UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner

0

Sign in to get full access
Overview
- UniAudio 1.5 is a large language model-driven audio codec that can learn audio tasks with few examples.
- It demonstrates the ability to perform various audio tasks, including audio classification, audio generation, and audio restoration, using only a small number of training examples.
- The research explores the potential of large language models to serve as versatile and flexible audio processing tools.
Plain English Explanation
UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner presents a new approach to audio processing that leverages the power of large language models. Unlike traditional audio codecs that are designed for specific tasks, UniAudio 1.5 is a more versatile system that can learn to perform a wide range of audio-related tasks with just a few examples.
This means that instead of having to train a separate model for each audio task, such as audio classification, audio generation, or audio restoration, UniAudio 1.5 can adapt to these tasks with just a few examples. This makes it a more flexible and efficient tool for audio processing compared to traditional approaches.
Technical Explanation
The researchers behind UniAudio 1.5 explored the idea of using a large language model as the core component of an audio codec. By leveraging the general-purpose understanding and learning capabilities of these models, they aimed to create a system that could adapt to a variety of audio tasks with minimal training data.
The key aspects of the UniAudio 1.5 system include:
- Architecture: UniAudio 1.5 is built around a large language model that serves as the foundation for the audio processing tasks. The model is trained on a diverse dataset of audio and text data to develop a broad understanding of the audio domain.
- Few-shot Learning: The system is designed to quickly adapt to new audio tasks by learning from just a few examples. This is achieved through a combination of techniques, such as prompt engineering and few-shot fine-tuning.
- Versatility: UniAudio 1.5 can be applied to a wide range of audio tasks, including classification, generation, and restoration, demonstrating its flexibility and potential as a general-purpose audio processing tool.
The researchers conducted extensive experiments to evaluate the performance of UniAudio 1.5 on various audio tasks, and the results suggest that this approach can indeed achieve impressive few-shot learning capabilities compared to traditional audio processing methods.
Critical Analysis
The researchers acknowledge several limitations and areas for further exploration in their work. For example, while UniAudio 1.5 demonstrates strong few-shot learning abilities, its performance may still lag behind specialized models trained on large datasets for certain tasks. Additionally, the researchers note that the system's performance can be sensitive to the quality and diversity of the training data used to develop the underlying language model.
It would also be valuable to investigate the interpretability and transparency of the UniAudio 1.5 system, as the inner workings of large language models can sometimes be opaque. Understanding how the system arrives at its decisions and outputs could lead to further improvements and better alignment with user expectations.
Overall, the research presented in UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner represents an exciting step forward in the development of flexible and adaptable audio processing tools. By leveraging the power of large language models, the researchers have demonstrated the potential for a more generalized and efficient approach to audio task learning.
Conclusion
The UniAudio 1.5 system showcases the promise of using large language models as the foundation for audio processing tasks. By enabling few-shot learning, the researchers have created a more versatile and adaptable tool that can tackle a wide range of audio-related challenges with minimal training data.
This research opens up new avenues for exploring the intersection of language models and audio processing, potentially leading to more efficient and flexible audio applications in the future. As language models continue to evolve and improve, the ability to apply their general-purpose understanding to specialized domains like audio could have far-reaching implications for the field of audio technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UniAudio 1.5: Large Language Model-driven Audio Codec is A Few-shot Audio Task Learner
Dongchao Yang, Haohan Guo, Yuanyuan Wang, Rongjie Huang, Xiang Li, Xu Tan, Xixin Wu, Helen Meng
The Large Language models (LLMs) have demonstrated supreme capabilities in text understanding and generation, but cannot be directly applied to cross-modal tasks without fine-tuning. This paper proposes a cross-modal in-context learning approach, empowering the frozen LLMs to achieve multiple audio tasks in a few-shot style without any parameter update. Specifically, we propose a novel and LLMs-driven audio codec model, LLM-Codec, to transfer the audio modality into the textual space, textit{i.e.} representing audio tokens with words or sub-words in the vocabulary of LLMs, while keeping high audio reconstruction quality. The key idea is to reduce the modality heterogeneity between text and audio by compressing the audio modality into a well-trained LLMs token space. Thus, the audio representation can be viewed as a new textit{foreign language}, and LLMs can learn the new textit{foreign language} with several demonstrations. In experiments, we investigate the performance of the proposed approach across multiple audio understanding and generation tasks, textit{e.g.} speech emotion classification, audio classification, text-to-speech generation, speech enhancement, etc. The experimental results demonstrate that the LLMs equipped with the proposed LLM-Codec, named as UniAudio 1.5, prompted by only a few examples, can achieve the expected functions in simple scenarios. It validates the feasibility and effectiveness of the proposed cross-modal in-context learning approach. To facilitate research on few-shot audio task learning and multi-modal LLMs, we have open-sourced the LLM-Codec model.
Read more6/17/2024

0
Improving Audio Codec-based Zero-Shot Text-to-Speech Synthesis with Multi-Modal Context and Large Language Model
Jinlong Xue, Yayue Deng, Yicheng Han, Yingming Gao, Ya Li
Recent advances in large language models (LLMs) and development of audio codecs greatly propel the zero-shot TTS. They can synthesize personalized speech with only a 3-second speech of an unseen speaker as acoustic prompt. However, they only support short speech prompts and cannot leverage longer context information, as required in audiobook and conversational TTS scenarios. In this paper, we introduce a novel audio codec-based TTS model to adapt context features with multiple enhancements. Inspired by the success of Qformer, we propose a multi-modal context-enhanced Qformer (MMCE-Qformer) to utilize additional multi-modal context information. Besides, we adapt a pretrained LLM to leverage its understanding ability to predict semantic tokens, and use a SoundStorm to generate acoustic tokens thereby enhancing audio quality and speaker similarity. The extensive objective and subjective evaluations show that our proposed method outperforms baselines across various context TTS scenarios.
Read more6/7/2024
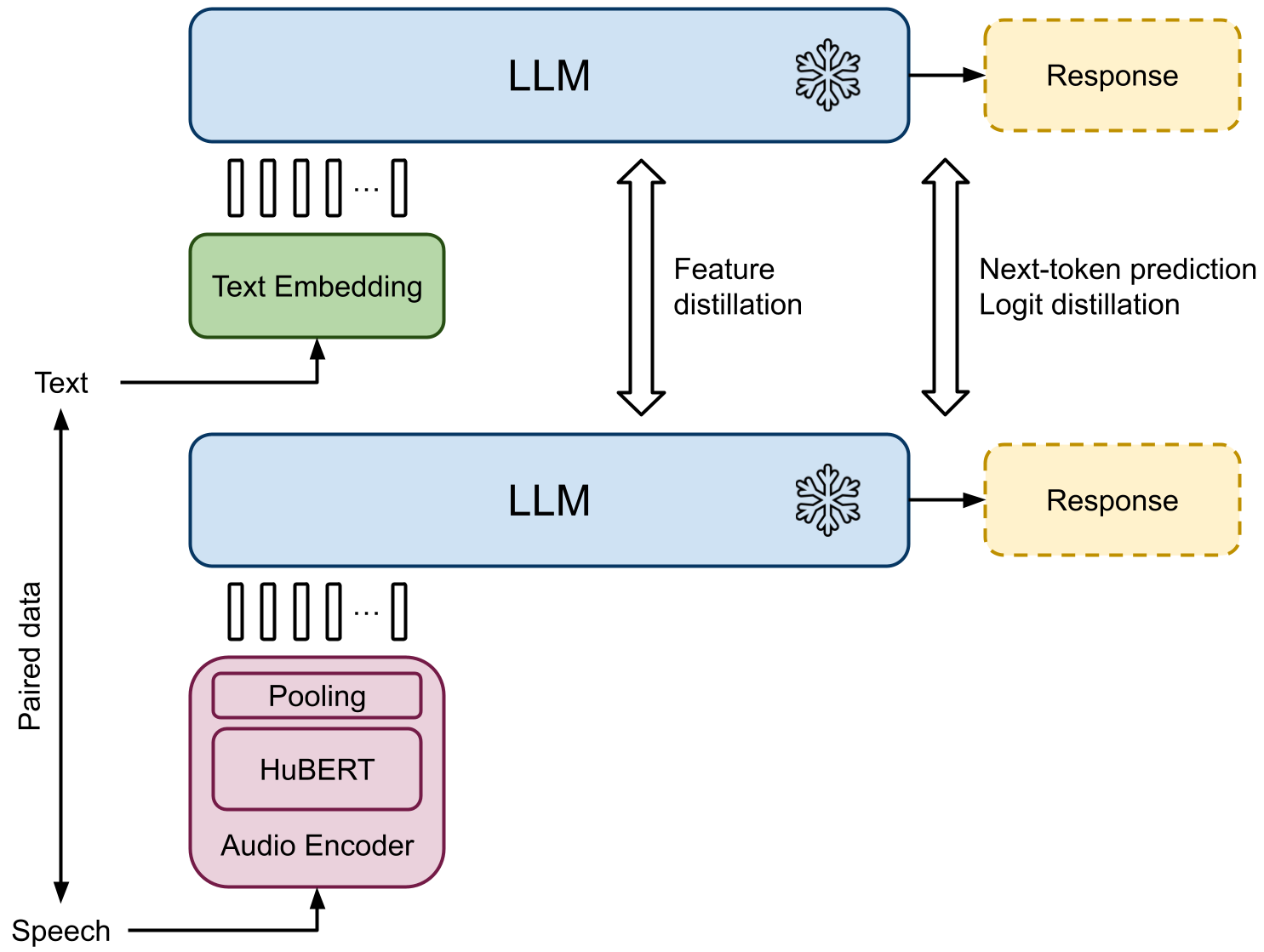
0
Prompting Large Language Models with Audio for General-Purpose Speech Summarization
Wonjune Kang, Deb Roy
In this work, we introduce a framework for speech summarization that leverages the processing and reasoning capabilities of large language models (LLMs). We propose an end-to-end system that combines an instruction-tuned LLM with an audio encoder that converts speech into token representations that the LLM can interpret. Using a dataset with paired speech-text data, the overall system is trained to generate consistent responses to prompts with the same semantic information regardless of the input modality. The resulting framework allows the LLM to process speech inputs in the same way as text, enabling speech summarization by simply prompting the LLM. Unlike prior approaches, our method is able to summarize spoken content from any arbitrary domain, and it can produce summaries in different styles by varying the LLM prompting strategy. Experiments demonstrate that our approach outperforms a cascade baseline of speech recognition followed by LLM text processing.
Read more6/11/2024

0
Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding
Jizhong Liu, Gang Li, Junbo Zhang, Heinrich Dinkel, Yongqing Wang, Zhiyong Yan, Yujun Wang, Bin Wang
Automated audio captioning (AAC) is an audio-to-text task to describe audio contents in natural language. Recently, the advancements in large language models (LLMs), with improvements in training approaches for audio encoders, have opened up possibilities for improving AAC. Thus, we explore enhancing AAC from three aspects: 1) a pre-trained audio encoder via consistent ensemble distillation (CED) is used to improve the effectivity of acoustic tokens, with a querying transformer (Q-Former) bridging the modality gap to LLM and compress acoustic tokens; 2) we investigate the advantages of using a Llama 2 with 7B parameters as the decoder; 3) another pre-trained LLM corrects text errors caused by insufficient training data and annotation ambiguities. Both the audio encoder and text decoder are optimized by low-rank adaptation (LoRA). Experiments show that each of these enhancements is effective. Our method obtains a 33.0 SPIDEr-FL score, outperforming the winner of DCASE 2023 Task 6A.
Read more6/26/2024