Matryoshka Query Transformer for Large Vision-Language Models

0
Sign in to get full access
Overview
- Presents a new approach called the Matryoshka Query Transformer for improving the performance of large vision-language models on various tasks
- Focuses on enhancing the ability of these models to understand and respond to queries about images
- Introduces a novel query transformer architecture that can capture the hierarchical structure of queries and integrate it into the model's reasoning process
Plain English Explanation
The paper introduces the Matryoshka Query Transformer, a new technique for improving the performance of large vision-language models on tasks that involve understanding and responding to queries about images. These models, such as DALL-E and LLaVa, are powerful but can struggle with complex queries that require understanding the hierarchical structure of the question.
The key idea behind the Matryoshka Query Transformer is to explicitly model this hierarchical structure, just like the Russian nesting dolls (matryoshka) that inspired the name. By breaking down the query into smaller, more manageable pieces, the model can better grasp the relationships between different parts of the question and use this understanding to provide more accurate and relevant responses.
Technical Explanation
The Matryoshka Query Transformer works by first encoding the input query into a hierarchical representation, with each level of the hierarchy corresponding to a different level of abstraction or detail in the query. This hierarchical representation is then used to guide the model's attention mechanism, allowing it to focus on the most relevant parts of the image when generating a response.
The authors evaluate the Matryoshka Query Transformer on a range of vision-language tasks, including image captioning, visual question answering, and visual reasoning. Their results show that the new architecture outperforms standard transformer-based models, particularly on more complex queries that require a deeper understanding of the hierarchical structure of the question.
Critical Analysis
The Matryoshka Query Transformer presents a promising approach for enhancing the performance of large vision-language models, but it is important to consider its limitations and potential areas for further research.
One potential concern is the complexity of the model, which may make it more computationally intensive and difficult to deploy in real-world applications. The authors do not provide a detailed analysis of the model's computational requirements or inference speed, which would be important for understanding its practical feasibility.
Additionally, the paper focuses primarily on evaluating the model's performance on standard benchmark tasks, but it would be valuable to understand how it performs in more realistic, open-ended scenarios where the queries and image-text relationships may be more complex and diverse.
Conclusion
The Matryoshka Query Transformer presents a novel approach to improving the performance of large vision-language models, with a focus on enhancing their ability to understand and respond to complex queries about images. By explicitly modeling the hierarchical structure of queries, the model can better capture the relationships between different parts of the question and use this understanding to provide more accurate and relevant responses.
While the paper demonstrates promising results on standard benchmark tasks, further research is needed to explore the model's practical feasibility and performance in more realistic, open-ended scenarios. As large vision-language models continue to play an increasingly important role in a wide range of applications, the Matryoshka Query Transformer and similar techniques may prove valuable in advancing the state of the art in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Matryoshka Query Transformer for Large Vision-Language Models
Wenbo Hu, Zi-Yi Dou, Liunian Harold Li, Amita Kamath, Nanyun Peng, Kai-Wei Chang
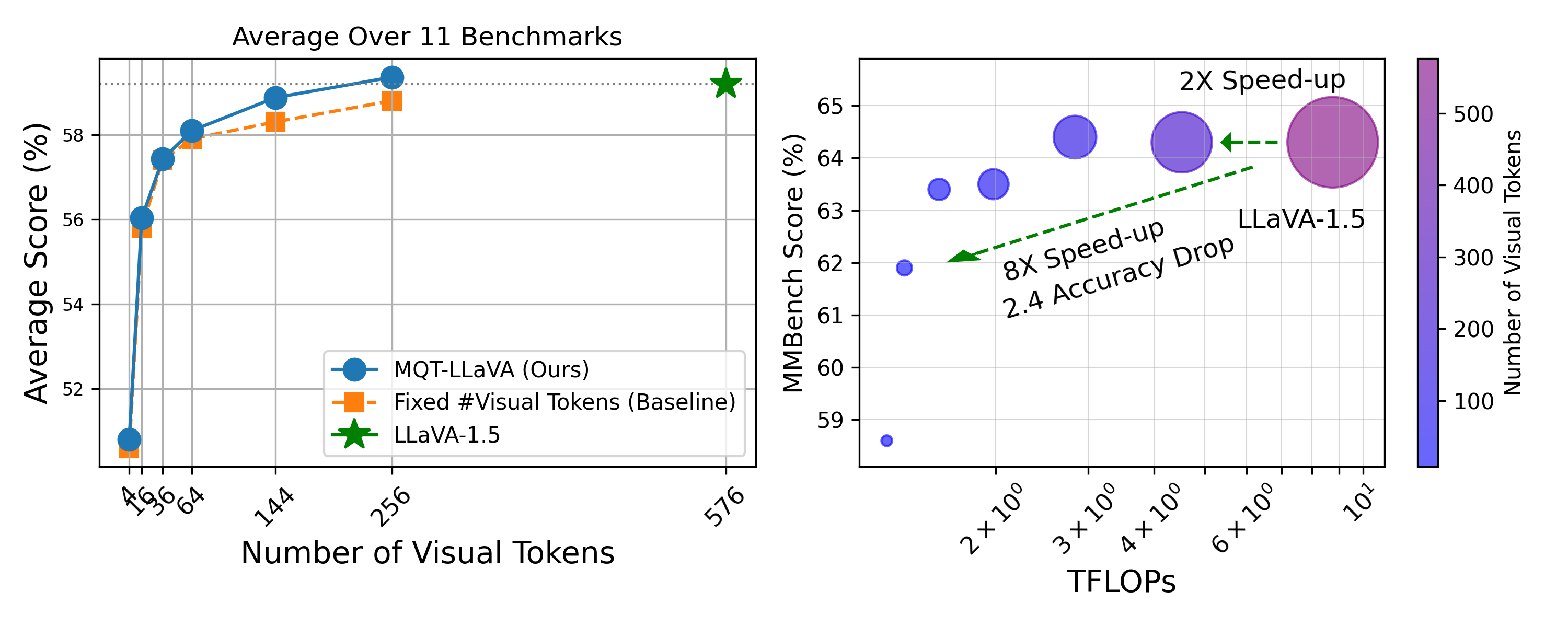
Large Vision-Language Models (LVLMs) typically encode an image into a fixed number of visual tokens (e.g., 576) and process these tokens with a language model. Despite their strong performance, LVLMs face challenges in adapting to varying computational constraints. This raises the question: can we achieve flexibility in the number of visual tokens to suit different tasks and computational resources? We answer this with an emphatic yes. Inspired by Matryoshka Representation Learning, we introduce the Matryoshka Query Transformer (MQT), capable of encoding an image into m visual tokens during inference, where m can be any number up to a predefined maximum. This is achieved by employing a query transformer with M latent query tokens to compress the visual embeddings. During each training step, we randomly select m <= M latent query tokens and train the model using only these first m tokens, discarding the rest. Combining MQT with LLaVA, we train a single model once, and flexibly and drastically reduce the number of inference-time visual tokens while maintaining similar or better performance compared to training independent models for each number of tokens. Our model, MQT-LLAVA, matches LLaVA-1.5 performance across 11 benchmarks using a maximum of 256 tokens instead of LLaVA's fixed 576. Reducing to 16 tokens (8x less TFLOPs) only sacrifices the performance by 2.4 points on MMBench. On certain tasks such as ScienceQA and MMMU, we can even go down to only 2 visual tokens with performance drops of just 3% and 6% each. Our exploration of the trade-off between the accuracy and computational cost brought about by the number of visual tokens facilitates future research to achieve the best of both worlds.
Read more6/10/2024

0
Matryoshka Multimodal Models
Mu Cai, Jianwei Yang, Jianfeng Gao, Yong Jae Lee
Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency. While token pruning/merging methods do exist, they produce a single length output for each image and do not afford flexibility in trading off information density v.s. efficiency. Inspired by the concept of Matryoshka Dolls, we propose M3: Matryoshka Multimodal Models, which learns to represent visual content as nested sets of visual tokens that capture information across multiple coarse-to-fine granularities. Our approach offers several unique benefits for LMMs: (1) One can explicitly control the visual granularity per test instance during inference, e.g. , adjusting the number of tokens used to represent an image based on the anticipated complexity or simplicity of the content; (2) M3 provides a framework for analyzing the granularity needed for existing datasets, where we find that COCO-style benchmarks only need around ~9 visual tokens to obtain accuracy similar to that of using all 576 tokens; (3) Our approach provides a foundation to explore the best trade-off between performance and visual token length at sample level, where our investigation reveals that a large gap exists between the oracle upper bound and current fixed-scale representations.
Read more7/30/2024

0
VideoLLM-MoD: Efficient Video-Language Streaming with Mixture-of-Depths Vision Computation
Shiwei Wu, Joya Chen, Kevin Qinghong Lin, Qimeng Wang, Yan Gao, Qianli Xu, Tong Xu, Yao Hu, Enhong Chen, Mike Zheng Shou
A well-known dilemma in large vision-language models (e.g., GPT-4, LLaVA) is that while increasing the number of vision tokens generally enhances visual understanding, it also significantly raises memory and computational costs, especially in long-term, dense video frame streaming scenarios. Although learnable approaches like Q-Former and Perceiver Resampler have been developed to reduce the vision token burden, they overlook the context causally modeled by LLMs (i.e., key-value cache), potentially leading to missed visual cues when addressing user queries. In this paper, we introduce a novel approach to reduce vision compute by leveraging redundant vision tokens skipping layers rather than decreasing the number of vision tokens. Our method, VideoLLM-MoD, is inspired by mixture-of-depths LLMs and addresses the challenge of numerous vision tokens in long-term or streaming video. Specifically, for each transformer layer, we learn to skip the computation for a high proportion (e.g., 80%) of vision tokens, passing them directly to the next layer. This approach significantly enhances model efficiency, achieving approximately textasciitilde42% time and textasciitilde30% memory savings for the entire training. Moreover, our method reduces the computation in the context and avoid decreasing the vision tokens, thus preserving or even improving performance compared to the vanilla model. We conduct extensive experiments to demonstrate the effectiveness of VideoLLM-MoD, showing its state-of-the-art results on multiple benchmarks, including narration, forecasting, and summarization tasks in COIN, Ego4D, and Ego-Exo4D datasets.
Read more8/30/2024
🖼️
0
Enhancing Interactive Image Retrieval With Query Rewriting Using Large Language Models and Vision Language Models
Hongyi Zhu, Jia-Hong Huang, Stevan Rudinac, Evangelos Kanoulas
Image search stands as a pivotal task in multimedia and computer vision, finding applications across diverse domains, ranging from internet search to medical diagnostics. Conventional image search systems operate by accepting textual or visual queries, retrieving the top-relevant candidate results from the database. However, prevalent methods often rely on single-turn procedures, introducing potential inaccuracies and limited recall. These methods also face the challenges, such as vocabulary mismatch and the semantic gap, constraining their overall effectiveness. To address these issues, we propose an interactive image retrieval system capable of refining queries based on user relevance feedback in a multi-turn setting. This system incorporates a vision language model (VLM) based image captioner to enhance the quality of text-based queries, resulting in more informative queries with each iteration. Moreover, we introduce a large language model (LLM) based denoiser to refine text-based query expansions, mitigating inaccuracies in image descriptions generated by captioning models. To evaluate our system, we curate a new dataset by adapting the MSR-VTT video retrieval dataset to the image retrieval task, offering multiple relevant ground truth images for each query. Through comprehensive experiments, we validate the effectiveness of our proposed system against baseline methods, achieving state-of-the-art performance with a notable 10% improvement in terms of recall. Our contributions encompass the development of an innovative interactive image retrieval system, the integration of an LLM-based denoiser, the curation of a meticulously designed evaluation dataset, and thorough experimental validation.
Read more4/30/2024