Memorization in Self-Supervised Learning Improves Downstream Generalization

0

Sign in to get full access
Overview
- This paper investigates the role of memorization in self-supervised learning (SSL) and its impact on downstream task performance.
- The researchers explore how the ability to memorize training data affects the generalization capabilities of SSL models.
- They conduct experiments to understand the trade-offs between memorization and generalization in SSL, and provide insights into how this balance can be optimized.
Plain English Explanation
Self-supervised learning (SSL) is a machine learning technique that allows models to learn useful representations from unlabeled data, without the need for manual annotations. This can be particularly helpful in domains where labeled data is scarce or expensive to obtain.
However, a key challenge with SSL is finding the right balance between a model's ability to memorize the training data and its ability to generalize to new, unseen data. On one hand, memorization can help the model capture important details and patterns in the training data. But on the other hand, excessive memorization can lead to overfitting, where the model performs well on the training data but fails to generalize to new examples.
The researchers in this paper set out to explore this trade-off in depth. They conducted experiments to understand how the degree of memorization in SSL models affects their performance on downstream tasks, which are the real-world applications that the models are ultimately used for.
The results of their experiments provide valuable insights. They found that a moderate level of memorization can actually improve a model's generalization capabilities, as it helps the model learn more robust and transferable representations. However, if the model memorizes too much, its performance on downstream tasks can suffer.
These findings have important implications for the design and optimization of SSL systems. They suggest that researchers and developers should carefully consider the balance between memorization and generalization when training SSL models, in order to maximize their performance and real-world applicability.
Technical Explanation
The paper investigates the role of memorization in self-supervised learning (SSL) and its impact on downstream task performance. The researchers conduct a series of experiments to understand the trade-offs between memorization and generalization in SSL models.
The key experiment involves training SSL models with varying degrees of memorization, achieved by controlling the model capacity and the amount of training data. The researchers then evaluate the models' performance on a range of downstream tasks, including image classification, object detection, and semantic segmentation.
The results show that a moderate level of memorization can actually improve a model's generalization capabilities, as it helps the model learn more robust and transferable representations. However, if the model memorizes too much, its performance on downstream tasks can suffer.
The researchers provide several possible explanations for this phenomenon. One is that a moderate level of memorization forces the model to learn more general and transferable features, rather than simply memorizing the training data. Additionally, the act of memorizing certain training examples may help the model learn better representations of more common patterns and structures in the data.
The paper also explores the relationship between the type of SSL pretext task and the degree of memorization. They find that certain pretext tasks, such as image rotation prediction, encourage more memorization than others, such as contrastive learning.
Overall, the paper makes an important contribution to the understanding of memorization in SSL, and provides guidance for how to optimize the balance between memorization and generalization in the design of SSL systems.
Critical Analysis
The paper provides valuable insights into the role of memorization in self-supervised learning, but there are a few limitations and areas for further research:
-
The experiments are conducted on relatively simple datasets and tasks, so it's unclear how well the findings would scale to more complex, real-world scenarios. link to "Empirical Study into Clustering Unseen Datasets with Self-Supervised Representations"
-
The paper does not explore the potential impact of different architectural choices or training techniques on the memorization-generalization trade-off. link to "Improving Algorithm-Model-Data Efficiency in Self-Supervised Learning"
-
The analysis is focused on the downstream task performance, but does not consider other important factors, such as the efficiency of the SSL pretraining process or the model's performance on the pretext task itself. link to "Self-Supervised Visual Learning in the Low-Data Regime"
-
The paper does not provide a comprehensive survey of the existing literature on memorization in deep learning. link to "Memorization in Deep Learning: A Survey"
Despite these limitations, the paper represents an important step forward in understanding the role of memorization in self-supervised learning. The findings presented here can inform the development of more effective and robust SSL systems, which could have significant implications for a wide range of applications.
Conclusion
This paper provides valuable insights into the role of memorization in self-supervised learning and its impact on downstream task performance. The researchers demonstrate that a moderate level of memorization can actually improve a model's generalization capabilities, as it helps the model learn more robust and transferable representations.
These findings have important implications for the design and optimization of SSL systems. They suggest that researchers and developers should carefully consider the balance between memorization and generalization when training SSL models, in order to maximize their performance and real-world applicability.
While the paper has some limitations, it represents an important contribution to the understanding of memorization in deep learning, and lays the groundwork for future research in this area. As the field of self-supervised learning continues to evolve, these insights will be crucial for developing more effective and versatile AI systems that can deliver real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Memorization in Self-Supervised Learning Improves Downstream Generalization
Wenhao Wang, Muhammad Ahmad Kaleem, Adam Dziedzic, Michael Backes, Nicolas Papernot, Franziska Boenisch
Self-supervised learning (SSL) has recently received significant attention due to its ability to train high-performance encoders purely on unlabeled data-often scraped from the internet. This data can still be sensitive and empirical evidence suggests that SSL encoders memorize private information of their training data and can disclose them at inference time. Since existing theoretical definitions of memorization from supervised learning rely on labels, they do not transfer to SSL. To address this gap, we propose SSLMem, a framework for defining memorization within SSL. Our definition compares the difference in alignment of representations for data points and their augmented views returned by both encoders that were trained on these data points and encoders that were not. Through comprehensive empirical analysis on diverse encoder architectures and datasets we highlight that even though SSL relies on large datasets and strong augmentations-both known in supervised learning as regularization techniques that reduce overfitting-still significant fractions of training data points experience high memorization. Through our empirical results, we show that this memorization is essential for encoders to achieve higher generalization performance on different downstream tasks.
Read more6/19/2024

0
Learning from Memory: Non-Parametric Memory Augmented Self-Supervised Learning of Visual Features
Thalles Silva, Helio Pedrini, Ad'in Ram'irez Rivera
This paper introduces a novel approach to improving the training stability of self-supervised learning (SSL) methods by leveraging a non-parametric memory of seen concepts. The proposed method involves augmenting a neural network with a memory component to stochastically compare current image views with previously encountered concepts. Additionally, we introduce stochastic memory blocks to regularize training and enforce consistency between image views. We extensively benchmark our method on many vision tasks, such as linear probing, transfer learning, low-shot classification, and image retrieval on many datasets. The experimental results consolidate the effectiveness of the proposed approach in achieving stable SSL training without additional regularizers while learning highly transferable representations and requiring less computing time and resources.
Read more7/26/2024
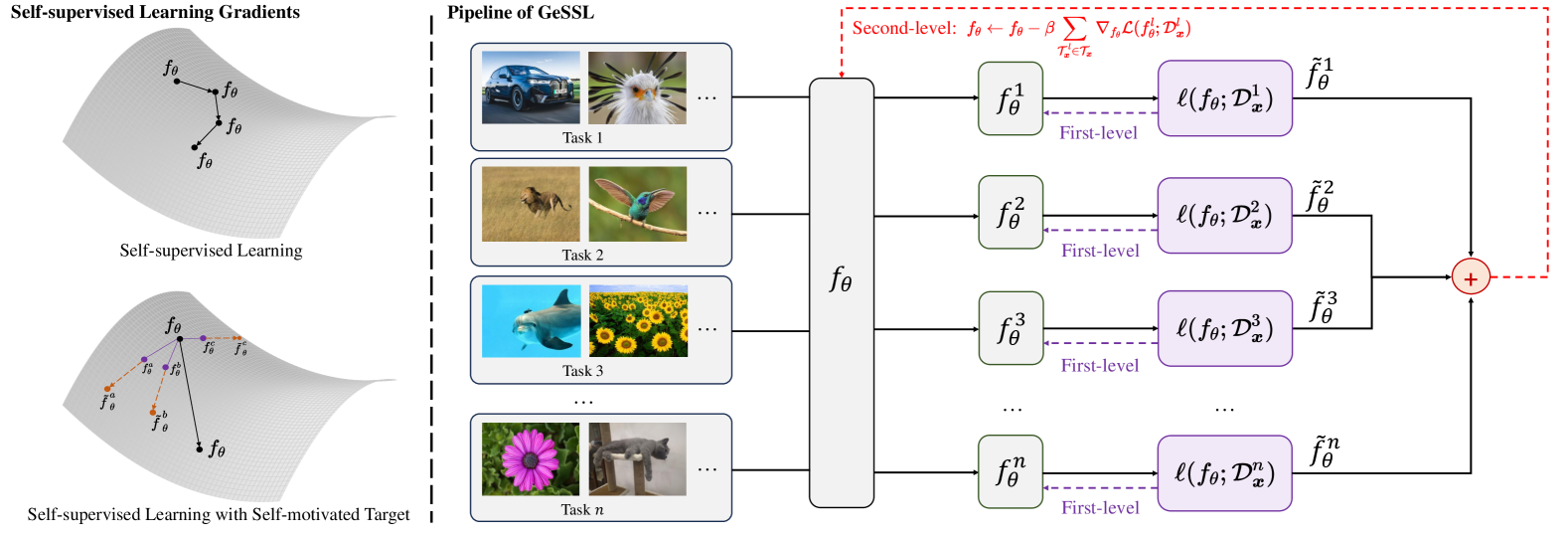
0
Explicitly Modeling Generality into Self-Supervised Learning
Jingyao Wang, Wenwen Qiang, Zeen Song, Lingyu Si, Jiangmeng Li, Changwen Zheng, Bing Su
The goal of universality in self-supervised learning (SSL) is to learn universal representations from unlabeled data and achieve excellent performance on all samples and tasks. However, these methods lack explicit modeling of the universality in the learning objective, and the related theoretical understanding remains limited. This may cause models to overfit in data-scarce situations and generalize poorly in real life. To address these issues, we provide a theoretical definition of universality in SSL, which constrains both the learning and evaluation universality of the SSL models from the perspective of discriminability, transferability, and generalization. Then, we propose a $sigma$-measurement to help quantify the score of one SSL model's universality. Based on the definition and measurement, we propose a general SSL framework, called GeSSL, to explicitly model universality into SSL. It introduces a self-motivated target based on $sigma$-measurement, which enables the model to find the optimal update direction towards universality. Extensive theoretical and empirical evaluations demonstrate the superior performance of GeSSL.
Read more5/24/2024

0
Less Forgetting for Better Generalization: Exploring Continual-learning Fine-tuning Methods for Speech Self-supervised Representations
Salah Zaiem, Titouan Parcollet, Slim Essid
Despite being trained on massive and diverse datasets, speech self-supervised encoders are generally used for downstream purposes as mere frozen feature extractors or model initializers before fine-tuning. The former severely limits the exploitation of large encoders, while the latter hurts the robustness acquired during pretraining, especially in low-resource scenarios. This work explores middle-ground solutions, conjecturing that reducing the forgetting of the self-supervised task during the downstream fine-tuning leads to better generalization. To prove this, focusing on speech recognition, we benchmark different continual-learning approaches during fine-tuning and show that they improve both in-domain and out-of-domain generalization abilities. Relative performance gains reach 15.7% and 22.5% with XLSR used as the encoder on two English and Danish speech recognition tasks. Further probing experiments show that these gains are indeed linked to less forgetting.
Read more7/2/2024