Mean Aggregator Is More Robust Than Robust Aggregators Under Label Poisoning Attacks

0

Sign in to get full access
Overview
- This paper investigates the robustness of different aggregators, such as the mean aggregator and robust aggregators, under label poisoning attacks in machine learning models.
- The researchers find that the mean aggregator, a simple and widely-used approach, is more robust to label poisoning attacks compared to more complex robust aggregators.
- This challenges the conventional wisdom that robust aggregators are more effective at mitigating the impact of adversarial attacks on machine learning models.
Plain English Explanation
In machine learning, models are often trained on data provided by multiple sources or participants. This distributed training process is known as federated learning. However, some of these participants may try to sabotage the model by providing malicious or "poisoned" data, a type of attack called label poisoning.
To combat these attacks, researchers have developed robust aggregators, which are designed to be more resistant to the influence of malicious data. The mean aggregator, a simple technique that averages the contributions from all participants, is often considered less robust.
Surprisingly, this paper finds that the mean aggregator is actually more effective at withstanding label poisoning attacks compared to these more complex robust aggregators. This contradicts the prevailing belief that robust aggregators are better at mitigating the impact of adversarial attacks, as discussed in research on building robust toxicity predictors and evaluating the robustness of event identification models.
The researchers attribute this finding to the ability of the mean aggregator to "average out" the impact of malicious data, whereas robust aggregators may be more susceptible to being "fooled" by the adversarial attacks. This suggests that simplicity can sometimes be a strength when it comes to building resilient machine learning models, even in the face of aggressive network pruning or other adversarial techniques.
Technical Explanation
The paper formulates the label poisoning attack problem in a federated learning setting, where the goal of the attacker is to manipulate the labels of a subset of the training data to degrade the performance of the global model.
The researchers compare the robustness of the mean aggregator, which simply averages the model updates from all participants, to that of several robust aggregators, such as the Krum and Trimmed Mean aggregators. These robust aggregators aim to identify and discard malicious updates, thereby improving the resilience of the global model.
Through extensive experiments on both synthetic and real-world datasets, the paper demonstrates that the mean aggregator surprisingly outperforms the robust aggregators in the presence of label poisoning attacks. The researchers attribute this to the ability of the mean aggregator to "average out" the impact of malicious updates, whereas the robust aggregators may be more susceptible to being "fooled" by the adversarial attacks.
Critical Analysis
The paper provides a valuable contribution to the understanding of federated learning and the robustness of different aggregation techniques under adversarial attacks. However, there are a few limitations and areas for further research:
-
The paper focuses solely on label poisoning attacks and does not consider other types of adversarial attacks, such as data poisoning or model-level attacks. It would be important to evaluate the robustness of the mean aggregator against a broader range of adversarial threats.
-
The experiments are conducted on a limited set of datasets and attack scenarios. Extending the analysis to a wider range of real-world applications and attack settings would strengthen the generalizability of the findings.
-
The paper does not explore the potential reasons why robust aggregators may be more susceptible to label poisoning attacks compared to the mean aggregator. Further investigation into the underlying mechanisms and potential weaknesses of these robust techniques would be valuable.
-
While the paper challenges the conventional wisdom on the superiority of robust aggregators, it does not provide a comprehensive assessment of the trade-offs and considerations in choosing between different aggregation strategies. This could be an area for future research.
Conclusion
This paper presents a surprising finding that challenges the prevailing belief in the machine learning community. It demonstrates that the simple mean aggregator can be more robust to label poisoning attacks compared to more complex robust aggregators, which are designed specifically to mitigate the impact of adversarial data.
This work suggests that simplicity can sometimes be a strength in building resilient machine learning models, even in the face of sophisticated adversarial attacks. The findings have important implications for the design and deployment of federated learning systems, where the choice of aggregation strategy can significantly impact the model's robustness and performance.
The paper's insights encourage further research into the nuances of adversarial robustness and the development of more comprehensive strategies for building secure and reliable machine learning models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mean Aggregator Is More Robust Than Robust Aggregators Under Label Poisoning Attacks
Jie Peng, Weiyu Li, Qing Ling
Robustness to malicious attacks is of paramount importance for distributed learning. Existing works often consider the classical Byzantine attacks model, which assumes that some workers can send arbitrarily malicious messages to the server and disturb the aggregation steps of the distributed learning process. To defend against such worst-case Byzantine attacks, various robust aggregators have been proven effective and much superior to the often-used mean aggregator. In this paper, we show that robust aggregators are too conservative for a class of weak but practical malicious attacks, as known as label poisoning attacks, where the sample labels of some workers are poisoned. Surprisingly, we are able to show that the mean aggregator is more robust than the state-of-the-art robust aggregators in theory, given that the distributed data are sufficiently heterogeneous. In fact, the learning error of the mean aggregator is proven to be optimal in order. Experimental results corroborate our theoretical findings, demonstrating the superiority of the mean aggregator under label poisoning attacks.
Read more4/23/2024
🛠️
0
On the Relevance of Byzantine Robust Optimization Against Data Poisoning
Sadegh Farhadkhani, Rachid Guerraoui, Nirupam Gupta, Rafael Pinot
The success of machine learning (ML) has been intimately linked with the availability of large amounts of data, typically collected from heterogeneous sources and processed on vast networks of computing devices (also called {em workers}). Beyond accuracy, the use of ML in critical domains such as healthcare and autonomous driving calls for robustness against {em data poisoning}and some {em faulty workers}. The problem of {em Byzantine ML} formalizes these robustness issues by considering a distributed ML environment in which workers (storing a portion of the global dataset) can deviate arbitrarily from the prescribed algorithm. Although the problem has attracted a lot of attention from a theoretical point of view, its practical importance for addressing realistic faults (where the behavior of any worker is locally constrained) remains unclear. It has been argued that the seemingly weaker threat model where only workers' local datasets get poisoned is more reasonable. We prove that, while tolerating a wider range of faulty behaviors, Byzantine ML yields solutions that are, in a precise sense, optimal even under the weaker data poisoning threat model. Then, we study a generic data poisoning model wherein some workers have {em fully-poisonous local data}, i.e., their datasets are entirely corruptible, and the remainders have {em partially-poisonous local data}, i.e., only a fraction of their local datasets is corruptible. We prove that Byzantine-robust schemes yield optimal solutions against both these forms of data poisoning, and that the former is more harmful when workers have {em heterogeneous} local data.
Read more5/2/2024
🏷️
0
Attacking Byzantine Robust Aggregation in High Dimensions
Sarthak Choudhary, Aashish Kolluri, Prateek Saxena
Training modern neural networks or models typically requires averaging over a sample of high-dimensional vectors. Poisoning attacks can skew or bias the average vectors used to train the model, forcing the model to learn specific patterns or avoid learning anything useful. Byzantine robust aggregation is a principled algorithmic defense against such biasing. Robust aggregators can bound the maximum bias in computing centrality statistics, such as mean, even when some fraction of inputs are arbitrarily corrupted. Designing such aggregators is challenging when dealing with high dimensions. However, the first polynomial-time algorithms with strong theoretical bounds on the bias have recently been proposed. Their bounds are independent of the number of dimensions, promising a conceptual limit on the power of poisoning attacks in their ongoing arms race against defenses. In this paper, we show a new attack called HIDRA on practical realization of strong defenses which subverts their claim of dimension-independent bias. HIDRA highlights a novel computational bottleneck that has not been a concern of prior information-theoretic analysis. Our experimental evaluation shows that our attacks almost completely destroy the model performance, whereas existing attacks with the same goal fail to have much effect. Our findings leave the arms race between poisoning attacks and provable defenses wide open.
Read more4/22/2024
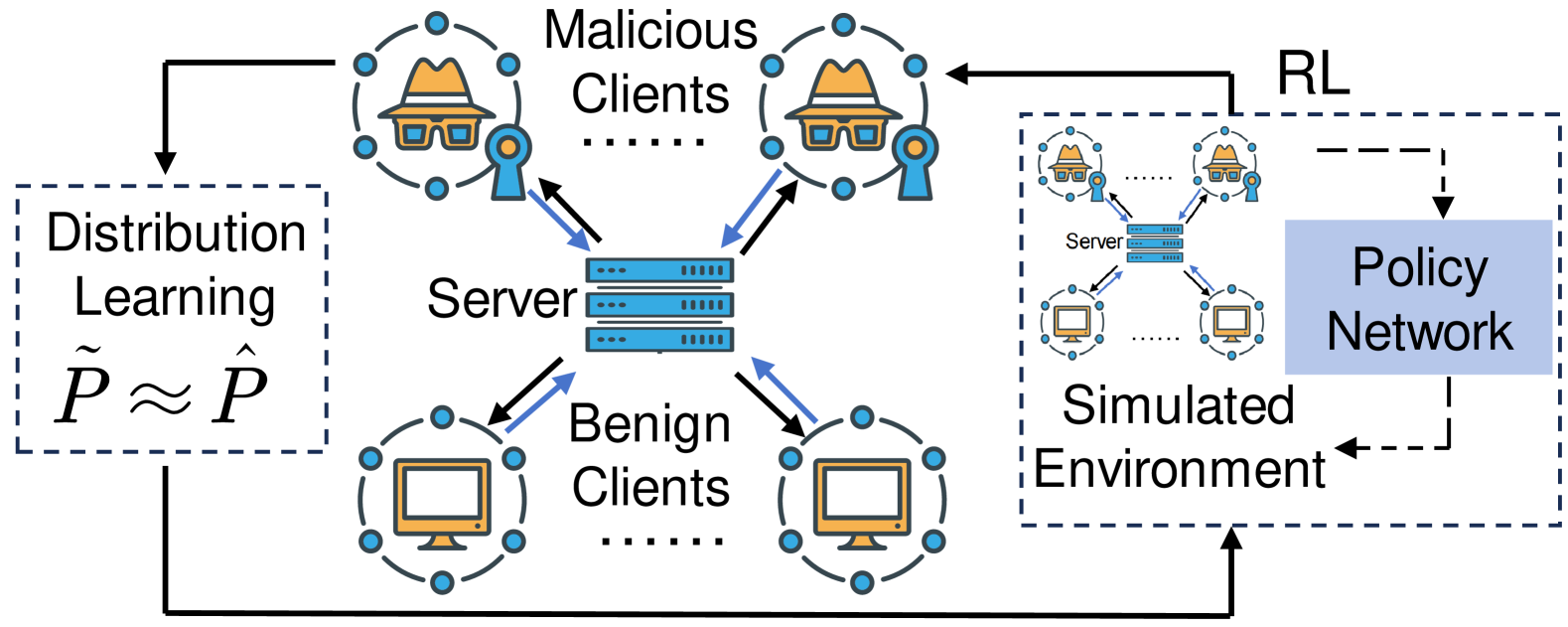
0
Defending Against Sophisticated Poisoning Attacks with RL-based Aggregation in Federated Learning
Yujing Wang, Hainan Zhang, Sijia Wen, Wangjie Qiu, Binghui Guo
Federated learning is highly susceptible to model poisoning attacks, especially those meticulously crafted for servers. Traditional defense methods mainly focus on updating assessments or robust aggregation against manually crafted myopic attacks. When facing advanced attacks, their defense stability is notably insufficient. Therefore, it is imperative to develop adaptive defenses against such advanced poisoning attacks. We find that benign clients exhibit significantly higher data distribution stability than malicious clients in federated learning in both CV and NLP tasks. Therefore, the malicious clients can be recognized by observing the stability of their data distribution. In this paper, we propose AdaAggRL, an RL-based Adaptive Aggregation method, to defend against sophisticated poisoning attacks. Specifically, we first utilize distribution learning to simulate the clients' data distributions. Then, we use the maximum mean discrepancy (MMD) to calculate the pairwise similarity of the current local model data distribution, its historical data distribution, and global model data distribution. Finally, we use policy learning to adaptively determine the aggregation weights based on the above similarities. Experiments on four real-world datasets demonstrate that the proposed defense model significantly outperforms widely adopted defense models for sophisticated attacks.
Read more6/21/2024