Membership Inference Attacks Against In-Context Learning

0

Sign in to get full access
Overview
- Membership inference attacks are a type of privacy attack that aim to determine whether a particular data point was used to train a machine learning model.
- This paper investigates the effectiveness of membership inference attacks against in-context learning models, which are a class of large language models that can perform a variety of tasks by conditioning on appropriate contexts.
- The researchers find that in-context learning models are vulnerable to these attacks, even when trained on relatively small datasets.
- They propose several countermeasures to mitigate the risk of membership inference attacks in in-context learning.
Plain English Explanation
In-context learning models are a type of language model that can perform different tasks by using relevant contextual information. For example, an in-context learning model could be used for both writing an article and answering math questions, depending on the context it is given.
However, the researchers found that these in-context learning models can be vulnerable to membership inference attacks. Membership inference attacks try to determine whether a particular piece of data was used to train a machine learning model. This can be a privacy concern, as the data used to train models may contain sensitive or personal information.
The researchers discovered that even in-context learning models trained on relatively small datasets can be susceptible to these attacks. They propose several ways to help protect against membership inference attacks, such as differential privacy techniques or adversarial training methods.
Technical Explanation
The paper examines the vulnerability of in-context learning models to membership inference attacks. In-context learning is a paradigm where a single model can be used to perform a variety of tasks by conditioning on appropriate contextual information. The researchers investigate whether these models are susceptible to membership inference attacks, which aim to determine whether a particular data point was used to train a machine learning model.
The researchers conducted experiments on several in-context learning models, including GPT-3 and other large language models. They found that these models can be vulnerable to membership inference attacks, even when trained on relatively small datasets. The attacks were effective at identifying members of the training set with high accuracy.
To mitigate this risk, the researchers propose several countermeasures, including the use of differential privacy techniques and adversarial training methods. These approaches aim to reduce the amount of information about the training data that is leaked by the model, making it more difficult for attackers to infer membership.
Critical Analysis
The research presented in this paper highlights an important privacy concern for in-context learning models, which are becoming increasingly prevalent in the field of natural language processing. The finding that even models trained on small datasets can be vulnerable to membership inference attacks is concerning, as it suggests that the privacy of individuals whose data is used to train these models may be at risk.
One limitation of the study is that it focuses primarily on the technical aspects of the attacks and countermeasures, without delving into the broader societal implications. It would be valuable to explore how these privacy issues may impact individuals, organizations, and society as a whole, and to consider the ethical considerations around the use of in-context learning models.
Additionally, the paper does not address the potential for dataset inference attacks, which aim to determine the specific datasets used to train a model. This is another important privacy concern that deserves further investigation.
Conclusion
This paper makes an important contribution to the understanding of privacy risks associated with in-context learning models. By demonstrating the vulnerability of these models to membership inference attacks, the researchers have highlighted the need for robust privacy-preserving techniques in the development and deployment of large language models.
The proposed countermeasures, such as differential privacy and adversarial training, offer promising avenues for mitigating these privacy risks. However, further research is needed to fully address the broader societal implications and to explore other types of privacy attacks that may threaten the use of in-context learning models in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Membership Inference Attacks Against In-Context Learning
Rui Wen, Zheng Li, Michael Backes, Yang Zhang
Adapting Large Language Models (LLMs) to specific tasks introduces concerns about computational efficiency, prompting an exploration of efficient methods such as In-Context Learning (ICL). However, the vulnerability of ICL to privacy attacks under realistic assumptions remains largely unexplored. In this work, we present the first membership inference attack tailored for ICL, relying solely on generated texts without their associated probabilities. We propose four attack strategies tailored to various constrained scenarios and conduct extensive experiments on four popular large language models. Empirical results show that our attacks can accurately determine membership status in most cases, e.g., 95% accuracy advantage against LLaMA, indicating that the associated risks are much higher than those shown by existing probability-based attacks. Additionally, we propose a hybrid attack that synthesizes the strengths of the aforementioned strategies, achieving an accuracy advantage of over 95% in most cases. Furthermore, we investigate three potential defenses targeting data, instruction, and output. Results demonstrate combining defenses from orthogonal dimensions significantly reduces privacy leakage and offers enhanced privacy assurances.
Read more9/4/2024
🤯
0
Improved Membership Inference Attacks Against Language Classification Models
Shlomit Shachor, Natalia Razinkov, Abigail Goldsteen
Artificial intelligence systems are prevalent in everyday life, with use cases in retail, manufacturing, health, and many other fields. With the rise in AI adoption, associated risks have been identified, including privacy risks to the people whose data was used to train models. Assessing the privacy risks of machine learning models is crucial to enabling knowledgeable decisions on whether to use, deploy, or share a model. A common approach to privacy risk assessment is to run one or more known attacks against the model and measure their success rate. We present a novel framework for running membership inference attacks against classification models. Our framework takes advantage of the ensemble method, generating many specialized attack models for different subsets of the data. We show that this approach achieves higher accuracy than either a single attack model or an attack model per class label, both on classical and language classification tasks.
Read more7/19/2024
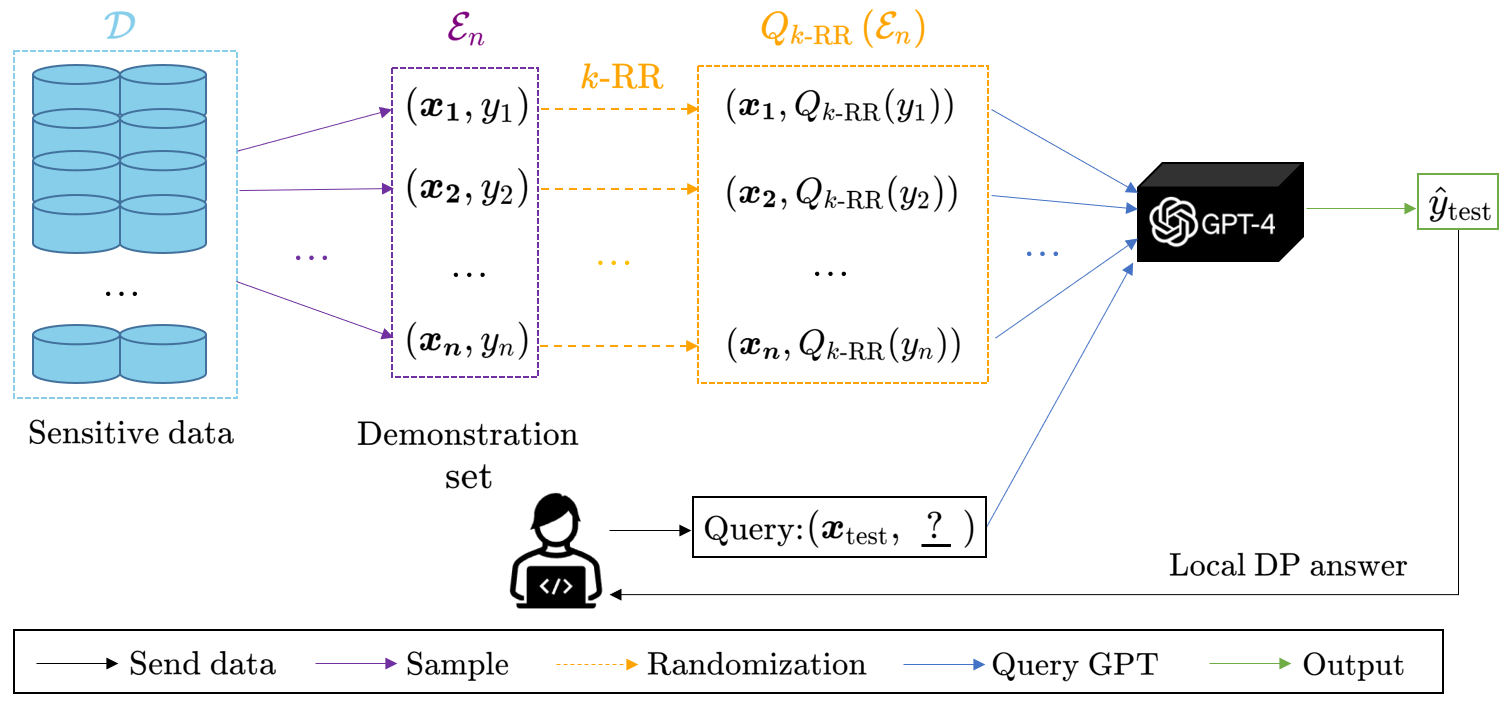
0
Locally Differentially Private In-Context Learning
Chunyan Zheng, Keke Sun, Wenhao Zhao, Haibo Zhou, Lixin Jiang, Shaoyang Song, Chunlai Zhou
Large pretrained language models (LLMs) have shown surprising In-Context Learning (ICL) ability. An important application in deploying large language models is to augment LLMs with a private database for some specific task. The main problem with this promising commercial use is that LLMs have been shown to memorize their training data and their prompt data are vulnerable to membership inference attacks (MIA) and prompt leaking attacks. In order to deal with this problem, we treat LLMs as untrusted in privacy and propose a locally differentially private framework of in-context learning(LDP-ICL) in the settings where labels are sensitive. Considering the mechanisms of in-context learning in Transformers by gradient descent, we provide an analysis of the trade-off between privacy and utility in such LDP-ICL for classification. Moreover, we apply LDP-ICL to the discrete distribution estimation problem. In the end, we perform several experiments to demonstrate our analysis results.
Read more5/9/2024
💬
0
Hijacking Large Language Models via Adversarial In-Context Learning
Yao Qiang, Xiangyu Zhou, Dongxiao Zhu
In-context learning (ICL) has emerged as a powerful paradigm leveraging LLMs for specific downstream tasks by utilizing labeled examples as demonstrations (demos) in the precondition prompts. Despite its promising performance, ICL suffers from instability with the choice and arrangement of examples. Additionally, crafted adversarial attacks pose a notable threat to the robustness of ICL. However, existing attacks are either easy to detect, rely on external models, or lack specificity towards ICL. This work introduces a novel transferable attack against ICL to address these issues, aiming to hijack LLMs to generate the target response or jailbreak. Our hijacking attack leverages a gradient-based prompt search method to learn and append imperceptible adversarial suffixes to the in-context demos without directly contaminating the user queries. Comprehensive experimental results across different generation and jailbreaking tasks highlight the effectiveness of our hijacking attack, resulting in distracted attention towards adversarial tokens and consequently leading to unwanted target outputs. We also propose a defense strategy against hijacking attacks through the use of extra clean demos, which enhances the robustness of LLMs during ICL. Broadly, this work reveals the significant security vulnerabilities of LLMs and emphasizes the necessity for in-depth studies on their robustness.
Read more6/18/2024