Constrained Reinforcement Learning with Average Reward Objective: Model-Based and Model-Free Algorithms
2406.11481
0
0
🏅
Abstract
Reinforcement Learning (RL) serves as a versatile framework for sequential decision-making, finding applications across diverse domains such as robotics, autonomous driving, recommendation systems, supply chain optimization, biology, mechanics, and finance. The primary objective in these applications is to maximize the average reward. Real-world scenarios often necessitate adherence to specific constraints during the learning process. This monograph focuses on the exploration of various model-based and model-free approaches for Constrained RL within the context of average reward Markov Decision Processes (MDPs). The investigation commences with an examination of model-based strategies, delving into two foundational methods - optimism in the face of uncertainty and posterior sampling. Subsequently, the discussion transitions to parametrized model-free approaches, where the primal-dual policy gradient-based algorithm is explored as a solution for constrained MDPs. The monograph provides regret guarantees and analyzes constraint violation for each of the discussed setups. For the above exploration, we assume the underlying MDP to be ergodic. Further, this monograph extends its discussion to encompass results tailored for weakly communicating MDPs, thereby broadening the scope of its findings and their relevance to a wider range of practical scenarios.
Create account to get full access
Overview
- This research paper explores various model-based and model-free approaches for Constrained Reinforcement Learning (RL) within the context of average reward Markov Decision Processes (MDPs).
- The goal is to maximize the average reward while adhering to specific constraints during the learning process.
- The paper investigates two model-based strategies: optimism in the face of uncertainty and posterior sampling.
- It also examines a parametrized model-free approach using the primal-dual policy gradient-based algorithm as a solution for constrained MDPs.
- The research provides regret guarantees and analyzes constraint violation for each of the discussed setups.
- The paper assumes the underlying MDP to be ergodic and also extends the discussion to weakly communicating MDPs.
Plain English Explanation
Reinforcement learning is a powerful framework for sequential decision-making, with applications in diverse areas like robotics, autonomous driving, and finance. The primary objective in these applications is to maximize the average reward. However, real-world scenarios often require adhering to specific constraints during the learning process.
This research paper explores different approaches to address this challenge of Constrained Reinforcement Learning. The researchers focus on two main types of methods: model-based and model-free.
In the model-based approach, the paper delves into two foundational techniques: optimism in the face of uncertainty and posterior sampling. These methods try to learn the underlying model of the environment and use that knowledge to make better decisions.
On the model-free side, the researchers investigate a parametrized policy gradient-based algorithm, which can solve constrained Markov Decision Processes without explicitly modeling the environment. This is a more direct approach that doesn't require building a complete model of the problem.
The paper provides theoretical guarantees on the performance of these methods, analyzing factors like regret (the difference between the achieved reward and the optimal reward) and constraint violation. This helps understand the strengths and limitations of each approach.
Additionally, the researchers consider the case where the underlying Markov Decision Process is weakly communicating. This broadens the applicability of the findings to a wider range of real-world scenarios.
Technical Explanation
The paper focuses on average reward Markov Decision Processes (MDPs), where the goal is to maximize the average reward obtained over time, rather than the cumulative reward. This is a more realistic objective in many applications.
For the model-based approaches, the researchers investigate two main strategies:
-
Optimism in the face of uncertainty: This method maintains an optimistic estimate of the model parameters and uses that to guide the decision-making process. It helps balance exploration (learning about the environment) and exploitation (making the best decisions based on current knowledge).
-
Posterior sampling: This approach samples a model from the posterior distribution over possible models and selects actions that are optimal for the sampled model. This can lead to better exploration of the environment compared to the optimism-based method.
For the model-free approach, the paper examines a primal-dual policy gradient-based algorithm. This method directly learns a parameterized policy without explicitly modeling the environment. It uses a Lagrangian formulation to incorporate the constraints into the learning process.
The researchers provide theoretical guarantees on the performance of these methods, including regret bounds (how much the algorithm's performance differs from the optimal policy) and constraint violation bounds (how well the algorithm adheres to the specified constraints).
Additionally, the paper extends the analysis to the case of weakly communicating MDPs, where the transition probabilities between different states may not be uniform. This is a more general setting that encompasses a wider range of practical scenarios.
Critical Analysis
The paper provides a comprehensive exploration of various approaches to Constrained Reinforcement Learning, offering valuable insights and theoretical guarantees. However, there are a few aspects that could be further investigated:
-
Practical Considerations: While the theoretical analysis is robust, the paper does not delve deeply into the practical challenges of implementing these methods in real-world settings. Factors such as computational complexity, sensitivity to hyperparameters, and the impact of approximations or function approximation could be explored in more detail.
-
Empirical Evaluation: The paper primarily focuses on the theoretical aspects and does not include extensive empirical evaluations. Comparing the performance of the proposed methods on a diverse set of benchmark tasks or real-world applications would provide a more comprehensive understanding of their practical effectiveness.
-
Generalization to Other Objectives: The paper concentrates on the average reward objective, but there may be other relevant objectives, such as multi-objective reinforcement learning or non-cumulative objectives. Extending the analysis to these alternative objectives could broaden the applicability of the research.
-
Robustness to Modeling Assumptions: The paper assumes the underlying MDP to be ergodic and weakly communicating. It would be valuable to explore the performance of the proposed methods under more relaxed assumptions or in the presence of adversarial or uncertain environments.
Despite these potential areas for further investigation, the research presented in this paper makes valuable contributions to the field of Constrained Reinforcement Learning and lays a strong theoretical foundation for addressing this important challenge.
Conclusion
This research paper explores various model-based and model-free approaches for Constrained Reinforcement Learning, with a focus on average reward Markov Decision Processes. The findings provide a comprehensive understanding of the strengths and limitations of different strategies, including optimism-based methods, posterior sampling, and primal-dual policy gradient algorithms.
The theoretical guarantees on regret and constraint violation offer valuable insights into the performance of these techniques, while the extension to weakly communicating MDPs broadens the applicability of the research to a wider range of practical scenarios.
Overall, this work advances the state of the art in Constrained Reinforcement Learning and lays a solid foundation for further exploration and development in this important area of sequential decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
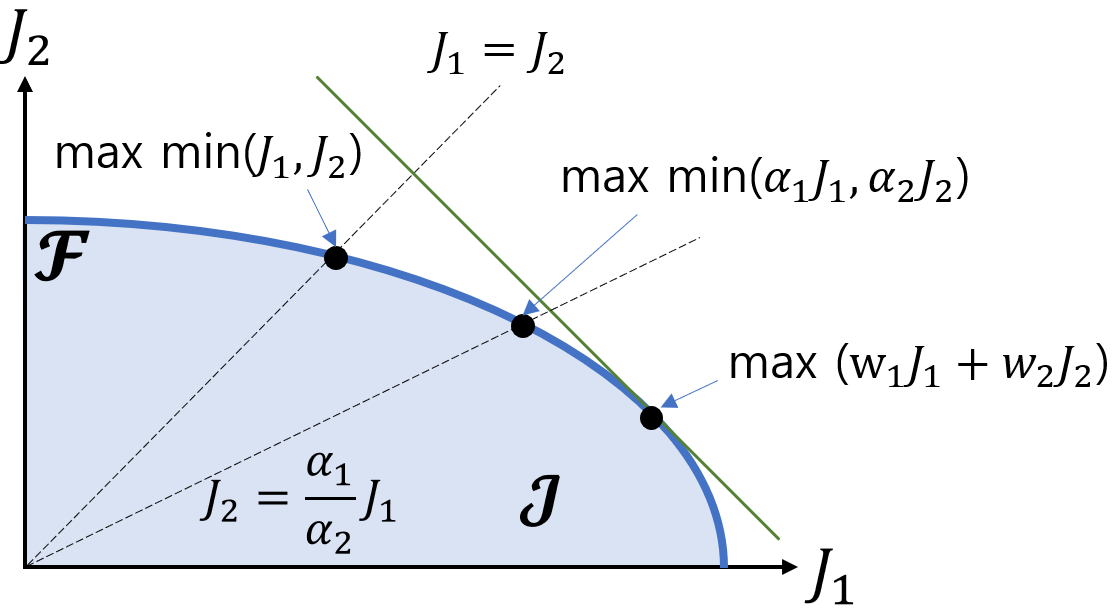
The Max-Min Formulation of Multi-Objective Reinforcement Learning: From Theory to a Model-Free Algorithm
Giseung Park, Woohyeon Byeon, Seongmin Kim, Elad Havakuk, Amir Leshem, Youngchul Sung
0
0
In this paper, we consider multi-objective reinforcement learning, which arises in many real-world problems with multiple optimization goals. We approach the problem with a max-min framework focusing on fairness among the multiple goals and develop a relevant theory and a practical model-free algorithm under the max-min framework. The developed theory provides a theoretical advance in multi-objective reinforcement learning, and the proposed algorithm demonstrates a notable performance improvement over existing baseline methods.
6/13/2024
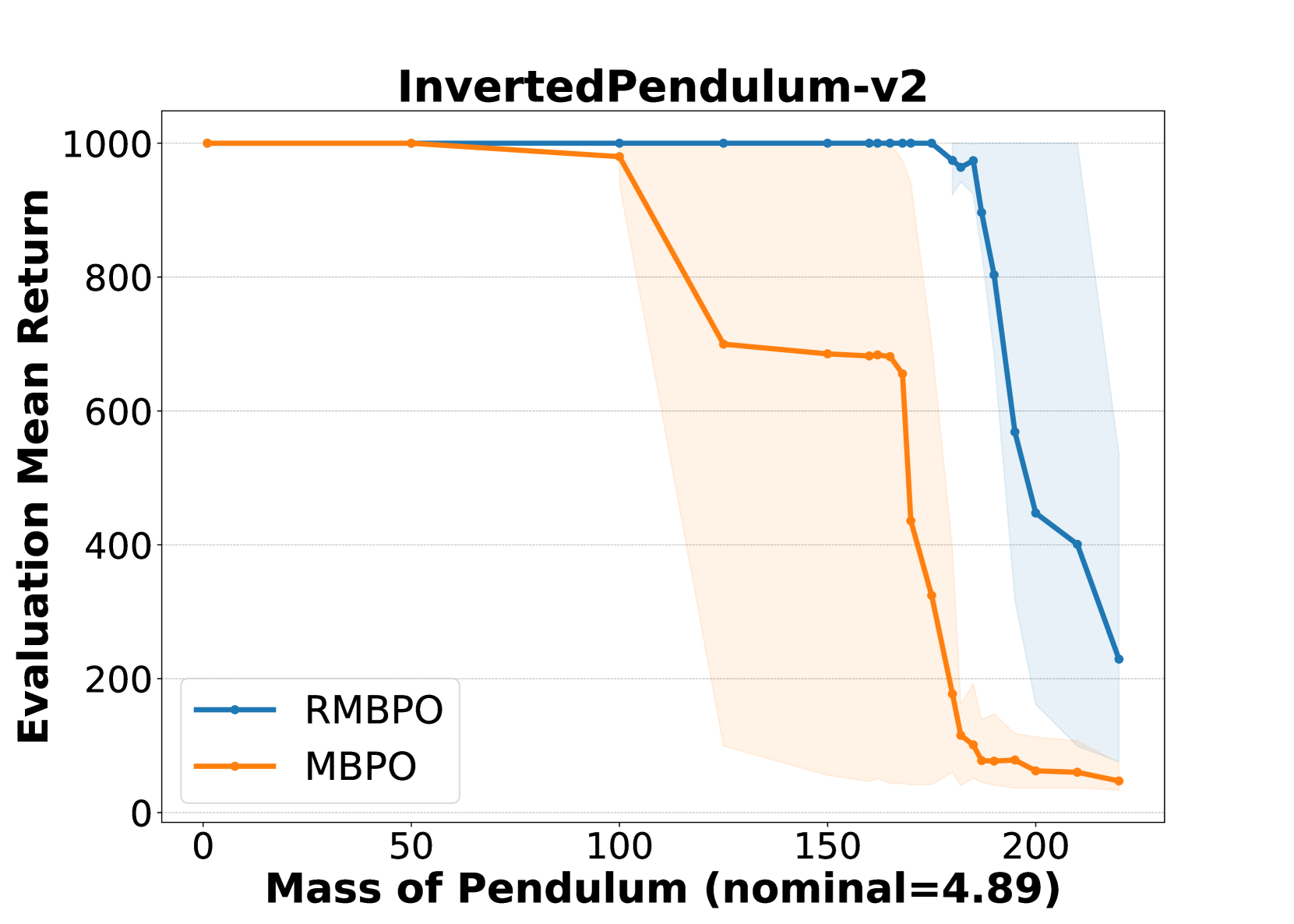
Robust Model-Based Reinforcement Learning with an Adversarial Auxiliary Model
Siemen Herremans, Ali Anwar, Siegfried Mercelis
0
0
Reinforcement learning has demonstrated impressive performance in various challenging problems such as robotics, board games, and classical arcade games. However, its real-world applications can be hindered by the absence of robustness and safety in the learned policies. More specifically, an RL agent that trains in a certain Markov decision process (MDP) often struggles to perform well in nearly identical MDPs. To address this issue, we employ the framework of Robust MDPs (RMDPs) in a model-based setting and introduce a novel learned transition model. Our method specifically incorporates an auxiliary pessimistic model, updated adversarially, to estimate the worst-case MDP within a Kullback-Leibler uncertainty set. In comparison to several existing works, our work does not impose any additional conditions on the training environment, such as the need for a parametric simulator. To test the effectiveness of the proposed pessimistic model in enhancing policy robustness, we integrate it into a practical RL algorithm, called Robust Model-Based Policy Optimization (RMBPO). Our experimental results indicate a notable improvement in policy robustness on high-dimensional MuJoCo control tasks, with the auxiliary model enhancing the performance of the learned policy in distorted MDPs. We further explore the learned deviation between the proposed auxiliary world model and the nominal model, to examine how pessimism is achieved. By learning a pessimistic world model and demonstrating its role in improving policy robustness, our research contributes towards making (model-based) RL more robust.
6/17/2024
🏅
Tackling Decision Processes with Non-Cumulative Objectives using Reinforcement Learning
Maximilian Nagele, Jan Olle, Thomas Fosel, Remmy Zen, Florian Marquardt
0
0
Markov decision processes (MDPs) are used to model a wide variety of applications ranging from game playing over robotics to finance. Their optimal policy typically maximizes the expected sum of rewards given at each step of the decision process. However, a large class of problems does not fit straightforwardly into this framework: Non-cumulative Markov decision processes (NCMDPs), where instead of the expected sum of rewards, the expected value of an arbitrary function of the rewards is maximized. Example functions include the maximum of the rewards or their mean divided by their standard deviation. In this work, we introduce a general mapping of NCMDPs to standard MDPs. This allows all techniques developed to find optimal policies for MDPs, such as reinforcement learning or dynamic programming, to be directly applied to the larger class of NCMDPs. Focusing on reinforcement learning, we show applications in a diverse set of tasks, including classical control, portfolio optimization in finance, and discrete optimization problems. Given our approach, we can improve both final performance and training time compared to relying on standard MDPs.
5/24/2024
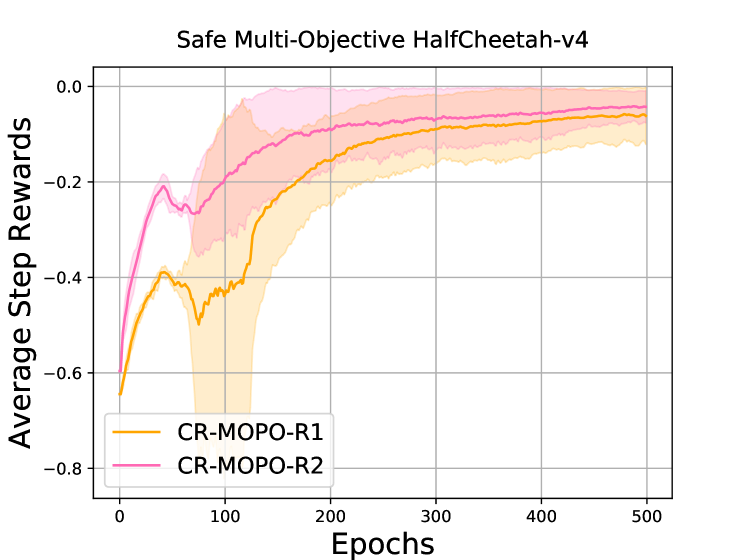
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
0
0
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
5/28/2024