The Max-Min Formulation of Multi-Objective Reinforcement Learning: From Theory to a Model-Free Algorithm
2406.07826
0
0
Abstract
In this paper, we consider multi-objective reinforcement learning, which arises in many real-world problems with multiple optimization goals. We approach the problem with a max-min framework focusing on fairness among the multiple goals and develop a relevant theory and a practical model-free algorithm under the max-min framework. The developed theory provides a theoretical advance in multi-objective reinforcement learning, and the proposed algorithm demonstrates a notable performance improvement over existing baseline methods.
Create account to get full access
Overview
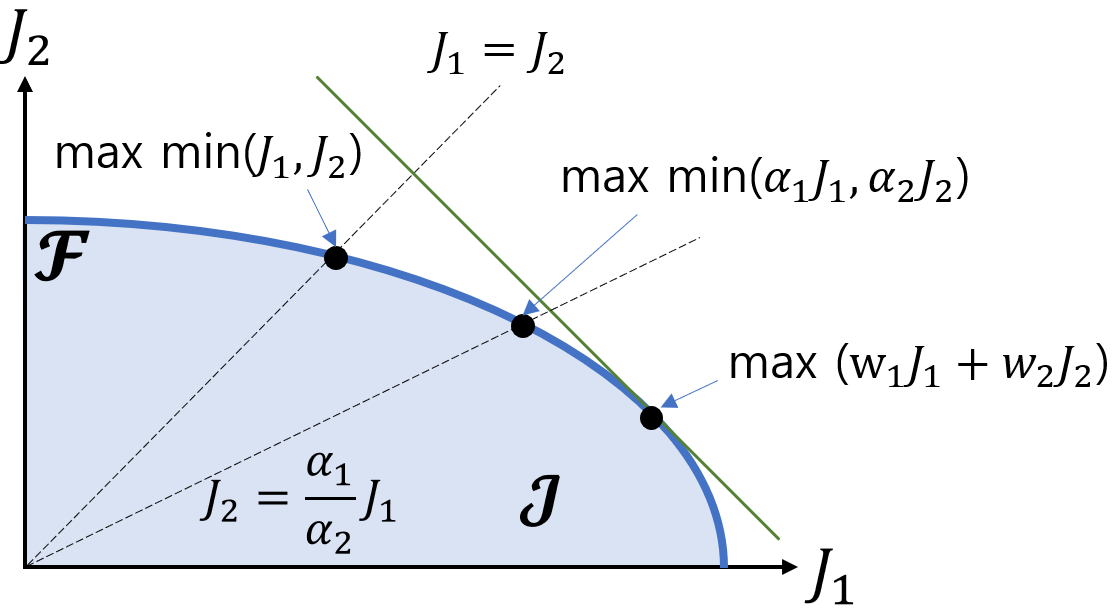
- The paper presents a new formulation of multi-objective reinforcement learning (MORL) based on the max-min optimization problem.
- The authors show how this formulation can be solved using linear programming, leading to a model-free algorithm for MORL.
- The algorithm is designed to find a policy that maximizes the minimum expected return across multiple objectives, rather than seeking a single optimal policy.
Plain English Explanation
In reinforcement learning, an agent tries to learn the best actions to take in an environment in order to maximize some reward. When there are multiple, potentially conflicting objectives that the agent needs to balance, this becomes a multi-objective reinforcement learning (MORL) problem.
The traditional approach to MORL is to try to find a single optimal policy that balances the different objectives as best as possible. However, this can be challenging, as it may not be possible to perfectly optimize all objectives simultaneously.
This paper proposes a different approach, where instead of trying to find a single optimal policy, the goal is to find a policy that maximizes the minimum expected reward across all objectives. In other words, the aim is to find a policy that performs reasonably well on all objectives, rather than one that excels at some but performs poorly on others.
The authors show that this "max-min" formulation of MORL can be solved using linear programming, which is a well-understood mathematical technique. This leads to a model-free algorithm that can be used to solve MORL problems without requiring a detailed model of the environment.
The key advantage of this approach is that it can find a policy that provides a good balance across multiple objectives, rather than trying to optimize a single objective at the expense of others. This can be particularly useful in real-world scenarios where there are often multiple, potentially conflicting goals that need to be taken into account.
Technical Explanation
The paper presents a new formulation of multi-objective reinforcement learning (MORL) based on the max-min optimization problem. In traditional MORL, the goal is to find a single policy that balances multiple, potentially conflicting objectives. In contrast, the authors' max-min formulation aims to find a policy that maximizes the minimum expected return across all objectives.
The authors show that this max-min formulation can be solved using linear programming. Specifically, they demonstrate how value iteration, a widely used algorithm in reinforcement learning, can be cast as a linear program. This allows them to develop a model-free algorithm for solving the max-min MORL problem, which does not require a detailed model of the environment.
The key technical insight is that the max-min MORL problem can be reformulated as a linear program by introducing additional variables and constraints. This linear program can then be solved using standard optimization techniques, leading to a policy that provides a good balance across multiple objectives.
The authors evaluate their algorithm on several benchmark MORL problems and show that it outperforms traditional MORL approaches in terms of finding policies that perform well across all objectives. They also provide theoretical guarantees on the optimality of the resulting policies.
Critical Analysis
The paper presents a novel and interesting approach to multi-objective reinforcement learning, with a strong theoretical foundation and empirical results to support its effectiveness. However, there are a few potential limitations and areas for further research that could be explored:
-
Scalability: While the linear programming formulation allows for the efficient solution of the max-min MORL problem, the computational complexity may still be a concern, especially for large-scale problems. Further work may be needed to improve the scalability of the algorithm.
-
Exploration-Exploitation Tradeoff: The paper focuses on the optimization problem, but does not explicitly address the exploration-exploitation tradeoff that is a central challenge in reinforcement learning. Incorporating effective exploration strategies into the max-min MORL framework could be an interesting direction for future research.
-
Robustness to Uncertainty: In real-world applications, there may be significant uncertainty in the reward functions or the environment dynamics. It would be valuable to investigate the robustness of the max-min MORL approach to such uncertainties.
-
Connections to Other MORL Frameworks: The paper could benefit from a more thorough discussion of how the max-min formulation relates to other MORL frameworks, such as Safe and Balanced Constrained Multi-Objective Reinforcement Learning, Demonstration-Guided Multi-Objective Reinforcement Learning, or A Pontryagin Perspective on Reinforcement Learning. Exploring these connections could lead to further insights and synergies.
Overall, the paper presents a compelling and theoretically grounded approach to multi-objective reinforcement learning, and the authors have made a valuable contribution to the field. The max-min formulation and the associated model-free algorithm are a promising step forward in addressing the challenges of MORL.
Conclusion
This paper introduces a novel formulation of multi-objective reinforcement learning (MORL) based on the max-min optimization problem. The authors show how this formulation can be solved using linear programming, leading to a model-free algorithm for MORL.
The key advantage of this approach is that it can find a policy that provides a good balance across multiple objectives, rather than trying to optimize a single objective at the expense of others. This can be particularly useful in real-world scenarios where there are often multiple, potentially conflicting goals that need to be taken into account.
While the paper presents promising results and a strong theoretical foundation, there are also some potential limitations and areas for further research, such as scalability, exploration-exploitation tradeoffs, and robustness to uncertainty. Exploring these aspects could lead to further advancements in the field of multi-objective reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
Constrained Reinforcement Learning with Average Reward Objective: Model-Based and Model-Free Algorithms
Vaneet Aggarwal, Washim Uddin Mondal, Qinbo Bai
0
0
Reinforcement Learning (RL) serves as a versatile framework for sequential decision-making, finding applications across diverse domains such as robotics, autonomous driving, recommendation systems, supply chain optimization, biology, mechanics, and finance. The primary objective in these applications is to maximize the average reward. Real-world scenarios often necessitate adherence to specific constraints during the learning process. This monograph focuses on the exploration of various model-based and model-free approaches for Constrained RL within the context of average reward Markov Decision Processes (MDPs). The investigation commences with an examination of model-based strategies, delving into two foundational methods - optimism in the face of uncertainty and posterior sampling. Subsequently, the discussion transitions to parametrized model-free approaches, where the primal-dual policy gradient-based algorithm is explored as a solution for constrained MDPs. The monograph provides regret guarantees and analyzes constraint violation for each of the discussed setups. For the above exploration, we assume the underlying MDP to be ergodic. Further, this monograph extends its discussion to encompass results tailored for weakly communicating MDPs, thereby broadening the scope of its findings and their relevance to a wider range of practical scenarios.
6/24/2024
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
0
0
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
5/28/2024

Robust Cooperative Multi-Agent Reinforcement Learning:A Mean-Field Type Game Perspective
Muhammad Aneeq uz Zaman, Mathieu Lauri`ere, Alec Koppel, Tamer Bac{s}ar
0
0
In this paper, we study the problem of robust cooperative multi-agent reinforcement learning (RL) where a large number of cooperative agents with distributed information aim to learn policies in the presence of emph{stochastic} and emph{non-stochastic} uncertainties whose distributions are respectively known and unknown. Focusing on policy optimization that accounts for both types of uncertainties, we formulate the problem in a worst-case (minimax) framework, which is is intractable in general. Thus, we focus on the Linear Quadratic setting to derive benchmark solutions. First, since no standard theory exists for this problem due to the distributed information structure, we utilize the Mean-Field Type Game (MFTG) paradigm to establish guarantees on the solution quality in the sense of achieved Nash equilibrium of the MFTG. This in turn allows us to compare the performance against the corresponding original robust multi-agent control problem. Then, we propose a Receding-horizon Gradient Descent Ascent RL algorithm to find the MFTG Nash equilibrium and we prove a non-asymptotic rate of convergence. Finally, we provide numerical experiments to demonstrate the efficacy of our approach relative to a baseline algorithm.
6/21/2024

Demonstration Guided Multi-Objective Reinforcement Learning
Junlin Lu, Patrick Mannion, Karl Mason
0
0
Multi-objective reinforcement learning (MORL) is increasingly relevant due to its resemblance to real-world scenarios requiring trade-offs between multiple objectives. Catering to diverse user preferences, traditional reinforcement learning faces amplified challenges in MORL. To address the difficulty of training policies from scratch in MORL, we introduce demonstration-guided multi-objective reinforcement learning (DG-MORL). This novel approach utilizes prior demonstrations, aligns them with user preferences via corner weight support, and incorporates a self-evolving mechanism to refine suboptimal demonstrations. Our empirical studies demonstrate DG-MORL's superiority over existing MORL algorithms, establishing its robustness and efficacy, particularly under challenging conditions. We also provide an upper bound of the algorithm's sample complexity.
4/8/2024