Search-Adaptor: Embedding Customization for Information Retrieval

0

Sign in to get full access
Overview
- The paper introduces "Search-Adaptor," a method for customizing text embeddings to improve information retrieval performance.
- It addresses the challenge of adapting pre-trained language models to specific search domains or tasks.
- The proposed approach aims to enhance the relevance and accuracy of search results by fine-tuning the text embeddings.
Plain English Explanation
Search-Adaptor is a technique that helps improve the performance of search engines and information retrieval systems. These systems often use pre-trained language models, which are trained on a large amount of general text data, to understand and process the text. However, these pre-trained models may not always be well-suited for specific search domains or tasks.
The researchers behind Search-Adaptor recognized this problem and developed a method to customize the text embeddings (the numerical representations of text) used by these language models. By fine-tuning the embeddings on a smaller, more relevant dataset, the system can better understand the specific vocabulary and context of the search domain. This leads to more accurate and relevant search results, as the system can better match the user's query to the most pertinent information.
The key idea is to strike a balance between the general knowledge captured by the pre-trained model and the specialized understanding needed for a particular search task. Search-Adaptor achieves this by incorporating a novel "adaptor" module that can be inserted into the language model, allowing for efficient fine-tuning without completely retraining the entire model.
Technical Explanation
Search-Adaptor is a method for customizing text embeddings to improve the performance of information retrieval (IR) systems. The researchers recognized that pre-trained language models, while powerful, may not always be well-suited for specific search tasks or domains.
To address this, they proposed an "adaptor" module that can be inserted into the language model architecture. This adaptor allows for efficient fine-tuning of the text embeddings on a smaller, more relevant dataset, without the need to retrain the entire model from scratch.
The adaptor module consists of a series of transformation layers that are applied to the input text embeddings. These layers learn to adjust the embeddings in a way that better captures the semantics and vocabulary of the target search domain. By fine-tuning the adaptor, the researchers were able to improve the relevance and accuracy of the search results, as the system could better match the user's query to the most pertinent information.
The researchers evaluated the Search-Adaptor approach on several IR benchmarks and found that it outperformed both the original pre-trained language model and other fine-tuning approaches. The adaptors were able to capture domain-specific information while still leveraging the general knowledge learned by the pre-trained model.
Critical Analysis
The Search-Adaptor paper presents a promising approach for improving information retrieval systems, but it also acknowledges several limitations and areas for further research.
One potential concern is the scalability of the approach, as fine-tuning the adaptor module may become computationally expensive as the size of the target dataset or the complexity of the search domain increases. The researchers suggest that further exploration of more efficient fine-tuning techniques could help address this challenge.
Additionally, the paper focuses on improving the relevance and accuracy of search results, but it does not extensively explore other important IR metrics, such as diversity or user satisfaction. Further research could investigate how the Search-Adaptor approach impacts these other aspects of information retrieval performance.
Finally, the researchers note that the effectiveness of the adaptor module may depend on the quality and characteristics of the fine-tuning dataset. Exploring strategies for curating or generating suitable datasets for different search domains could be a valuable area of future work.
Conclusion
Search-Adaptor presents a novel and promising approach for customizing text embeddings to improve the performance of information retrieval systems. By incorporating an "adaptor" module that can be efficiently fine-tuned on relevant data, the method enables language models to better capture the semantics and vocabulary of specific search domains.
The results demonstrate that this technique can lead to more relevant and accurate search results, which could have significant implications for a wide range of applications, from enterprise search to e-commerce product discovery. As the researchers continue to explore ways to address the limitations and expand the capabilities of Search-Adaptor, it has the potential to become a valuable tool for enhancing the effectiveness of information retrieval systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Search-Adaptor: Embedding Customization for Information Retrieval
Jinsung Yoon, Sercan O Arik, Yanfei Chen, Tomas Pfister
Embeddings extracted by pre-trained Large Language Models (LLMs) have significant potential to improve information retrieval and search. Beyond the zero-shot setup in which they are being conventionally used, being able to take advantage of the information from the relevant query-corpus paired data can further boost the LLM capabilities. In this paper, we propose a novel method, Search-Adaptor, for customizing LLMs for information retrieval in an efficient and robust way. Search-Adaptor modifies the embeddings generated by pre-trained LLMs, and can be integrated with any LLM, including those only available via prediction APIs. On multiple English, multilingual, and multimodal retrieval datasets, we show consistent and significant performance benefits for Search-Adaptor -- e.g., more than 5% improvements for Google Embedding APIs in nDCG@10 averaged over 14 BEIR datasets.
Read more8/26/2024
0
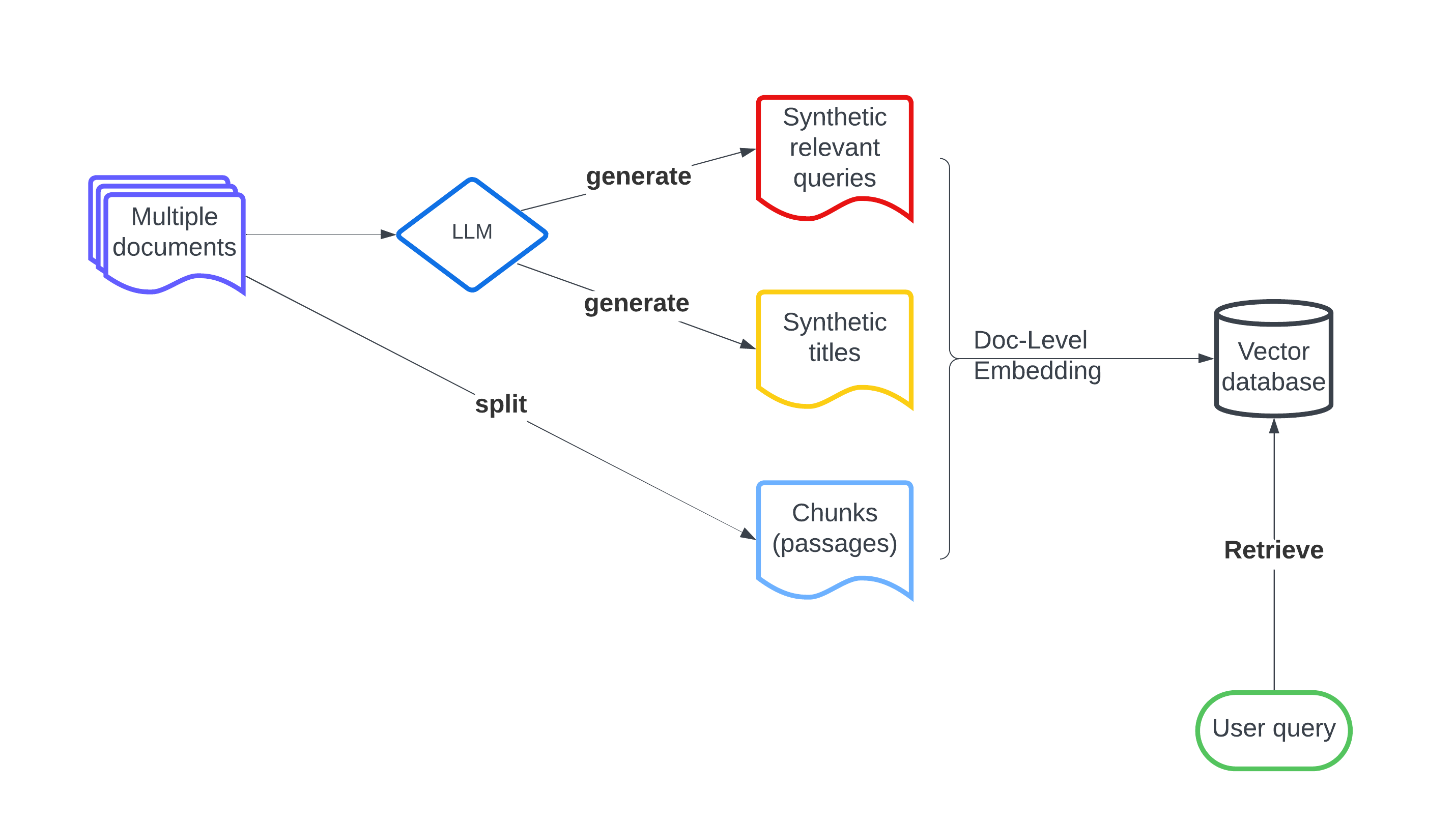
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
Read more4/10/2024

131
Matryoshka-Adaptor: Unsupervised and Supervised Tuning for Smaller Embedding Dimensions
Jinsung Yoon, Raj Sinha, Sercan O Arik, Tomas Pfister
Embeddings from Large Language Models (LLMs) have emerged as critical components in various applications, particularly for information retrieval. While high-dimensional embeddings generally demonstrate superior performance as they contain more salient information, their practical application is frequently hindered by elevated computational latency and the associated higher cost. To address these challenges, we propose Matryoshka-Adaptor, a novel tuning framework designed for the customization of LLM embeddings. Matryoshka-Adaptor facilitates substantial dimensionality reduction while maintaining comparable performance levels, thereby achieving a significant enhancement in computational efficiency and cost-effectiveness. Our framework directly modifies the embeddings from pre-trained LLMs which is designed to be seamlessly integrated with any LLM architecture, encompassing those accessible exclusively through black-box APIs. Also, it exhibits efficacy in both unsupervised and supervised learning settings. A rigorous evaluation conducted across a diverse corpus of English, multilingual, and multimodal datasets consistently reveals substantial gains with Matryoshka-Adaptor. Notably, with Google and OpenAI Embedding APIs, Matryoshka-Adaptor achieves a reduction in dimensionality ranging from two- to twelve-fold without compromising performance across multiple BEIR datasets.
Read more7/31/2024

0
Adapting Multilingual LLMs to Low-Resource Languages with Knowledge Graphs via Adapters
Daniil Gurgurov, Mareike Hartmann, Simon Ostermann
This paper explores the integration of graph knowledge from linguistic ontologies into multilingual Large Language Models (LLMs) using adapters to improve performance for low-resource languages (LRLs) in sentiment analysis (SA) and named entity recognition (NER). Building upon successful parameter-efficient fine-tuning techniques, such as K-ADAPTER and MAD-X, we propose a similar approach for incorporating knowledge from multilingual graphs, connecting concepts in various languages with each other through linguistic relationships, into multilingual LLMs for LRLs. Specifically, we focus on eight LRLs -- Maltese, Bulgarian, Indonesian, Nepali, Javanese, Uyghur, Tibetan, and Sinhala -- and employ language-specific adapters fine-tuned on data extracted from the language-specific section of ConceptNet, aiming to enable knowledge transfer across the languages covered by the knowledge graph. We compare various fine-tuning objectives, including standard Masked Language Modeling (MLM), MLM with full-word masking, and MLM with targeted masking, to analyse their effectiveness in learning and integrating the extracted graph data. Through empirical evaluation on language-specific tasks, we assess how structured graph knowledge affects the performance of multilingual LLMs for LRLs in SA and NER, providing insights into the potential benefits of adapting language models for low-resource scenarios.
Read more7/24/2024