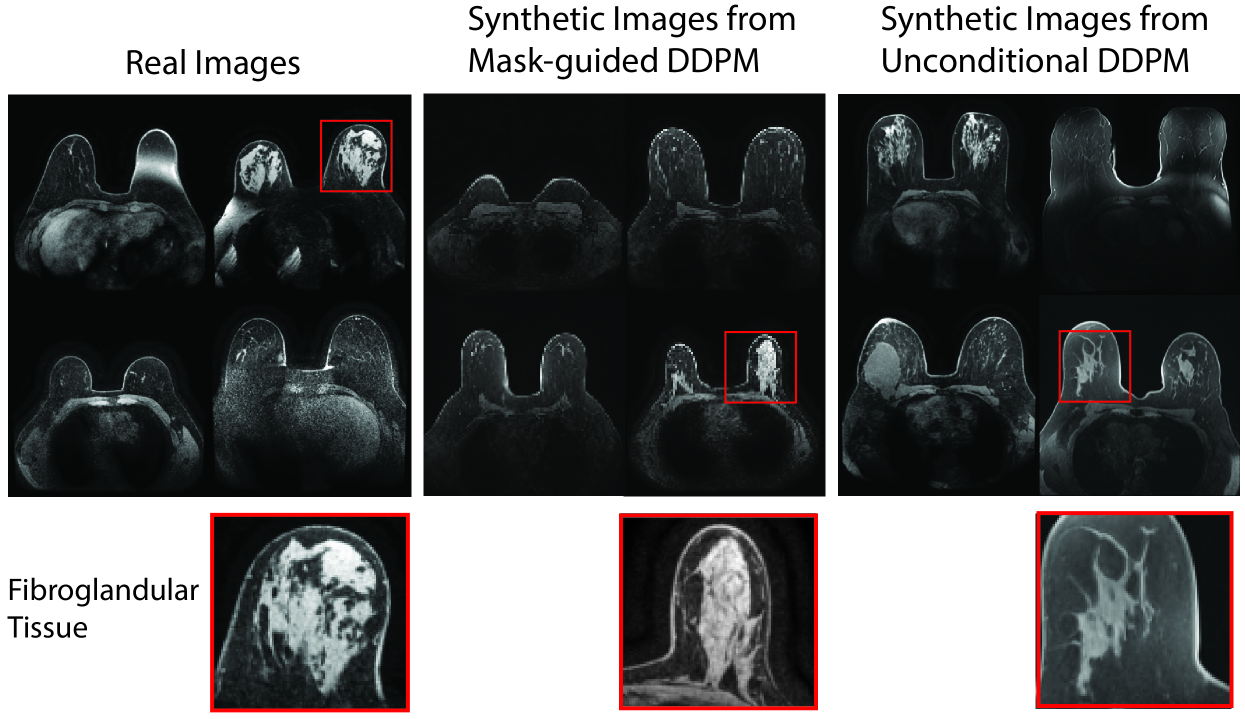
Anatomically-Controllable Medical Image Generation with Segmentation-Guided Diffusion Models
Nicholas Konz, Yuwen Chen, Haoyu Dong, Maciej A. Mazurowski
Diffusion models have enabled remarkably high-quality medical image generation, yet it is challenging to enforce anatomical constraints in generated images. To this end, we propose a diffusion model-based method that supports anatomically-controllable medical image generation, by following a multi-class anatomical segmentation mask at each sampling step. We additionally introduce a random mask ablation training algorithm to enable conditioning on a selected combination of anatomical constraints while allowing flexibility in other anatomical areas. We compare our method (SegGuidedDiff) to existing methods on breast MRI and abdominal/neck-to-pelvis CT datasets with a wide range of anatomical objects. Results show that our method reaches a new state-of-the-art in the faithfulness of generated images to input anatomical masks on both datasets, and is on par for general anatomical realism. Finally, our model also enjoys the extra benefit of being able to adjust the anatomical similarity of generated images to real images of choice through interpolation in its latent space. SegGuidedDiff has many applications, including cross-modality translation, and the generation of paired or counterfactual data. Our code is available at https://github.com/mazurowski-lab/segmentation-guided-diffusion.
Read more6/21/2024